Generative Models 1: VAE
VAE 全称是 Variational AutoEncoder,它是针对普通 AutoEncoders 的改进版本。
1. 背景和初衷 Background
参考:
- 这是讲解 GAN 的原理的,开始部分引入了 VAE 的一些原理介绍:https://towardsdatascience.com/a-wizards-guide-to-adversarial-autoencoders-part-2-exploring-latent-space-with-adversarial-2d53a6f8a4f9
- 博客文章,给出了很多直观的例子以及有用的链接:Variational autoencoders.
- 博客:https://towardsdatascience.com/intuitively-understanding-variational-autoencoders-1bfe67eb5daf
- Tutorial on Variational Autoencoders:https://arxiv.org/pdf/1606.05908.pdf
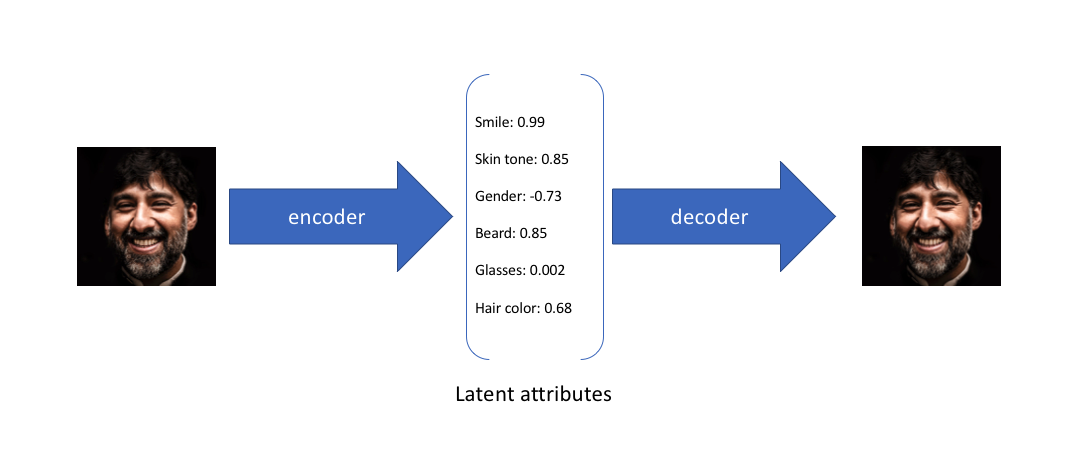
首先用例子来介绍一下 VAE 的初衷。回顾一下普通的 AutoEncoders,如下面的例子,Encoder 可以把输入图片编码成 latent code。一种”理想”的 latent code 应该是能够表示这张图片的核心属性,其中每个值就表达其中一个属性。例如下图中列出的和 Smile, Skin, Gender, Beard, Glasses, Hair Color 等。这些属性值又会通过 decoder 来还原出原始图片。
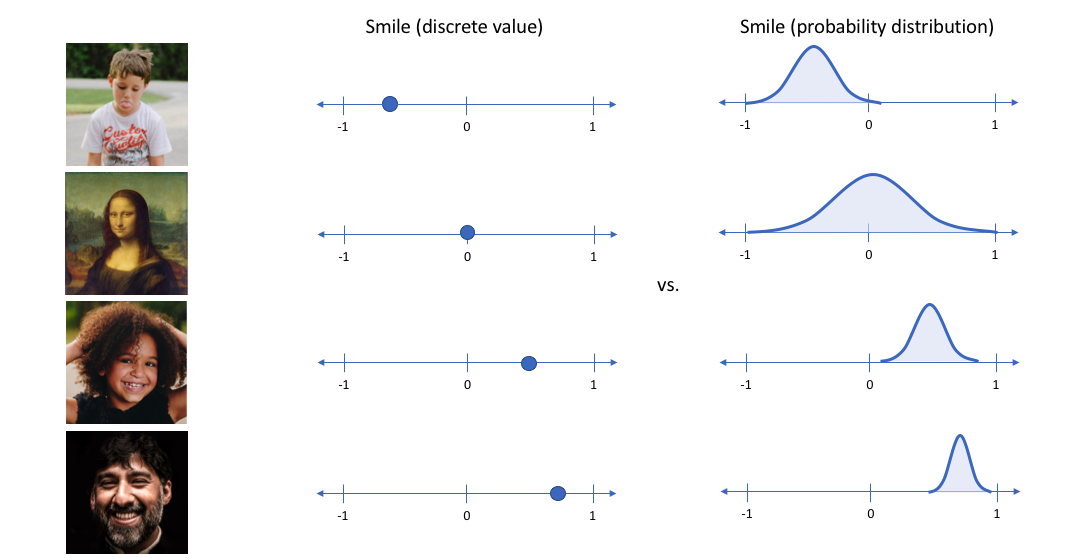
上图中我们是用一个固定的值来记录一种属性。但是,通常情况下,对于一个属性,我们更倾向于使用一个范围的值来表示它,而不是单独的一个值。举例来说,对于 Smile 属性值,不同的原始图片显然应该对应不同的值,这些值应该是符合某种概率分布才比较合理。如下图:
如果使用一个范围的值来表达 latent code 中的每个属性,那么 decoder 做的就是从 latent code 的分布中采样出 latent vector,然后再进行还原。
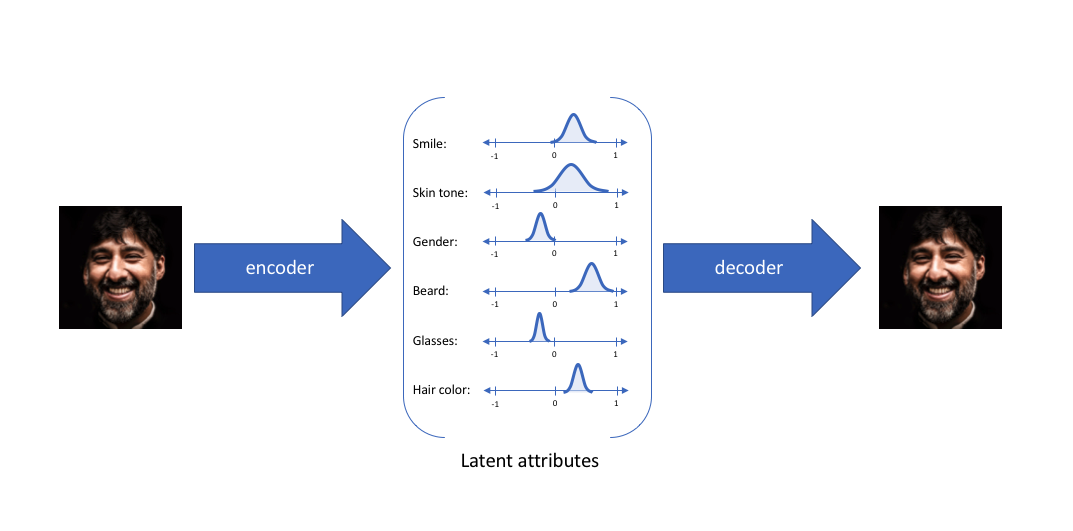
因此,我们期待的 Encoder 应该能够还原一个服从某种分布要求(例如高斯分布)的 Latent distributions,这样才能更好的对输入数据进行区分,并且更可控的进行重建。
如果上面的例子不够直观,可以再看一个例子。下图中给出了 AutoEncoders 的 Encoder 在 MNIST 数据集中得到的一个 Latent code 的分布(当然,再跑一次训练或许分布又会不同):
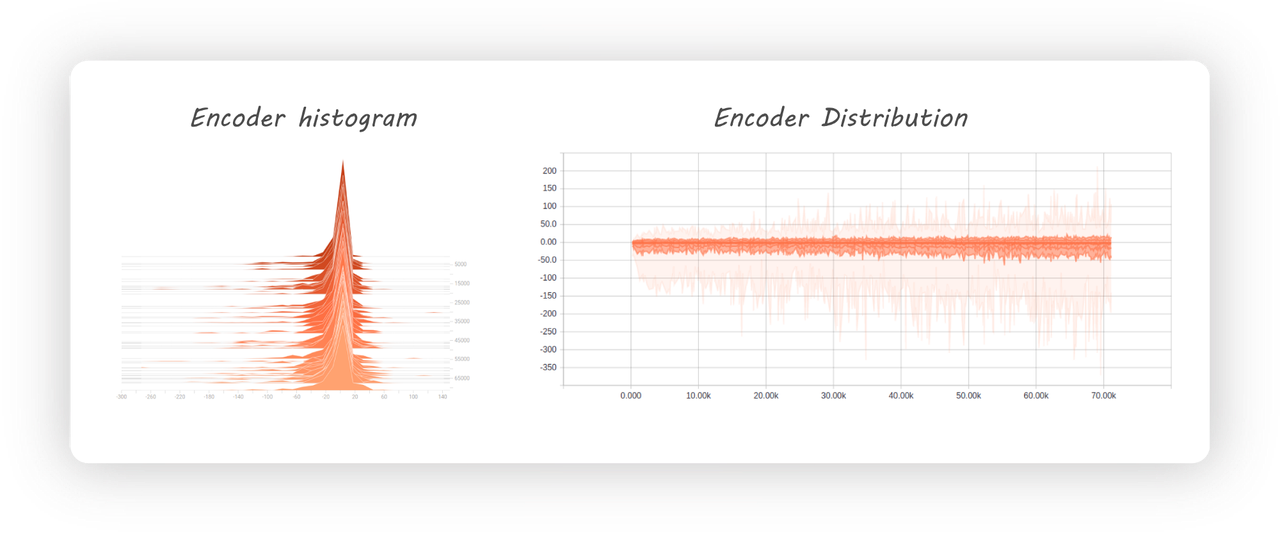
右图可以看出,这个分布初始一小段时间还大概是以 0 为中心,但已经明显能看出负数值要多一些了。随着训练持续下去,分布越来越向负数方向偏移。左图给出了分布的 histogram,可以看出,明显负数的数值要多很多,而且整个分布过于集中在负数值的一个很小的区域,使得整个分布区间中出现了很大的 gap。 那么,这种分布的问题在哪里?如果 latent codes 的分布过于集中且不平均,使得有很大的 gap,那么如果给定一个落在 gap 中的输入,其 decoder 很可能会重建出一个 weird result。另外一个发现是,通常我们希望是,比较类似的输入数据的 latent codes 的分布最好也更接近,类似一个聚类的效果,而全部数据的 latent codes 分布则最好是能够占据整个空间。如下图:
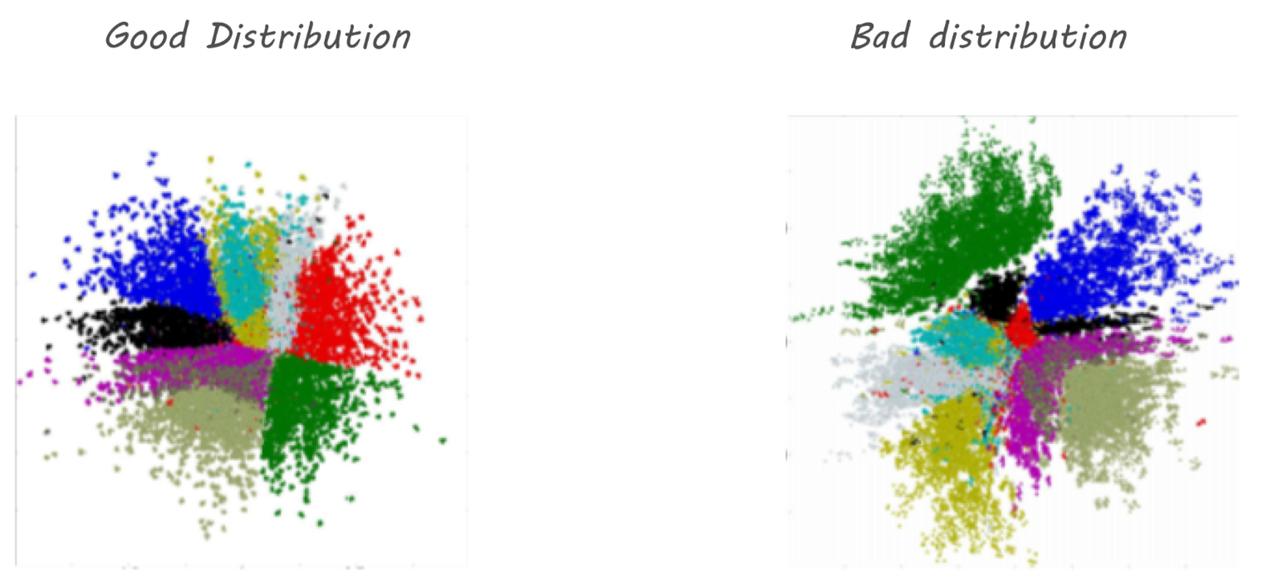
因此,我们希望得到的 latent codes 不但能够满足重建的需求(即,decoders 还原出的数据和原始输入数据尽可能相似。这就是普通的 AutoEncoders 能满足的),同时还想使 latent codes 的分布也满足一定的 prior 要求,比如服从正态分布等一个先验分布(这就是 VAE 能满足的了)。这就是 VAE 的初衷和想要解决的问题了。
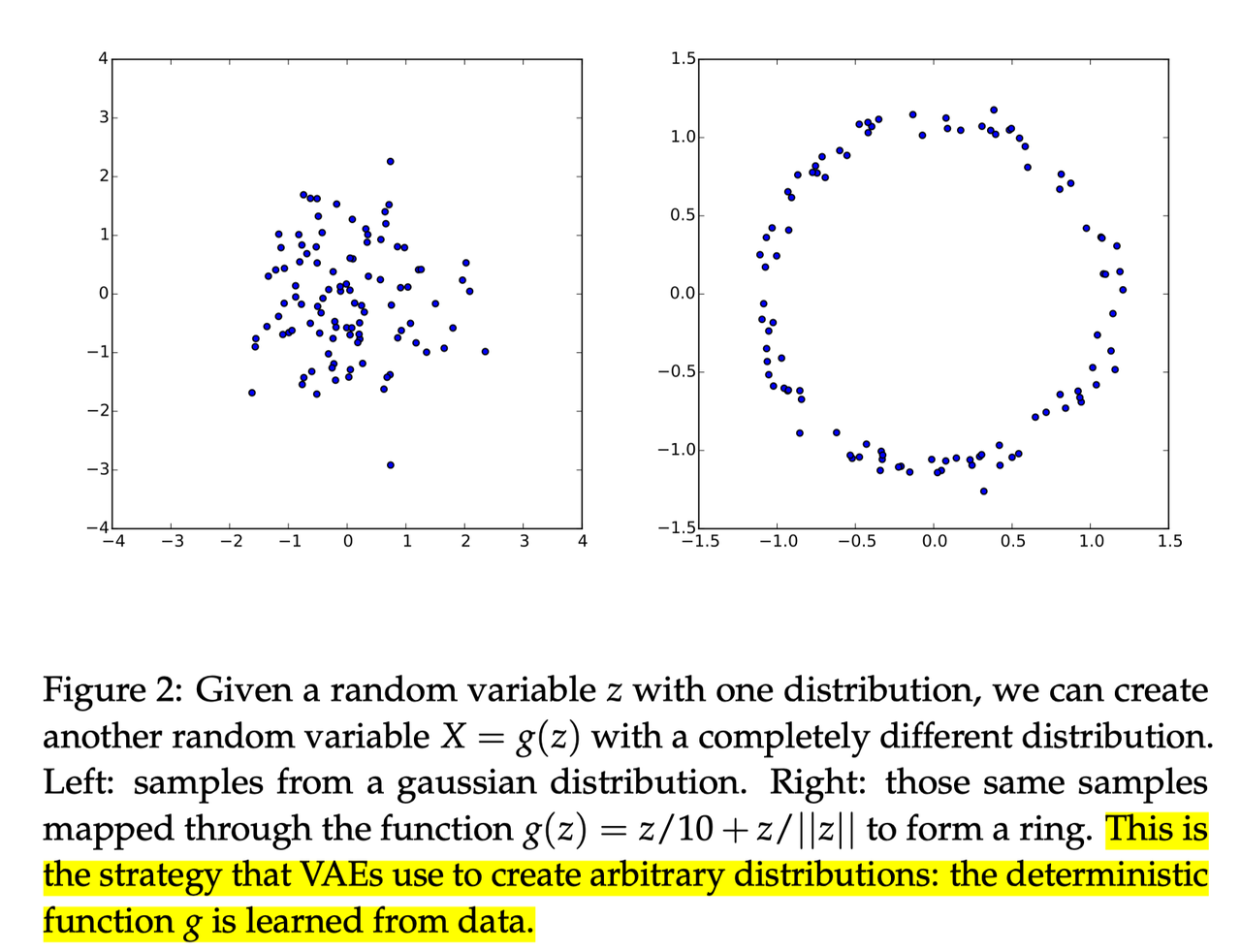
下面是另一个图来说明VAE做的事情是:学习一个映射,可以将一个服从正态分布(左图)的一批数据映射到服从一定规律的另一种分布(右图)。
2. 数学引子 Intuitive in Math
参考:
- Stanford CS 231n 视频教程:https://youtu.be/5WoItGTWV54?t=26m32s。这个视频从打开的位置开始就是 VAE 这一块。该视频对应的课件: http://cs231n.stanford.edu/slides/2021/lecture_12.pdf
和前面介绍的 FVBN 类似的,VAE 同样也想估计这个显式的概率分布 $P(X)$ ,只是出发点不同。
首先的出发点是一个很合理的假设:我们的训练数据 $X$ 是从一个(潜在的、未观测到的)latent representation 得到的,记其为 $Z$(下面图中用了小写,我们这里用大写表示一个变量,小写表示该变量采样的离散值)。即,存在一个 groundtruth latent code Z。例如,如果 X 是图片,Z 是可以用来生成 X 的一些信息,例如属性值、方向信息等等,或者人脸图片对应的头发、表情、年龄等等。如下图以及前面 Section 3.1 中的例子。
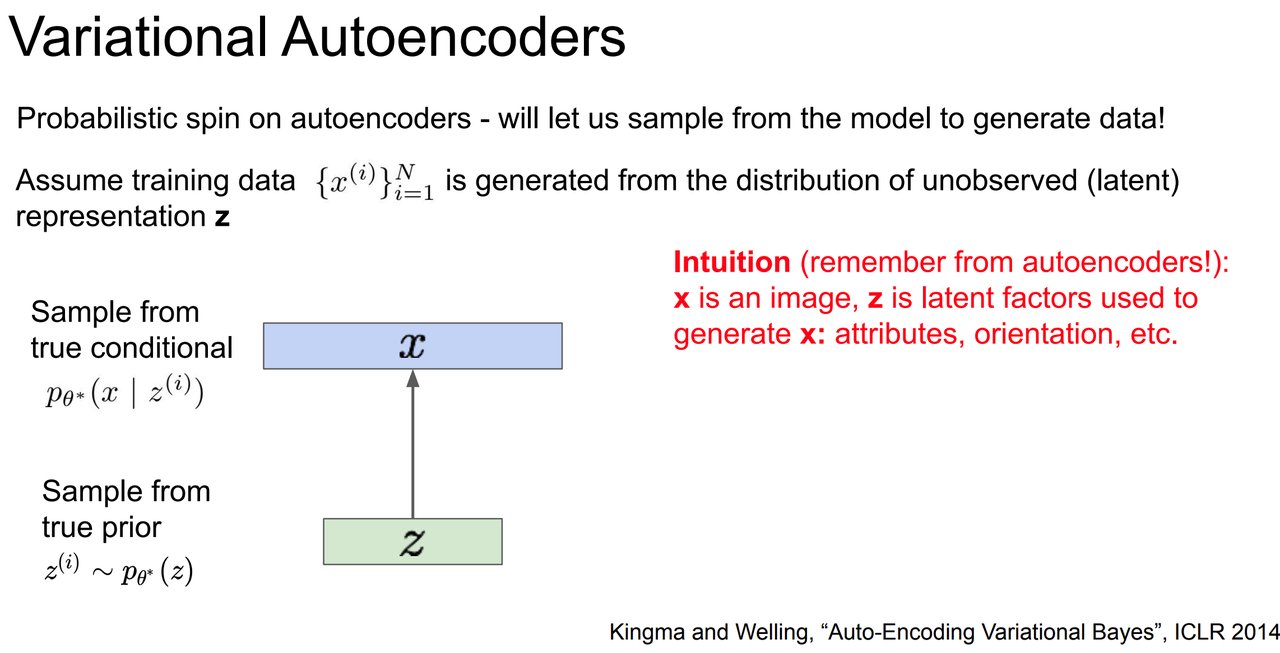
不妨假设 Z 也存在一个先验概率分布 prior distribution $P(Z)$,比如一个合理的分布是 VAE 中提到的 $N\sim (0,1)$ 的高斯分布,比如头发长短、年龄大小、笑容大小,等等。那么,重建 $X$ 的步骤是什么?如下图所示,我们可以设计一个 Decoder,记这个网络的参数为 $\phi$,用它来重建 $X$:首先从 $Z$ 的概率分布中采样得到一批离散值,然后将它们导入 Decoder 输出 $X$。
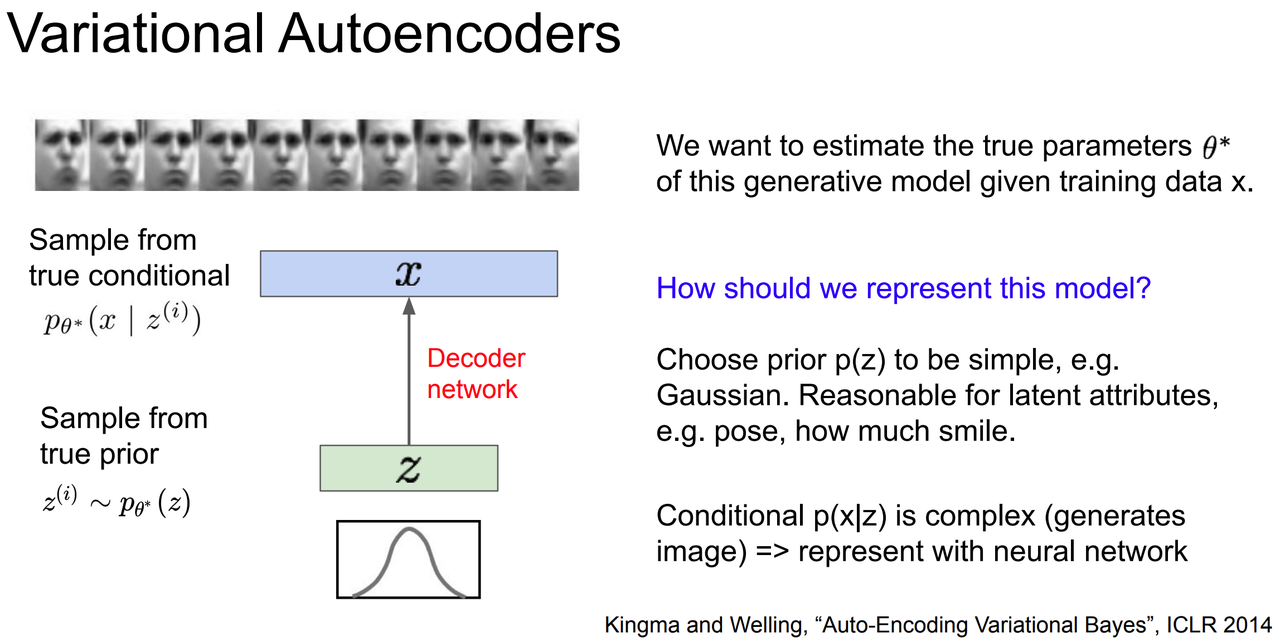
注意,我们的最终目标始终是:重建出最好的 X。那么问题来了:何为最好的 X?用数学语言表示的话,我们的 target 和前面讲述的 FVBN 的 target 一致:最大化 $P(X)$ 这个似然估计,只是此时是在这个 Decoder network $\phi$ 的条件下:
\[P(X)=\int_z P(X,z)dz = \int P(z)P(X\vert z; \phi)dz\]这里的积分是因为, 已知观测值 $X$ 但是不知道 $Z$,为了最大化 $P(X)$,就只能依赖于全部可能的 $z$ 的值做积分了。后面第二项是贝叶斯公式展开。
于是,还有什么问题呢?这里虽然我们已经假定 $P(Z)$ 是高斯分布了,并且可以用 Decoder Network 计算 $P(X\vert z;\phi)$ 了,但是无法计算积分!即:没法确定所有可能的 z。即便使用诸如 Monte Carlo 采样法,采集非常多的 z 来近似,这样的结果依然不可靠。
那换一种思路,用贝叶斯公式如何?使用
\[P(X)=\frac{P(X\vert Z)P(Z)}{P(Z\vert X)}\]回顾一下这里面的几个量:
- $P(X)$:原始数据 $X$ 即测量值的概率分布,通常又被称为证据(Evidence)。我们想要最大化其似然估计。
- $P(X\vert Z)$:这个是 likelihood(似然估计),即已知 X 的情况下,使用 Latent code Z 怎样才能最好的还原重建出 X 。因为我们假设了 Z 的分布就是高斯分布,那么 $P(X\vert Z)$ 可以用 Decoder 来估计。
- $P(Z)$:先验分布,Z 的概率分布,例如 VAE 中直接假设为 $N\sim (0,1)$ 高斯分布;
- $P(Z\vert X)$:后验分布(posterior),已知 Z (的分布)的情况下,通过$X$ 最好的还原出 $Z$ 。这个值如何计算是 VAE 中的重点。
那么,如何计算 $P(Z\vert X)$?实际上,我们可以再设计一个 Encoder,从 $X$ 预测 $Z$ 就行了,记这个 Encoder 为 $Q(Z\vert X;\theta)$,其参数为 $\theta$。然后,VAE 的一个目标是,用 $Q(Z\vert X)$ 来近似 $P(X\vert Z)$.

接下来我们证明,VAE 想要达到的目标最终是 $P(X)$ 的 data likelihood 的一个下限。接下来一章给出推导。
3. VAE 原理推导
参考:
- Stanford CS 231n 视频教程: https://youtu.be/5WoItGTWV54?t=26m32s 这个视频从打开的位置开始就是 VAE 这一块。该视频对应的课件:http://cs231n.stanford.edu/slides/2021/lecture_12.pdf
- 视频教程,来自 Prof. Ali Ghodsi, Lec : Deep Learning, Variational Autoencoder:https://www.youtube.com/watch?v=gErs0bAM63E&ab_channel=DataScienceCourses。非常详细地解释了 VAE 的推导。
- VAE 原始论文:https://arxiv.org/pdf/1312.6114.pdf
- VAE 相关的一个教程论文 Tutorial on Variational Autoencoders:https://arxiv.org/pdf/1606.05908.pdf。这论文很长,但是前半部分很清楚地讲出了 VAE 的出发点和推导。
- 中文教程:变分自编码器介绍、推导及实现。其实就是完全照搬总结了上面 Prof. Ali Ghodsi 的视频教程中的推导,只是它符号用的很混乱且不够详细。
- Multivariate Bernoulli distribution 原始论文:https://arxiv.org/pdf/1206.1874.pdf
- 博客教程:A Beginner’s Guide to Variational Methods: Mean-Field Approximation。这个博客给出了全部的推导过程,还是不错的。
- 博客教程:The Variational Autoencoder。也不错的博客。
- Help Understanding Reconstruction Loss In Variational Autoencoder
- Variational autoencoder: Why reconstruction term is same to square loss?
- KL divergence between two univariate Gaussians
- A Beginner’s Guide to Variational Methods: Mean-Field Approximation:一个博客教程,挺不错的有图文展示了 KL Divergence 和 ELBO 的推导过程
- From Autoencoder to Beta-VAE: Lilian’s blog,大牛的总结总是非常全面和严谨,
- https://www.zhangzhenhu.com/aigc/%E5%8F%98%E5%88%86%E8%87%AA%E7%BC%96%E7%A0%81%E5%99%A8.html:很不错的一个中文博客教程,虽然也是翻译相关英文材料,但是总结的很全面。后续还会引出 Diffusion Models。本文也部分参考了它的推导过程。
3.1 VAE 的推导以及证据下界 ELBO
主要参考 Ref [14] 和 ChatGPT。
根据前面介绍的原理,我们首先已知了 $X$ 的一批观测值 $\mathcal{D}$ ,并且要最大化它的概率 $P(X)$。VAE 出发点是将 $X$ 编码为另一个分布 $Z$,并且再从 $Z$ 来还原出 $X$。那么,最大化 $P(X)$ 就相当于最大化 $X$ 的似然概率,即对于所有的 $Z$ 上的 $P(X)$ 的概率的积分:
\[p(x) = \int_z p(x,z) dz\]接着,在推导前,我们直接定义:
- 记 Decoder 模型的参数是 $\theta$,而 Decoder 就是从 $Z$ 解码到 $X$,即对应的是似然概率 $p_\theta(x\vert z)$
- 记 Encoder 的模型参数是 $\phi$,而 Encoder 是从 $X$ 编码到 $Z$,对应的是似然概率 $q_\phi(z\vert x)$
根据最大似然理论,如果要求解模型的参数,可以通过极大化观测样本的发生概率实现。如果变量 $X,Z$ 都能观测到,如 $\mathcal{D}={(z^{(1)},x^{(1)}),\cdots,(z^{(N)},x^{(N)})}$ 是一个非常大的离散的观测值集合,那么极大化目标函数就变成了
\[\ell(\theta;\mathcal{D}) = \sum_{i=1}^{N} \log p_{\theta}(x^{(i)},z^{(i)})\]这里 $\theta$ 写在下标,表明是在已知这个模型参数条件下的概率。
但问题是我们既不知模型参数 $\theta$,也不知道 $Z$ 的观测样本(即它是隐变量)。即我们的样本集通常是 $\mathcal{D}={x^{(1)},\cdots,x^{(N)}}$。故最大化的概率又要变成了对全部可能的 $Z$ 做积分:
\[\ell(\theta;\mathcal{D}) = \sum_{i=1}^{N} \log p_{\theta}(x^{(i)}) = \sum_{i=1}^{N} \log \int_z p_{\theta}(x^{(i)},z) dz \tag{1}\]
可以看出,这个式子中存在积分,因此对它最大化是很难直接求解的。那么,一个出发点是,是否可以找到一个它的替代品或者近似表达?科学家们确实真的找到了这样一个近似表达的函数,它是上式的一个下界,即永远小于等于它。因为 $P(X)$通常也被称为是证据(Evidence),因此这个下界函数就被称为 Evidence Lower Bound (ELBO) 即证据下界。
接下我们看一下这个下界函数是如何推导出来的。为了公式简洁,我们暂时忽略 Eq. (1) 中的对样本的求和操作,将其变成一个连续变量 $x$,并不影响过程和结论。整个推导过程并不复杂,其实就是利用 Jensen’s Inequality(Jensen 不等式:https://zh.wikipedia.org/wiki/簡森不等式)得到下界函数。
继续 Eq. (1),我们想要最大化 $x$ 的概率(by marginalizing over latent $z$):
\[\ell(\theta;x) = \log p_\theta(x)\]因此有:
\[\begin{aligned} \ell(\theta;x) &= \log p_{\theta}(x)\\ &= \log \int_{z} p_{\theta}(x,z)\\&= \log \int_{z} q_{\phi}(z\vert x) \frac{p_{\theta}(x,z)}{q_{\phi}(z\vert x)} \ \ \ ;\text{同时乘除} q_{\phi}(z\vert x) \text{,等于没变化}\\&= \log \mathbb{E}_{q_{\phi}(z\vert x) } \left [ \frac{p_{\theta}(x,z)}{q_{\phi}(z\vert x)} \right ] \ \ \ ;根据期望公式\\ & \ge \mathbb{E}_{q_{\phi}(z\vert x) } \log \left [ \frac{p_{\theta}(x,z)}{q_{\phi}(z\vert x)} \right ] \ \ \ ;\text{根据Jensen不等式}\\ &= \int_{z} q_{\phi}(z\vert x) \log \left [ \frac{p_{\theta}(x,z)}{q_{\phi}(z\vert x)} \right ]\\&= \left [ \int_{z} q_{\phi}(z\vert x) \log p_{\theta}(x,z) - \int_{z} q_{\phi}(z\vert x) \log q_{\phi}(z\vert x) \right ]\\&\triangleq \mathcal{L}(q,\theta) \end{aligned}\]其中,Jensen 不等式是:如果 $\varphi$ 是任意的凸函数,那么一定有
\[\varphi(E(X)) ≤ E(\varphi(X))\]如果是凹函数的话就把符号反过来变成 $≥$即可。
因此,回到上面推导,第 5 行就是根据 Jensen 不等式直接得到(因为 ln() 是凹函数)。整个公式的结果就是这个 ELBO 下界函数了,记为 $\mathcal{L}(q,\theta)$:
\[\begin{aligned}\mathcal{L}(q,\theta) &= \int_{z} q_{\phi}(z\vert x) \log p_{\theta}(x,z)- \int_{z} q_{\phi}(z\vert x) \log q_{\phi}(z\vert x)\\&= \mathbb{E}_{z \sim q_{\phi}} [ \log p_{\theta}(x,z) ]- \mathbb{E}_{z \sim q_{\phi}}[ \log q_{\phi}(z\vert x) ]\end{aligned}\tag{2}\]
这里积分的范围将 $z \sim q_{\phi}(z\vert x)$ 简写为 $z \sim q_{\phi}$ 简单一些。
根据链式法则,联合概率 $p(x,z)$ 有两种分解方式
\[p(x,z) = p(z) p(x\vert z)=p(x)p(z\vert x)\]接下来会分开介绍这两种形式分解 ELBO 即 Eq. (2).
(1)第一种形式:使用 $p(x,z) = p(x) p(z\vert x)$
\[\begin{aligned} \mathcal{L}(q,\theta) &= \mathbb{E}_{z \sim q_{\phi} } [ \log p_{\theta}(x,z) ] - \mathbb{E}_{z \sim q_{\phi} }[ \log q_{\phi}(z\vert x)]\\ &= \mathbb{E}_{z \sim q_{\phi}} \left [ \log p_{\theta}(x) + \log p_{\theta}(z\vert x) \right ] - \mathbb{E}_{z \sim q_{\phi}}[ \log q_{\phi}(z\vert x)]\\ &= \underbrace{\mathbb{E}_{z \sim q_{\phi}} [ \log p_{\theta}(x) ]}_{\text{与}z\text{无关,期望符号可以去掉}} + \mathbb{E}_{z \sim q_{\phi}} [\log p_{\theta}(z\vert x) ] - \mathbb{E}_{z \sim q_{\phi}}[ \log q_{\phi}(z\vert x)]\\ &= \underbrace{\log p_{\theta}(x)}_{\text{观测数据对数似然/证据}} + \underbrace{ \mathbb{E}_{z \sim q_{\phi}} [ \log p_{\theta}(z\vert x) ] - \mathbb{E}_{z \sim q_{\phi}}[ \log q_{\phi}(z\vert x)] }_{\text{KL散度}}\\ &= \ell(\theta;x) - KL( q_{\phi}(z\vert x) \Vert p_{\theta}(z\vert x)) \end{aligned}\]这里最后一行的第二项是直接套用了 KL Divergence 的表达式(可以参考数学基础中的 KL Divergence 部分)。该项前面的减号是因为 KL(. \Vert .) 前后的顺序相比于倒数第二行调换了。
对于上式,移项整理后
\[\underbrace{ \ell(\theta;x) }_{\text{观测数据对数似然/证据}}= \underbrace{ \mathcal{L}(q,\theta) }_{\text{证据下界函数 ELBO}}+ \underbrace{ KL(q_{\phi}(z\vert x)\Vert p_{\theta}( z \vert x ) )}_{ \text{KL散度}}\]故,我们想要最大化的概率 $\ell(\theta;x)$ 就等于 ELBO 加上一个 KL 散度,而后者始终是非负的。因此,这就进一步验证了 ELBO 就是下界。
(2)第二种形式:使用 $p(x,z) = p(z)p(x\vert z)$
分解前面的 ELBO 表达式 Eq. (2) 得到
\[\begin{aligned} \mathcal{L}(q,\theta) &= \mathbb{E}_{z \sim q_{\phi}} [ \log p_{\theta}(x,z) ] - \mathbb{E}_{z \sim q_{\phi}}[ \log q_{\phi}(z\vert x)]\\ &= \mathbb{E}_{z \sim q_{\phi}} [ \log p_{\theta}(x\vert z) + \log p(z)] - \mathbb{E}_{z \sim q_{\phi}}[ \log q_{\phi}(z\vert x)]\\ &= \mathbb{E}_{z \sim q_{\phi}} [\log p_{\theta}(x\vert z) ] + \underbrace{ \mathbb{E}_{z \sim q_{\phi}} [ \log p(z) ] - \mathbb{E}_{z \sim q_{\phi}}[ \log q_{\phi}(z\vert x))] }_{\text{KL散度}}\\ &= \underbrace{\mathbb{E}_{z \sim q_{\phi}} [\log p_{\theta}(x\vert z) ]}_{重建项(\textbf{reconstruction term})} - \underbrace{KL(q_{\phi}(z\vert x)\Vert p(z))}_{正则项(\mathbf{regularization \ term})} \end{aligned}\tag{3}\]
即,ELBO 有一个重建项和一个KL散度的正则项组成。重建项是当 $z \sim Q(Z\vert X)$分布下, $\log p_\theta(x\vert z)$ 在整个 $z$ 的区间上的的期望值。正则项就是两个分布的 KL Divergence。
3.2 VAE Loss 计算
总结上一章,我们要最大化目标的概率 $\ell(\theta;x)$ ,转换为了要最大化 ELBO $\mathcal{L}(q,\theta)$,而最大化 ELBO 又相当于最大化 Eq. (3) 所示的两项之和,其中就相当于同时最大化第一项的重建项,并且最小化第二项的 KL 散度。
接下来分别介绍 Eq. (3) 中的这两项。
(1)第一项重建项的计算
第一项是
\[\mathbb{E}_{z \sim q_{\phi}} [\log p_{\theta}(x\vert z)]\]它是一个期望值,而在已知 $z$ 的情况下,由于 $X$ 是一个随机变量, $z$ 到 $x$ 的映射是通过 $z$ 和 $X$ 的均值参数 $\mu_x$ 建立映射函数实现的。 这里并没有建立从 $z$ 到方差参数 $\Sigma_x$ 之间的映射,通常是为了模型更简单,即假设了 $X$ 的 的方差为常量,即单位方差 $I$。事实上,在大部分回归模型中都是这样假设的
\[\mu_x = \mu_{\theta}(z) = decoder_{\theta}(z)\]这里 $\mu_x$ 是 $X$ 的期望参数, $\mu_\theta(z)$ 是 $z$ 到 $\mu_x$ 的映射。因此,最大化 $\log p(x\vert z)$ 其实就相当于使我们的 Decoder 网络的预测结果即均值 $\hat{x}$ 接近实际观测的真实值 $x$。因此,最大化这一项其实就是最小化一个 Reconstruction Loss。
Loss 的最终设计取决于 Decoder 网络的设计形式。记 $\hat{x}$ 是模型的输出值,而 $x$ 是观测的真实值。VAE 论文中给出了两种常见形式:
(1) 如果 $X$ 的观测值数据只是 binary 数据(例如 binary image),那么经常会把 Decoder 设计成 Decoder 由 MLP + Sigmoid 函数组成。Sigmoid 函数是为了将最终的每个输出值 $\hat{x}_i$ 都限制在 [0,1] 之间,从而使其表达一个概率。于是,可以认为
\[P(X\vert \hat{X})\]是 multivariate Bernoulli distribution,其中 $X$ 中每个值 $x_i$ 的概率 $p(x_i)$ 其实就是 Decoder 得到的 $\hat{x}_i$ 值本身,因此:
\[P(X\vert\hat{X})=\sum_i \hat{x}_i^{x_i}(1-\hat{x}_i)^{1-x_i}\]因此:
\[\log P(X\vert\hat{X})=\sum{x_i} \log \hat{x}_i + \sum (1-x_i) \log (1-\hat{x}_i)\]这其实就正是 Binary Cross Entropy Loss(BCE Loss)的相反数。因此,最大化这一项就相当于最小化 BCE Loss。
有关 BCE Loss 可以参考:
(2) 如果 $X$ 的观测值数据是普通的连续数据(如普通信号等),此时通常假设 $X$ 也符合高斯分布。因为 VAE Decoder 的输入 $Z$ 服从正态分布,因此从 $Z$ 经过 Decoder 重建出的结果同样也应当服从正态分布。因此,我们用 Decoder 要预测的就是随机变量 $X$ 这个分布的均值(没有预测方差等估计是为了模型简单)。即:$P(X\vert Z) \sim N(\hat{X}, \sigma^2 * I)$(这里的方差就是某个超参数,注意是多维的)。因此,根据多维高斯分布公式:
\[P(X\vert Z) = \frac{1}{((2\pi)^k \vert\Sigma\vert)^\frac{1}{2}} e^{-\frac{1}{2 \sigma^2}(X-\hat{X})^T(X-\hat{X})}\]取 log 后:
\[\log P(X) = {-\frac{1}{2\sigma^2}(X-\hat{X})^T(X-\hat{X})} + C\]其中 C 是常数项。注意这里写成了矩阵相乘形式,它已经包含了求和部分,因此就不用显式的积分号了。这里的二次项 $(X-\hat{X})^T(X-\hat{X})$ 其实就正是 $X,\hat{X}$ 之间的 L2 Loss,即 MSE Loss。注意该项前面的负号。
于是,最大化这一项还是相当于最小化这个 MSE Loss。
(2)第二项 KL 散度的计算
这里的第二项 $KL(q_{\phi}(z\vert x)\Vert p(z))$ 就是两个分布之间的 KL Divergence。回顾此前内容,VAE 中已经提前假定了 $p(z) = \mathcal{N} (0,I)$ 的正态分布。既然 VAE 是 Encoder 网络来预测 $Z$,那么既然 $z$ 服从高斯分布,那么条件概率 $q(z\vert x)$ 肯定也是高斯分布,只是它的均值和方差暂时不知道。我们用 $\mu_z$ 和 $\Sigma_z$ 分别表示 $q(z\vert x)$ 分布的均值和方差,即 $q_\phi(z\vert x) =\mathcal{N} (\mu_z,\Sigma_z)$。
在传统的自编码(Auto Encoding)模型中, $Z$ 是一个数值变量,输入变量 $X$ 经过编码器(encoder)直接输出 $Z$ 的值。 然而在 VAE 中, $Z$ 是一个随机变量,因此不能从 $X$ 直接映射到 $Z$ 的值,而是通过预测 $Z$ 的均值和方差来间接计算 $Z$ 的值。
接着就可以计算这个第二项的 KL 散度了。已知 $q_\phi(z\vert x) = \mathcal{N} (\mu_z,\Sigma_z)$ 以及 $p(z) = \mathcal{N} (0,I)$ 这两个高斯分布,带入数学基础中介绍的 KL Divergence 在高斯分布下的表达式可以得到:
\[\begin{aligned} KL(q_{\phi}(z\vert x)\Vert p(z)) &= \frac{1}{2} \left[ \log \frac{\vert\Sigma_p\vert}{\vert\Sigma_q\vert} - d + tr(\Sigma_p^{-1} \Sigma_q) + (\mu_p - \mu_q)^\top \Sigma_p^{-1} (\mu_p - \mu_q) \right] \ \ \ ; p,q下标分别对应q(z)和p(z)\\ &= \frac{1}{2} (- \log \vert\Sigma_z\vert -d + tr(\Sigma_z) + \mu_z^T\mu_z) \end{aligned}\]其中 $d$ 是变量 $z$ 的维度。这是多维变量的形式。
如果 $z$ 是一维变量,即 $q_\phi(z\vert x) = \mathcal{N} (\mu_z,\sigma_z^2)$ 和 $p(z) = \mathcal{N} (0,1)$ 时,散度就等于这样:
\[\begin{aligned} KL(q_{\phi}(z\vert x)\Vert p(z)) &= \log \frac{\sigma_p}{\sigma_q} + \frac{\sigma_q^2 + (\mu_p - \mu_q)^2}{2\sigma_p^2} - \frac{1}{2} \\ & =-\log \sigma_z+\frac{1}{2}(\sigma_z^2+\mu_z^2 - 1) \\ &=-\frac{1}{2}(1 + \log \sigma_z^2 - \sigma_z^2 - \mu_z^2) \end{aligned}\]3.3 VAE Loss 的最终形式
在代码实现中,我们一直是最小化 Loss。因此,我们要把前面的最大化 $\mathfrak{L}$ 即 ELBO 的问题转变为最小化问题。从前面的推导可以看出, ELBO 表达式 Eq. (3) 的第一项即重建项,对它的最大化就相当于最小化 BCE Loss 或 MSE Loss。而第2项则是减去 $KL(q,p)$,因此最大化 ELBO 还是要最小化 KL Divergence。因此,最终的 VAE Loss 就是简单的重建项 Loss + KL Divergence 就行了。
3.4 Reparameterization Trick 重参数化
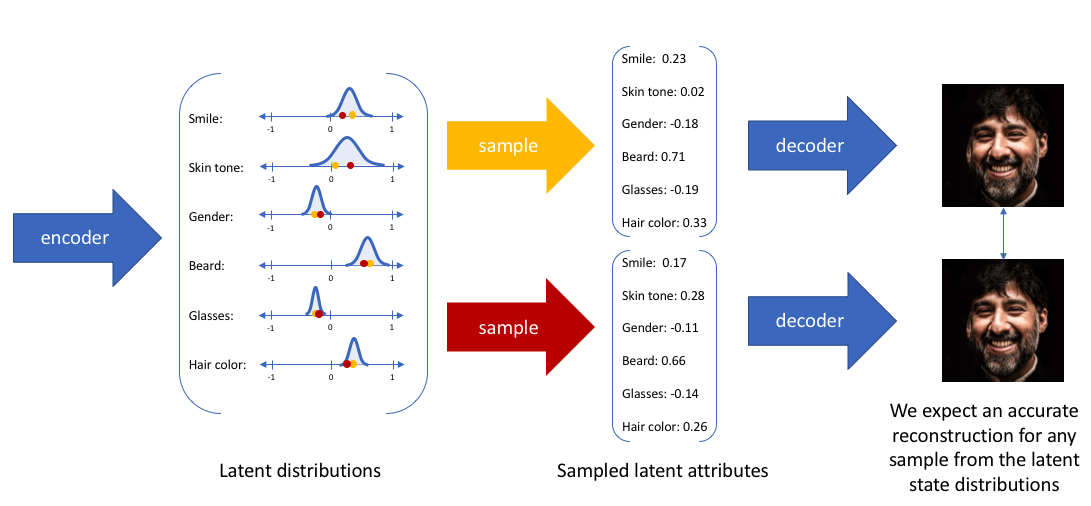
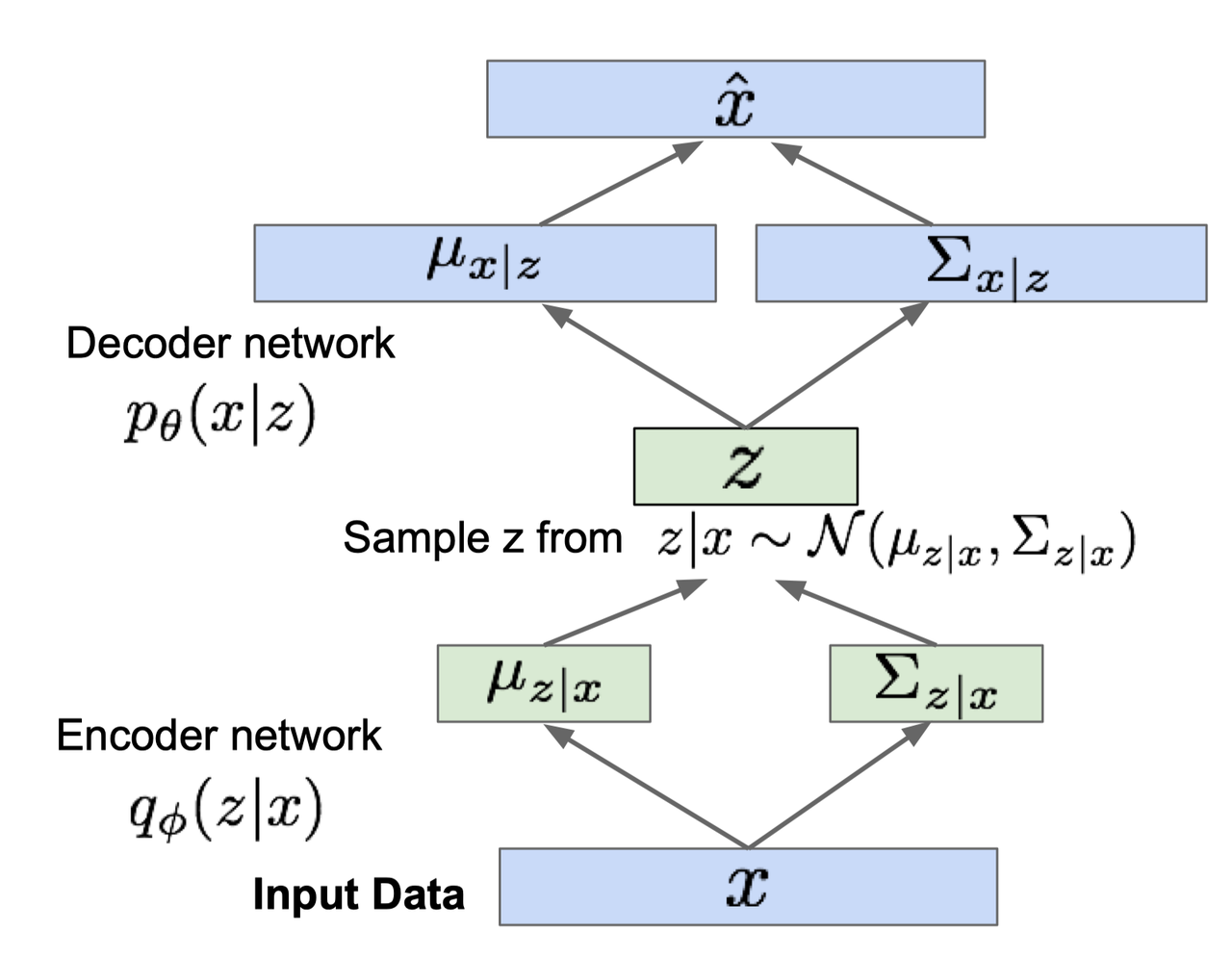
总结一下代码实现中的 VAE 的 Encoder + Decoder 的整个流程:
- 从 X 出发,使用 Encoder 预测正态分布 $Q(Z\vert X)$ 的参数,记为 $\mathcal{N} (\mu, \sigma^2)$;
- 从正态分布 $\mathcal{N} (\mu, \sigma^2)$ 中采样得到离散值 ${z}$;
- 将 ${z}$ 作为 Decoder 的输入,重建出最终的 $\hat{X}$。
整个流程如下图:
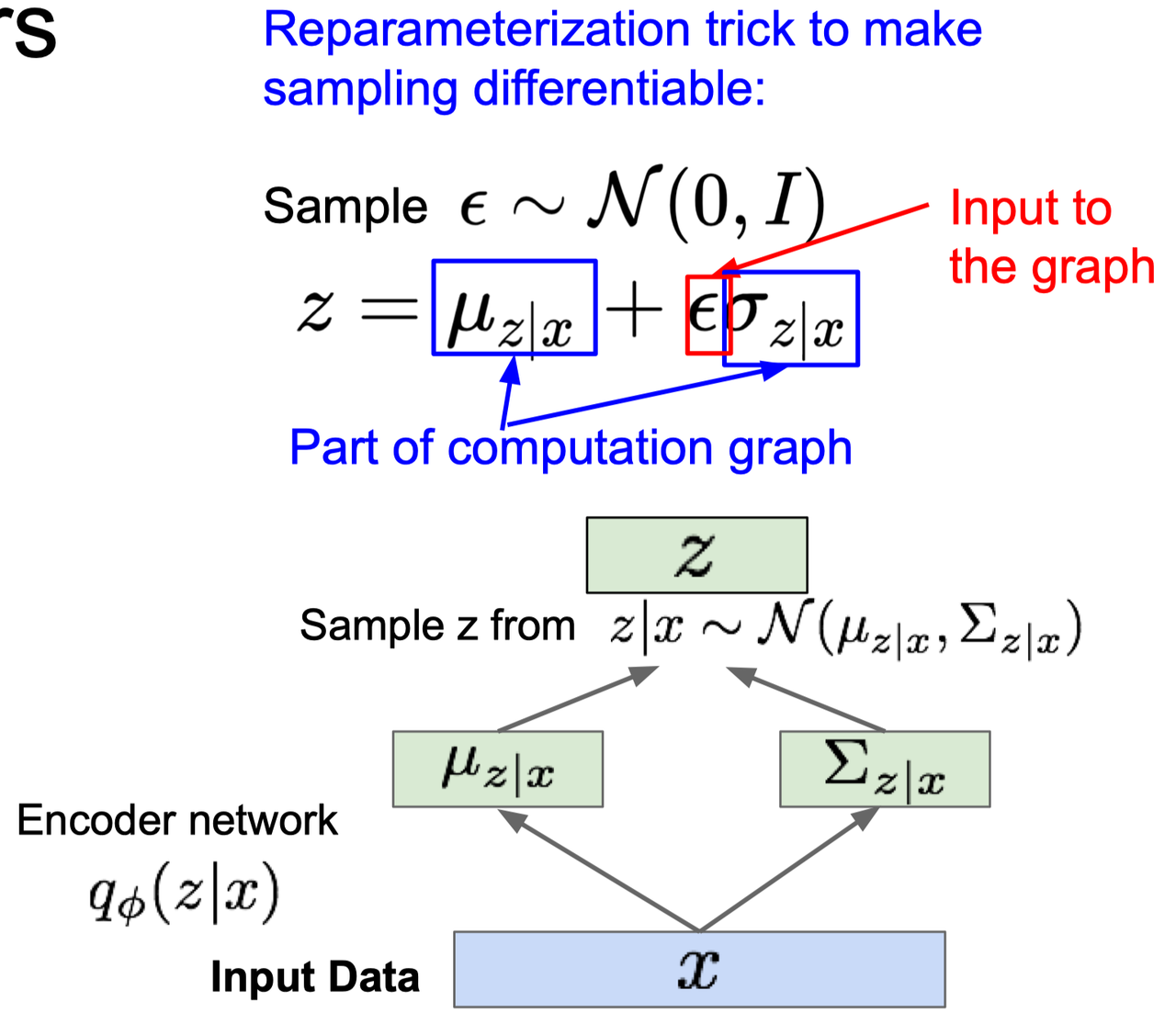
但是这里出现一个问题:这里的 $z$ 是一个随机变量,如何从 $Q(Z\vert X)$ 的分布中 sample z 的值?或者说,如何使得 Encoder $Q(Z\vert X)$ 输出的结果就是满足正态分布的?可以看出,即使我们可以直接得到服从正态分布的 $Q(Z\vert X)$ 的参数,从正态分布中做 Sampling 这一步显然也是不可导的。而代码实现中必须要求每一步都可导(differentiable),这样才能做 backpropagation。
VAE 在这一步给了一个 reparameterization trick,充分利用了高斯分布的性质:
- 首先使用 Encoder 网络预测参数值 $\mu, \sigma^2$;
- 然后令 $z=\mu + \sigma *\epsilon$ ,其中 $\epsilon \sim \mathcal{N} (0,1)$ 是符合正态 (0,1) 分布的一个常数。
注意 $\epsilon$ 显然和 Encoder $\phi$ 无关。因此,最终的 $z = \mu_\phi + \sigma_\phi \epsilon$,这样就使得和 z 有关的函数对 $\phi$ 可导了。这样的好处是,既能满足 $z$ 是服从 $\mathcal{N} (\mu, \sigma^2)$ 的正态分布的,又使得这一步是可导的。问题解决了。
实际上,给定一个高斯分布 $\mathcal{N} (\mu,\sigma^2)$,对它进行 sampling 的流程其实还是上面这个流程,即引入 $\epsilon \sim \mathcal{N} (0,1)$ 然后做 $z=\mu + \sigma *\epsilon$。因此这其实本来就应该如此。
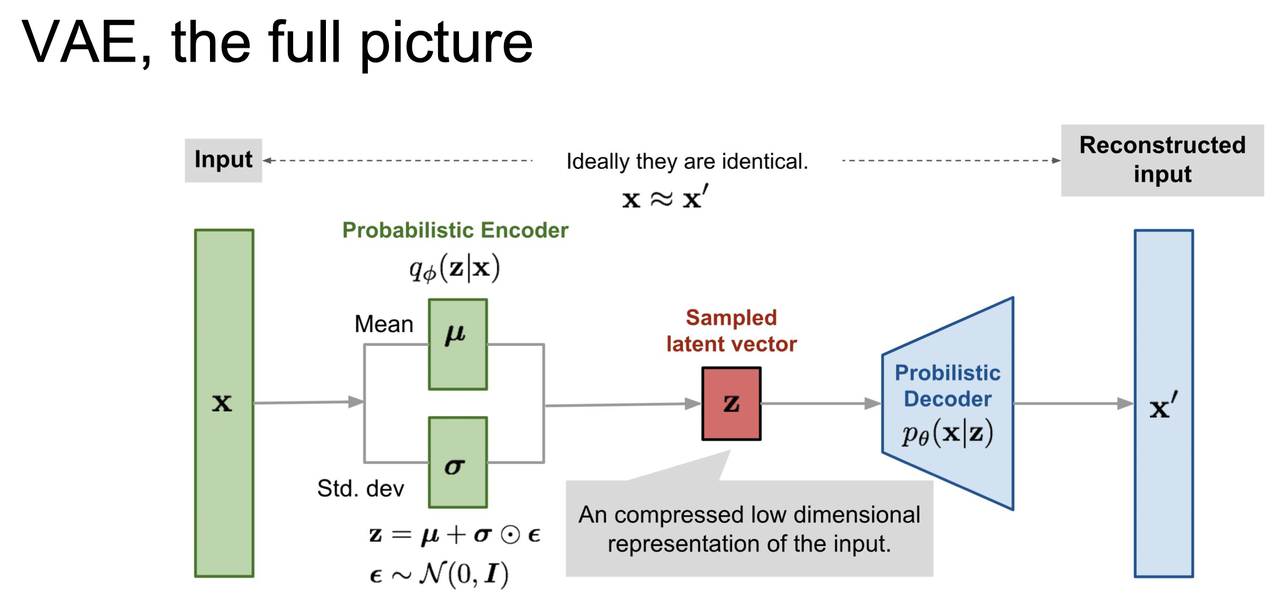
3.5 VAE 最终流程图
4. VAE 代码实现
参考:
- [1] pytorch 官方的一个例子: https://github.com/pytorch/examples/tree/master/vae 该代码是对 VAE 原始论文的复现,非常简单且很清楚。另外,这个链接还有 pytorch 官方提供的几乎所有重要网络的例子。
- [2] 一个博客的介绍以及实现:https://towardsdatascience.com/intuitively-understanding-variational-autoencoders-1bfe67eb5daf
- [3] 另一个人的代码实现:GitHub - LiUzHiAn/VAE-Pytorch
- [4] 另一个博客的实现:https://towardsdatascience.com/building-a-convolutional-vae-in-pytorch-a0f54c947f71
代码实现倒是挺简单的,注意的点就是 loss 的构成(参考上一章节的“VAE的原理和流程”介绍)。参考上面链接 [1] 和 [3] 足够了,两者几乎一致。
下面是 VAE 类的核心代码以及 VAE Loss代码:
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
self.fc1 = nn.Linear(784, 400)
self.fc21 = nn.Linear(400, 20)
self.fc22 = nn.Linear(400, 20)
self.fc3 = nn.Linear(20, 400)
self.fc4 = nn.Linear(400, 784)
def encode(self, x):
h1 = F.relu(self.fc1(x))
return self.fc21(h1), self.fc22(h1)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5*logvar)
eps = torch.randn_like(std)
return mu + eps*std
def decode(self, z):
h3 = F.relu(self.fc3(z))
return torch.sigmoid(self.fc4(h3))
def forward(self, x):
mu, logvar = self.encode(x.view(-1, 784))
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
# Reconstruction + KL divergence losses summed over all elements and batch
def loss_function(recon_x, x, mu, logvar):
BCE = F.binary_cross_entropy(recon_x, x.view(-1, 784), reduction='sum')
# see Appendix B from VAE paper:
# Kingma and Welling. Auto-Encoding Variational Bayes. ICLR, 2014
# https://arxiv.org/abs/1312.6114
# 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE + KLD
几个注意要点:
- VAE encoder 中其实就是用 Linear or Conv 等层将输入给编码成 mean and variance $\mu,\sigma^2$。注意,通常为了方便后续结算,编码的输出通常是 $\mu$ 和 $\log{\sigma^2}$ 而不是 $\sigma$ 本身,我认为原因是:
- 代码实现中,如果需要预测 $a^b$ 这种次方值,经常会先预测它的 log 值,然后再用 exp() 操作获取原始值。可能原因是计算 exp 开销小,而计算 log 的开销要大。
- 另一个估计 $\log{\sigma^2}$ 的原因是方便后续计算 Loss。VAE Loss 计算中,上图代码中所示的其实就是此前推导的 Loss 结果。注意因为encode结果是 $\log{\sigma^2}$,使得计算最终 loss 倒是方便很多(因为loss中有 log 项),只需要去 e 的次方就容易得到 $\sigma^2$。
当 Encoder 预测得到 $\log \sigma^2$ 后,可以这样得到标准差: $e^{0.5\cdot \log{\sigma^2}}=e^{\log (\sigma^2)^{0.5}}=\sigma$。
5. VAE 变种: 卷积 VAE (Convolutional VAE, or Conv-VAE)
参考:
Convolutional VAE (Conv-VAE) 的构成和普通的 VAE 非常像,唯一区别就是为了专门针对 images,将 普通的 VAE 的 Encoder 中使用的 MLP 改成了 Convolutional layers。对应的,将在 Decoder 中使用的 MLP 改成了 Transposed Convolutional layers(即 deconvolution)。其余的部分都不变,例如 loss 的估计、laten code 维度、正态分布的 reparameteration trick 等都不变。
6. 最新工作
6.1 VQ-VAE
- https://arxiv.org/pdf/2310.05737: MAGVIT-v2 原始论文 Language Model Beats Diffusion – Tokenizer is Key to Visual Generation
- https://arxiv.org/pdf/2104.10157:VideoGPT: Video Generation using VQ-VAE and Transformers
