深度学习中的数学基础
1. 贝叶斯公式
参考:
核心是:
\[P(A\vert B) = \frac{P(A,B)}{P(B)} = \frac{P(B\vert A)P(A)}{P(B)}\]其中 $P(A,B)$ 是 $A, B$ 同时发生的联合概率,且满足:
\[P(A,B)=P(A\vert B)P(B)=P(B\vert A)P(A)\]2. 正态分布/高斯分布
2.1 一维高斯分布
变量 $x$ 符合 $\mathcal{N} ∼ (\mu,\sigma^2)$ 的分布时, $x$ 的概率 $p(x)$ 会满足:
\[p(x) = \frac{1}{(2\pi\sigma^2)^\frac{1}{2}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\]一维正态分布的线性属性:
如果变量 $\epsilon ∼ \mathcal{N}(0,1)$ 的正态分布,那么新的变量 $x = \mu + \sigma \epsilon$ 将会符合 $\mathcal{N} ∼ (\mu,\sigma^2)$ 的正态分布。
2.2 多维高斯分布
多维高斯分布 $x \sim N(\boldsymbol{\mu,\Sigma})$ 的表达式是
\[\mathcal{N}(x; \mu, \Sigma) = \frac{1}{(2\pi)^{d/2}|\Sigma|^{1/2}} \exp \left( -\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu) \right)\]其中:
- $d$ 是变量的维度,即 $x$ 是 d 维的 column vector
- $\boldsymbol{\mu}$ 此时是 d 维向量,而 $\boldsymbol{\Sigma}$ 是协方差矩阵:
3. 期望 Expected Value
设 $X$ 是一个连续变量,它的概率分布是 $p(x)$,那么 X 在一个区间 $[a,b]$ 上的的期望值被定义为:
\[E(X)=\int_a^b x p(x)d\]离散状态下自然就是我们高中学到的期望值的概念:
\[E(X) = \sum_i x_ip(x_i)\]期望满足结合律:
\[E(X + Y) = E(X) + E(Y)\]并且可将常数提出:
\[E(aX+b)=aE(X) + b\]如果 $X$ 是一个多维变量或者是一个矩阵(相当于一个 2D 的变量组成,每个位置就是一个随机变量),那么还有几个特别的性质。
例如,矩阵的“迹”(trace)的期望就等于期望后的迹:
\[E(Tr(X)) = Tr(E(X))\]这是因为,矩阵的迹就等于对角线元素的和。因此这个求和在期望(的积分)内部或者外部计算显然都是一样的。
4. 方差 Variance
一个连续变量 $X$ 的方差被定义为:
\[Var(X) = E[(x - E(X))^2]\]方差同样满足结合律:$Var(X+Y)=Var(X)+Var(Y)$,不过方差的常数提取稍有区别:
\[Var(aX+b)=a^2Var(X)\]注意它消除了常数项,并且提出来的常数变成了平方。
另外有一个很重要的方差和期望之间的转换公式:
\[Var(X)=E(X^2)-E(X)^2\]这是因为:
\[\begin{aligned} Var(X) &= E[(X-E(X))^2] \\ &= E[X^2-2XE(X)+E^2(X)] \\ &= E(X^2) -2E^2(X) + E^2(X) \\ &= E(X^2) -E^2(X) \end{aligned}\]这里第2-3行是因为,期望的期望 $E(E(X))=E(X)$,因为 $E(X)$ 作为期望值是一个定量而非一个随机变量。注意,在期望和方差的定义中,X 可以满足任意概率分布,而正态分布只是特例。
如果是多维变量,那对应的是协方差(Covariance),即 $X$ 中不同维度之间的相关性 :
\[Cov(X) = E[(X-E(X))(X-E(X))^T]\]5. 期望和方差在正态高斯分布上的例子
如果 X 满足高斯分布,那么
(1)$x \equiv 1$(恒等于1)的期望值
\[E(1)=\int p(x) dx = 1 \tag{1}\]
这个其实对任意的概率分布都成立,因为一个概率分布在整个区间上的概率和等于 1。
(2)如果一维变量 $x \sim \mathcal{N}(0,1)$,验证 X 的期望值是 0 且方差是 1。
首先是期望:
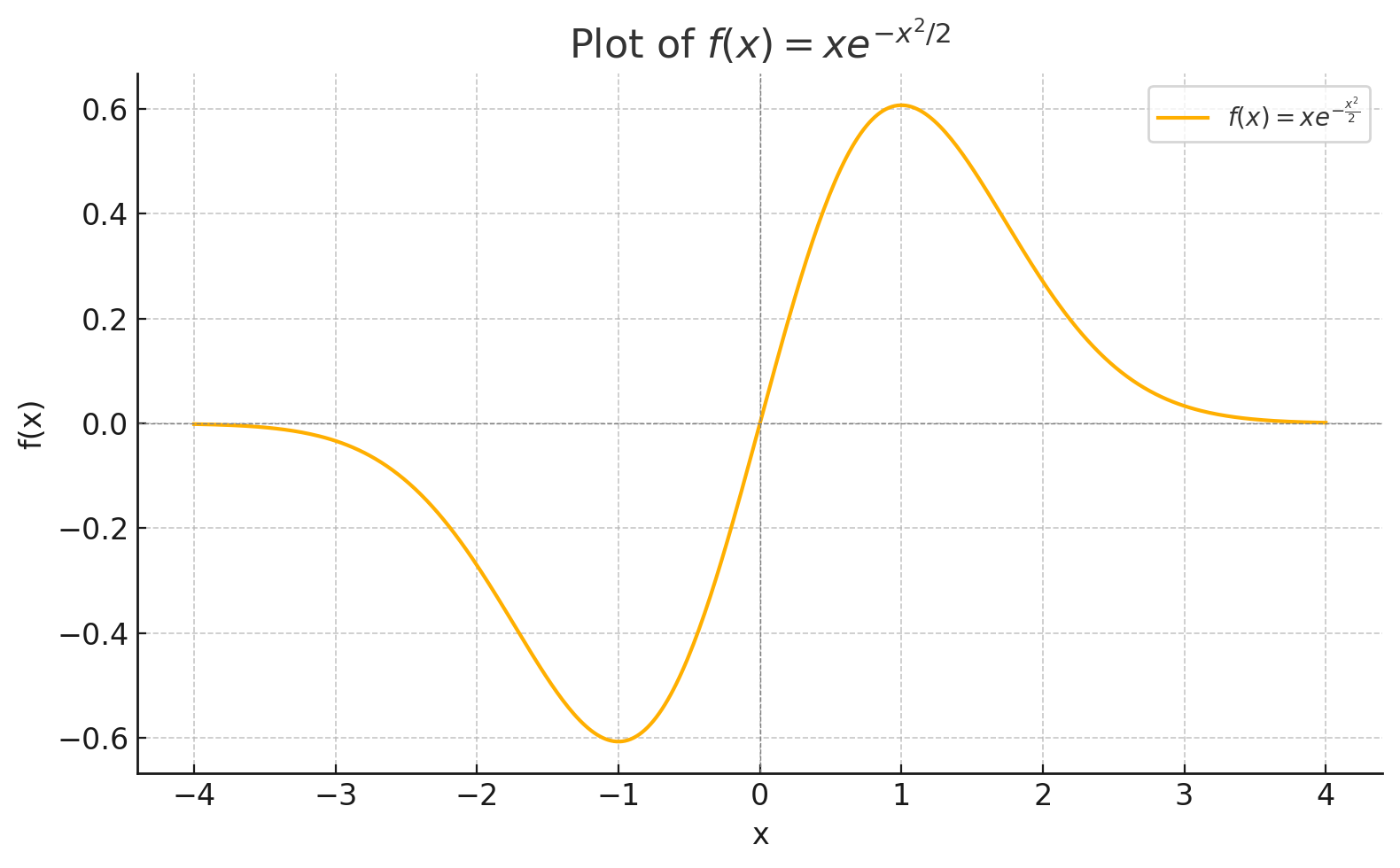
\[E(X)=\int_{-\infty}^{\infty} x\frac{1}{(2\pi\sigma^2)^\frac{1}{2}}e^{-\frac{(x-\mu)^2}{2\sigma^2}} dx = \frac{1}{(2\pi)^\frac{1}{2}}\int_{-\infty}^{\infty} xe^{-\frac{x^2}{2}} dx = \left.\frac{1}{(2\pi)^\frac{1}{2}}xe^{-\frac{x^2}{2}} \right\vert_{-\infty}^{\infty} = 0\]这里的倒数第二步使用了积分公式去掉了积分符号,最后一步等于 0 是因为 $f(x) = xe^{-\frac{x^2}{2}}$ 函数相对于原点是完全对称的(即它是相对 x 轴和 y 轴都反对称),因此它在整个区间上的积分是 0(如下图).
接着是方差:
\[Var(X)=E(X^2)-E(X)^2=E(X^2)=\frac{1}{(2\pi)^\frac{1}{2}}\int_{-\infty}^{\infty} x^2e^{-\frac{x^2}{2}} dx\]接下来稍微有点 trick,我们使用拆分法来计算这个积分。为了计算 $f(x)=x^2e^{-\frac{x^2}{2}}$ 的积分,我们取 $u(x)=x, \ \ \ \ v(x) = e^{-\frac{x^2}{2}}$,那么 $uv$ 的导数
\[(uv)' = u'v + uv' = e^{-\frac{x^2}{2}} - x^2 e^{-\frac{x^2}{2}} = e^{-\frac{x^2}{2}} - f(x)\]因此 $f(x)$ 的积分可以通过上式中另外两项的积分算出来。带入前面的方差公式:
\[\begin{aligned} Var(X) &= \frac{1}{(2\pi)^\frac{1}{2}} \int_{-\infty}^{\infty} x^2e^{-\frac{x^2}{2}} dx \\ & = \frac{1}{(2\pi)^\frac{1}{2}} \left\{\int_{-\infty}^{\infty} e^{-\frac{x^2}{2}} dx - \int_{-\infty}^{\infty} (uv)' dx \right \} \\ &=\frac{1}{(2\pi)^\frac{1}{2}} \int_{-\infty}^{\infty} e^{-\frac{x^2}{2}} dx - \frac{1}{(2\pi)^\frac{1}{2}} \left.(uv)\right\vert_{-\infty}^{\infty} \\ &= \frac{1}{(2\pi)^\frac{1}{2}} \int_{-\infty}^{\infty} e^{-\frac{x^2}{2}} dx - \frac{1}{(2\pi)^\frac{1}{2}}\left.(xe^{-\frac{x^2}{2}}) \right\vert_{-\infty}^{\infty} \end{aligned}\]这里的两项中,前一项其实等于 1,因为它其实就是前面的 Eq. (1),即 X 恒等于 1 且满足 $x \sim N(0,1)$ 的正态分布的期望值,根据前面第 (1) 个例子,它显然等于 1。而后一项其实是 0。这是因为 $e^{-\frac{x^2}{2}}$ 显然要比 x 趋近于 0 的速度快的多的多。
因此,最终的方差 $Var(X)=1$。验证成功。
(3)如果 x 是高维变量 $x \sim \mathcal{N}(0,I)$ ,那么它的期望是 0 且协方差是 $I$。
这个流程和上面一维变量的流程非常类似。
高斯分布:
\[p(x) = \frac{1}{(2\pi)^{d/2}|\Sigma|^{1/2}} \exp \left( -\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu) \right) = \frac{1}{(2\pi)^{d/2}} \exp \left( -\frac{1}{2}x^Tx \right)\]因此期望:
\[E(x) = \int xp(x)dx = \int \frac{1}{(2\pi)^{d/2}} x \exp \left( -\frac{1}{2}x^Tx \right) dx = \frac{1}{(2\pi)^{d/2}} x\left. \exp \left( -\frac{1}{2}x^Tx \right) \right\vert_{-\infty}^{\infty} = 0\]这里最后一步和前面一维变量时候的推导过程同理: $f(x)=x\exp \left( -\frac{1}{2}x^Tx \right)$ 函数相对于原点是完全对称的(即它是相对 x 轴和 y 轴都反对称,它其实就相当于多个一维的 $g(x) = \exp \left( -\frac{1}{2}x^2 \right)$ 函数相乘),因此它在整个区间上的积分是 0。
接着是协方差。
这个按道理不用证明,因为 $x \sim \mathcal{N}(0,I)$ 分布的本身含义就是指其协方差矩阵是 $I$。如果非要证明的话,这说明它的每个自变量 $x_i$ 相互之间是 independent 互不相关,并且每个变量 $x_i$ 都服从 $x_i \sim \mathcal{N}(0,1)$ 分布 ,因此有:
\[\mathbb{E}[x_i x_j] = \begin{cases}1 & \text{if } i = j \\0 & \text{if } i \neq j\end{cases}\]因此,协方差矩阵
\[\mathrm{Cov}(x) = \mathbb{E}[(x-\mu)(x-\mu)^T]=\mathbb{E}(xx^T) = I\](4)如果一维变量 $x \sim \mathcal{N}(\mu,\sigma^2)$,验证一下它的期望是 $\mu$ 且方差是 $\sigma^2$.
首先是期望:
\[E(X)=\int_{-\infty}^{\infty} x\frac{1}{(2\pi\sigma^2)^\frac{1}{2}}e^{-\frac{(x-\mu)^2}{2\sigma^2}} dx = \frac{1}{(2\pi)^\frac{1}{2}\sigma} \int_{-\infty}^{\infty} xe^{-\frac{(x-\mu)^2}{2\sigma^2}} dx\]这里继续使用类似前面计算方差时使用的拆分法。为了计算 $f(x)=xe^{-\frac{(x-\mu)^2}{2\sigma^2}}$ 的积分,我们先计算一个导数:
\[\left\{e^{-\frac{(x-\mu)^2}{2\sigma^2}} \right\}' = -\frac{x-\mu}{\sigma^2}e^{-\frac{(x-\mu)^2}{2\sigma^2}} =-\frac{1}{\sigma^2}xe^{-\frac{(x-\mu)^2}{2\sigma^2}} + \frac{\mu}{\sigma^2}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\]可以看出,这里右边的前一项正是 $f(x)$ 乘以常数。两边同时乘以常数项 $\frac{\sigma}{(2\pi)^\frac{1}{2}}$,然后移项化简一下凑成前面的期望表达式:
\[\frac{1}{(2\pi)^\frac{1}{2}\sigma}xe^{-\frac{(x-\mu)^2}{2\sigma^2}} = \mu \left\{\frac{1}{(2\pi)^\frac{1}{2}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\right\} - \frac{1}{(2\pi)^\frac{1}{2}}\sigma \left\{e^{-\frac{(x-\mu)^2}{2\sigma^2}} \right\}'\]于是,上是两边同时取积分,左边正是期望值:
\[\int_{-\infty}^{\infty}\frac{1}{(2\pi)^\frac{1}{2}\sigma}xe^{-\frac{(x-\mu)^2}{2\sigma^2}} = E(X) = \mu \int_{-\infty}^{\infty} \left\{\frac{1}{(2\pi)^\frac{1}{2}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\right\} dx - \left.\frac{1}{(2\pi)^\frac{1}{2}}\sigma \left\{e^{-\frac{(x-\mu)^2}{2\sigma^2}} \right\} \right\vert_{-\infty}^{\infty}\]而右边的第一项其实就等于 $\mu$,因为该项的积分其实又是前面的公式 Eq. (1),即 $X$ 恒等于 1 且 $X$ 服从正态分布时的期望值就是 1。而右边第二项的积分等于 0,因为正负无穷大时函数值显然都是 0。
因此,成功验证了 $E(X)=\mu$。
接着是方差。根据定义:
\[Var(X)=E[(X-\mu)^2]=\frac{1}{(2\pi)^\frac{1}{2}\sigma}\int_{-\infty}^{\infty}(x-\mu)^2e^{-\frac{(x-\mu)^2}{2\sigma^2}} dx\]取 $z=\frac{x-\mu}{\sigma}$,那么 $dz = \frac{dx}{\sigma}$,两者带入上式:
\[\begin{aligned} Var(X) &=\frac{\sigma^2}{(2\pi)^\frac{1}{2}}\int_{-\infty}^{\infty}\frac{(x-\mu)^2}{\sigma^2}e^{-\frac{(x-\mu)^2}{2\sigma^2}} dz \\ &= \sigma^2 \left \{\frac{1}{(2\pi)^\frac{1}{2}}\int_{-\infty}^{\infty} z^2e^{-\frac{z^2}{2}} dz\right \} \\ &= \sigma^2 \end{aligned}\]最后这个大括号结果是 1,因为它其实就是前面第 (2) 个例子中 $x \sim N(0,1)$ 时的方差结果。因此,成功验证了 $Var(X)=\sigma^2$。
(5)如果高维变量 $x \sim \mathcal{N}(\mu,\Sigma)$,验证一下它的期望是 $\mu$ 且协方差是 $\Sigma$.
高维情况下,符号变得复杂一些。因此首先用一个变量代换:使用
\[z = \Sigma ^{-1/2}(x - \mu)\]因此
\[x = \mu + \Sigma^{1/2}z \\ x - \mu = \Sigma^{1/2}z\]不难看出,此时的 $z \sim \mathcal{N}(0,I)$ 。即我们引入了一个标准正态 0-1 分布的变量。因此,带入到高斯分布后:
\[p(x) = \frac{1}{(2\pi)^{d/2}|\Sigma|^{1/2}} \exp \left( -\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu) \right) = \frac{1}{(2\pi)^{d/2}|\Sigma|^{1/2}} \exp \left( -\frac{1}{2}z^Tz \right) = p(z)\]带入到期望的表达式:
\[\begin{aligned} \mathbb{E}[x] &= \int_{\mathbb{R}^d} x \cdot p(x) \, dx \\ &= \int (\mu + \Sigma^{1/2}z) p(x) \ dx \\ &= \underbrace{\mu \int p(x) dx}_{1的全区间期望就等于1} + \int \Sigma^{1/2}z p(x)dx\\ &= \mu + \Sigma^{1/2} \int z p(z) \Sigma^{1/2}dz \ \ \ ; p(x)=p(z)因为只是等量代换\\ &= \mu + \Sigma \underbrace{\int z p(z) dz}_{z的期望} \\ &= \mu + \Sigma \underbrace{E(z)}_{\mathcal{N}(0,1)分布的期望是0} \\ &= \mu \end{aligned}\]验证成功, $x$ 的期望是 $\mu$。
接下来验证协方差:
\[\mathrm{Cov}(x) = \mathbb{E}[(x-\mu)(x-\mu)^T]=\mathbb{E}[\Sigma^{1/2}z (\Sigma^{1/2}z)^T] = \Sigma^{1/2}\mathbb{E}(zz^T)\Sigma^{1/2}\]而我们前面已经验证了,高维变量 $z \sim \mathcal{N}(0,I)$ 的协方差是 $I$,那么
\[\mathrm{Cov}(x) = \Sigma^{1/2}\mathbb{E}(zz^T)\Sigma^{1/2} = \Sigma^{1/2} I \Sigma^{1/2} = \Sigma\]验证成功。
6. Kullback–Leibler (KL) Divergence: KL 散度
参考:
- Wiki 主页:https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence
- 中文介绍:如何理解K-L散度(相对熵)。这篇其实是翻译自这个文章:Kullback-Leibler Divergence Explained — Count Bayesie。这个原文使用一个很有意思的案例非常直观的解释了 KL Divergence 的含义。强烈推荐。
6.1 原理
给定两个概率分布 p 和 q,通常 p 是一个真实分布,比如来自现实中的观察值,测量值等,而 q 是理论值,或者是针对 p 重建出的模型所得的估计分布。KL Divergence 是一种量化两个分布之间差异的方式,又叫相对熵。它度量的是,使用一个分布 q 来近似另一个分布 p 时所损失的平均信息量。
两个分布 $p,q$ 的 KL Divergence 定义为:
\[\begin{aligned} KL(p,q) &= KL(p || q) \\ &= \int_{-\infty}^{\infty}p(x)\log\frac{p(x)}{q(x)}dx \\&= \int_{-\infty}^{\infty}p(x)[\log p(x) - \log q(x)]dx \\ &= E_{x \sim p}[\log\frac{p(x)}{q(x)}] \end{aligned}\tag{2}\]
这里的最后一行是直接套用了期望的公式得到:期望是变量值和概率值的乘积在某个区间上的和。
下面动图给出了两个不同分布下的 KL Divergence 的曲线变化。总的来说,两个分布 p 和 q 越接近,两者的 KL Divergence 约小,反之就越大。
https://x.com/i/status/1303741288911638530
6.2 正态分布的 KL Divergence 推导流程
参考:
(1)单变量高斯分布的 KL 散度
根据前面的公式 Eq. (2),两个分布 $p,q$ 的 KL Divergence 定义为:
\[KL(p,q) = KL(p || q) = \int_{-\infty}^{\infty}p(x)\log\frac{p(x)}{q(x)}dx = \int_{-\infty}^{\infty}p(x)[\log p(x) - \log q(x)]dx\]如果它们都是正态分布 $p \sim N(\mu_1,\sigma_1), q \sim N(\mu_2, \sigma_2)$,那么可以最终结果会简化很多。推导流程如下:
\[\begin{aligned} KL(p,q) &=\int_{-\infty}^{\infty}p(x)[\log p(x) - \log q(x)]dx \\ &= \int_{-\infty}^{\infty} \left\{ -\log((2\pi)^\frac{1}{2}\sigma_1) - \frac{1}{2}\frac{(x-\mu_1)^2}{\sigma_1^2} +\log((2\pi)^\frac{1}{2}\sigma_2) + \frac{1}{2}\frac{(x-\mu_2)^2}{\sigma_2^2} \right\} p(x) dx \\ &= \int_{-\infty}^{\infty} \left\{ \log \frac{\sigma_2}{\sigma_1} + \frac{1}{2} \left [\frac{(x-\mu_2)^2}{\sigma_2^2} - \frac{(x-\mu_1)^2}{\sigma_1^2} \right] \right\} p(x)dx \\ &= \log \frac{\sigma_2}{\sigma_1} + \frac{1}{2} \int_{-\infty}^{\infty} \left [\frac{(x-\mu_2)^2}{\sigma_2^2} - \frac{(x-\mu_1)^2}{\sigma_1^2} \right]p(x)dx\\ &= \log \frac{\sigma_2}{\sigma_1} + \frac{1}{2} E_1 \left [\frac{(x-\mu_2)^2}{\sigma_2^2} - \frac{(x-\mu_1)^2}{\sigma_1^2} \right] \end{aligned}\]这里将 $\large{\log \frac{\sigma_2}{\sigma_1}}$ 从积分中提出来是参考了前面的公式 Eq. (1):当 X 恒等于 1 时的正态分布的期望就等于 1。上式后面是将积分用期望公式表示, $E_1$ 表示针对 $p(x)$ 的期望。因此,使用上一章介绍的期望的结合律和常数提取的性质,展开上式:
\[\begin{aligned} KL(p,q) &= \log \frac{\sigma_2}{\sigma_1} + \frac{1}{2} E_1 \left [\frac{(x-\mu_2)^2}{\sigma_2^2} - \frac{(x-\mu_1)^2}{\sigma_1^2} \right]\\ &=\log \frac{\sigma_2}{\sigma_1} + \frac{1}{2\sigma_2^2} E_1[(x-\mu_2)^2] - \frac{1}{2\sigma_1^2} E_1[(x-\mu_1)^2] \end{aligned}\]而最后一项 $E_1[(x-\mu_1)^2]$ 其实就是 X 在 $p(x)$ 分布下的方差(上一章的例子也验证了),它就是 $\sigma_1^2$,于是最后一项就等于 $\frac{1}{2}$。因此,现在只剩下第二项展开:
\[\begin{aligned} E_1[(x-\mu_2)^2] &=E_1[(x-\mu_1+\mu_1-\mu_2)^2]\\ &= E_1[ (x-\mu_1)^2] + E_1[(\mu_1-\mu_2)^2] + E_1[(x-\mu_1)(\mu_1-\mu_2)] \\ &= \sigma_1^2 + (\mu_1 - \mu_2)^2 + (\mu_1-\mu_2)[E_1(x) - \mu_1]\\ &= \sigma_1^2 + (\mu_1 - \mu_2)^2 \end{aligned}\]因此,将上式结果带入 KL 表达式,可以得到最终的表达式:
\[KL(p,q) =\log \frac{\sigma_2}{\sigma_1} + \frac{\sigma_1^2 + (\mu_1 - \mu_2)^2}{2\sigma_2^2} - \frac{1}{2}\](2)多变量高斯分布的 KL 散度
如果两个分布 $p,q$ 都是高维高斯分布,上面的结果会有些变化。
首先已知两个多变量高维高斯分布:
\[p(x) = \mathcal{N}(x; \mu_1, \Sigma_1) \\q(x) = \mathcal{N}(x; \mu_2, \Sigma_2)\]高维高斯分布的表达式是
\[\mathcal{N}(x; \mu, \Sigma) = \frac{1}{(2\pi)^{d/2}|\Sigma|^{1/2}} \exp \left( -\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu) \right)\]其中 $d$ 是变量的维度。
计算 log 后得到
\[\log \mathcal{N}(x; \mu, \Sigma) = -\frac{1}{2} \log \left( (2\pi)^d |\Sigma| \right) - \frac{1}{2}(x - \mu)^\top \Sigma^{-1} (x - \mu)\]套用 Eq. (2) 中的 KL Divergence 表达式
\[D_{\text{KL}}(p \| q) = \mathbb{E}_{x \sim p} \left[ \log \frac{p(x)}{q(x)} \right]\]首先计算 KL Divergence 中的 log 就是
\[\log \frac{p(x)}{q(x)} = - \frac{1}{2} \log \frac{|\Sigma_1|}{|\Sigma_2|} - \frac{1}{2} (x - \mu_1)^\top \Sigma_1^{-1} (x - \mu_1) + \frac{1}{2} (x - \mu_2)^\top \Sigma_2^{-1} (x - \mu_2)\]然后计算 KL 散度:
\[D_{\text{KL}}(p \| q) = - \frac{1}{2} \log \frac{|\Sigma_1|}{|\Sigma_2|} - \frac{1}{2} \mathbb{E}_{x \sim p}[(x - \mu_1)^\top \Sigma_1^{-1} (x - \mu_1)] + \frac{1}{2} \mathbb{E}_{x \sim p}[(x - \mu_2)^\top \Sigma_2^{-1} (x - \mu_2)]\]这里分成 3 项,第 1 项显然与 $x$ 无关,因此期望符号可以去掉。
接下来计算第 2-3 项,两者有些类似。
首先,我们先证明对于任意的矩阵 $A$ 和多维高斯分布 $x$:
\[\begin{aligned} \mathbb{E}_{x\sim \mathcal{N}(\mu,\Sigma)}[(x - \mu)^\top A (x - \mu)] &= tr(A\Sigma) \end{aligned}\]证明它并不难。首先记 $z = x - \mu$,这样就能把 $x\sim \mathcal{N}(\mu,\Sigma)$ 转换到 $z\sim \mathcal{N}(0,\Sigma)$ 这样的分布了。
于是,上式就等于
\[\begin{aligned} \mathbb{E}_{x\sim \mathcal{N}(\mu,\Sigma)}[(x - \mu)^\top A (x - \mu)] &= \mathbb{E}_{z\sim \mathcal{N}(0,\Sigma)}[z^\top A z] \end{aligned}\]根据后面 Section 1.13 介绍的矩阵的迹的性质 $tr(Caa^T)=a^TCa$ (注意这是一个标量),以及前面 Section 1.3 介绍的期望的性质 $E(tr(A)) = tr(E(A))$ (这是因为期望计算是积分,故先期望再对角线求和就等同于先求和再期望),继续上式
\[\begin{aligned} \mathbb{E}_{x\sim \mathcal{N}(\mu,\Sigma)}[(x - \mu)^\top A (x - \mu)] &= \mathbb{E}_{z\sim \mathcal{N}(0,\Sigma)}[z^\top A z] \\ &= \mathbb{E}(tr(Azz^\top)) \ \ \ ; 使用 tr(Caa^T)=a^TCa 性质\\ &= tr(\mathbb{E}(Azz^\top)) \ \ \ ; 基于 E(tr(A)) = tr(E(A)) 提出 tr 操作 \\ &= tr(A \underbrace{\mathbb{E}(zz^\top)}_{z的协方差}) \ \ \ ; A 是常量矩阵 \\ &= tr(A\Sigma) \ \ \end{aligned}\]这里的最后一步是因为, $z$ 的协方差定义就是 $\Sigma=Cov(z) = E[(z-\mu)(z-\mu^T)]=E(zz^T)$,因为 $z\sim \mathcal{N}(0,\Sigma)$ 其均值是 0,协方差是 $\Sigma$。
于是,将这个结果直接带入前面 KL 散度公式的第 2 项结算
\[\mathbb{E}_{x \sim p}[(x - \mu_1)^\top \Sigma_1^{-1} (x - \mu_1)] = tr(\Sigma^{-1} \Sigma) = tr(I) = d\]其中 d 就是 $x$ 向量的维度(即几个子变量)。
接下来是第 3 项。注意它稍微有些特别,因为 $x \sim p(x)$ 的分布,因此它的均值是 $\mu_1$ 而不是 $\mu_2$。因此无法直接计算 $\mathbb{E}_{x \sim p}[(x - \mu_2)^\top \Sigma_2^{-1} (x - \mu_2)]$,而是要变换一下。
取 $\delta = \mu_2 - \mu_1$,那么有:
\[\begin{aligned} \mathbb{E}_{x\sim p}[(x - \mu_2)^\top \Sigma_2^{-1} (x - \mu_2)] &= \mathbb{E}_{x\sim p}[(x - \mu_1 - \delta)^\top \Sigma_2^{-1} (x - \mu_1 - \delta)] \\ &= \mathbb{E}_{x\sim p}[\underbrace{(x-\mu_1)^T\Sigma_2^{-1}(x-\mu_1)}_{参考前面的推导,等于tr(A\Sigma)} - \underbrace{(x-\mu_1)^T\Sigma_2^{-1}\delta}_{替换 z=x-\mu_1} - \underbrace{\delta^T\Sigma_2^{-1}(x-\mu_1)}_{替换 z=x-\mu_1} + \underbrace{\delta^T\Sigma_2^{-1}\delta}_{常量}] \ \ \ ; 展开\\ &= tr(\Sigma_2^{-1} \Sigma_1) - \underbrace{\mathbb{E}_{z\sim \mathcal{N}(0,\Sigma)}(z^T\Sigma_2^{-1}\delta)}_{E(z)等于均值即0} - \underbrace{\mathbb{E}_{z\sim \mathcal{N}(0,\Sigma)}(\delta^T \Sigma_2^{-1}z)}_{同样E(z)等于均值即0} + \mathbb{E}_{x\sim p}(\underbrace{\delta^T\Sigma_2^{-1}\delta}_{常量})\\ &= tr(\Sigma_2^{-1} \Sigma_1) + \delta^\top \Sigma_2^{-1} \delta \\ &= tr(\Sigma_2^{-1} \Sigma_1) + (\mu_2 - \mu_1)^\top \Sigma_2^{-1} (\mu_2 - \mu_1) \end{aligned}\]于是,整理上面 3 项的结果,整个 KL Divergence 就是:
\[\begin{aligned} D_{\text{KL}}(p \| q) &= - \frac{1}{2} \log \frac{|\Sigma_1|}{|\Sigma_2|} - \frac{1}{2} \mathbb{E}_{x \sim p}[(x - \mu_1)^\top \Sigma_1^{-1} (x - \mu_1)] + \frac{1}{2} \mathbb{E}_{x \sim p}[(x - \mu_2)^\top \Sigma_2^{-1} (x - \mu_2)] \\ &= \frac{1}{2} \left[ \log \frac{|\Sigma_2|}{|\Sigma_1|} - d + tr(\Sigma_2^{-1} \Sigma_1) + (\mu_2 - \mu_1)^\top \Sigma_2^{-1} (\mu_2 - \mu_1) \right] \end{aligned}\]注意这里第一项前面符号带入进去了,因此 log 的分子分母交换了顺序。
对比这个结果和前面一维变量时的 DL 散度的最终结果,不难看出,一维的情况就是多维的一个特例。
7. Binary Cross Entropy Loss (BCE Loss)
参考:
Binary Entropy Loss 经常用作训练 Binary Classifier 时候的 loss function。
\[\log P(X\vert\hat{X})=\sum{x_i} \log \hat{x}_i + \sum (1-x_i) \log (1-\hat{x}_i)\]这其实就正是 Binary Cross Entropy Loss(BCE Loss)的相反数
8. One-hot Encoding and one-hot vector
Quora 的高亮回复:https://www.quora.com/What-is-one-hot-encoding-and-when-is-it-used-in-data-science
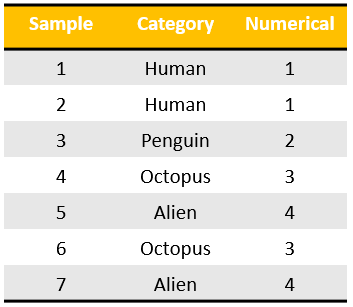
One-hot encoding 是机器学习范畴中常用的一个概念,它指的是只用 0/1 来对数据进行编码的形式。 举例来说,如下图,我们有 7 个输入值,涵盖了 4 个种类。此时我们相对每个种类做一个编码。当然可以按照下图最右边的列所示,编码 1,2,3,4。但是如果这样,它们之间就会有大小关系,而我们并不能说一个种类就大于或小于另一个种类。即,它们无法这么比较。
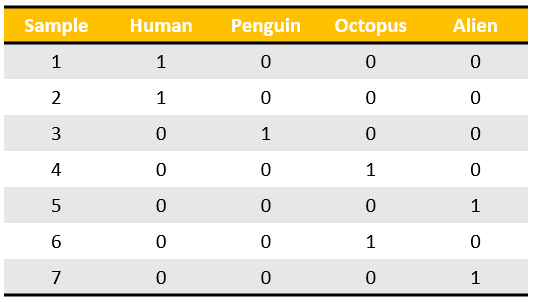
而使用 0/1 编码则不同,如下图所示,用一个 0/1 组成的 vector 给一个种类编码,其中每个位置只在它对应的 sample 处才是 1,其余都是 0。这样不但使得编码之间没有大小之分,而且很容易知道每个类别在每个 sample 位置处的属性。
9. 反卷积 Transposed Convolution
参考:
- [1] 动画示例,非常清楚:https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
- [2] 博客文章,例子很丰富:https://medium.com/apache-mxnet/transposed-convolutions-explained-with-ms-excel-52d13030c7e8
- [3] 详细解释了 Checkerboard artifact 问题: Deconvolution and Checkerboard Artifacts。对应的有人翻译的中文版:Deconvolution and Checkerboard Artifacts
- [4] nn.Conv2d 官方文档:Conv2d ‒ PyTorch 1.9.1 documentation
- [5] nn.ConvTranspose2d 官方文档:ConvTranspose2d ‒ PyTorch 1.10.1 documentation
Transposed Convolution(又称为 Deconvolution),其实就是 Convolution 的逆过程。因为 Convolutional layers 经常被用来降低 width, height 并提升 depth。与之对应的,Transposed Convolutional layers 常被用来提升 width, height 并降低 depth。上面的链接 [1] 给出了多组动画示例,非常清晰。
Transposed Convolution 一个最典型的使用场景就是在 Convolutional AutoEncoders 中作为 Decoder 中的 layers,完全对应 Encoders 中的 Convolutional layers。另外一个常见的应用是作为 upsampling 工具,可以替代常规的诸如 interpolation 技术。以它为基础的 super resolution network 近期常见于各种需要升维的场合中。
代码使用。nn.ConvTranspose2d 的输入参数基本上和 nn.Conv2d 相同(多出的几个参数,例如 output_padding 等都不常用)。但是,很多参数的意义可以说完全不同,甚至正好相反的感觉。Transposed Convolution 计算输出 dimension 的公式可以参见官方文档(链接 [5]):
常见的参数:
- stride 的含义和 nn.Conv2d 完全不同,而是完全相反,倒是和 dilation 含义类似,它指的是输入图片的相邻的 pixels 之间的距离(即,把输入图片的 pixels 扩张一下)。默认是 1,即保持原样(而 nn.Conv2d 中则是 kernel 每次移动的步长)。
- Padding 含义也完全相反,padding = 0 时默认 kernel 在输入图片边缘处要到最外面(到再也不能向外为止)。而 padding > 0 则表示去掉图片边缘处的 padding 单位。即,padding = 0 默认值时输出图片最大,padding > 0 则逐渐减小(参考上面公式);
- dilation 含义和 nn.Conv2d 相同,即 spacing between kernel elements(相邻的 kernel pixels 之间的距离),默认是 1(即保持原样),具体含义可以参见链接 [1] 给出的动画。output_padding 则用的不多,指的是在输出图片上增加一个 padding,默认是 0。
- output_padding 稍有些复杂,参考链接 [5],默认是 0.
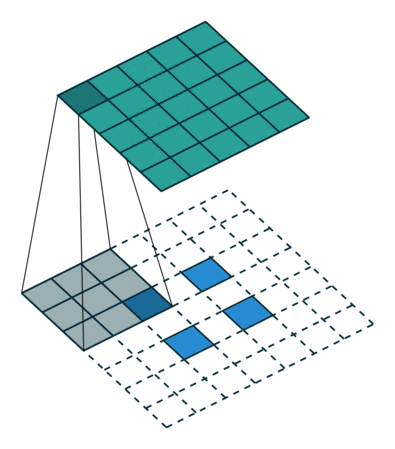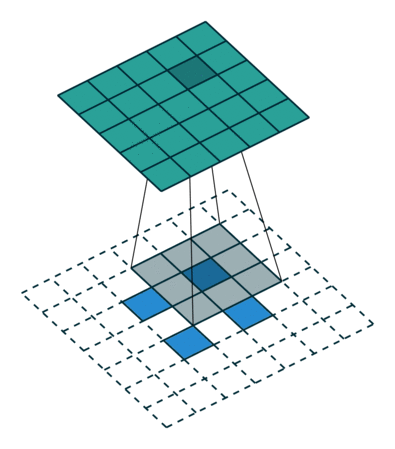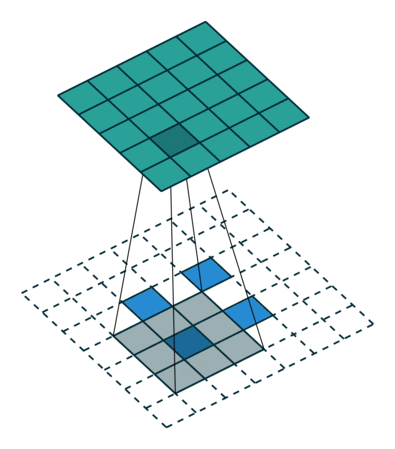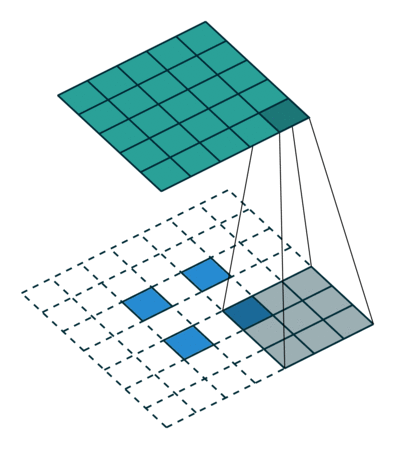
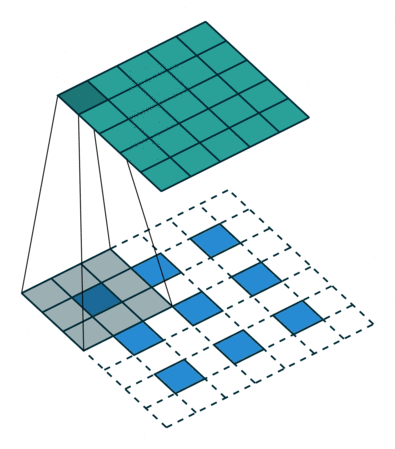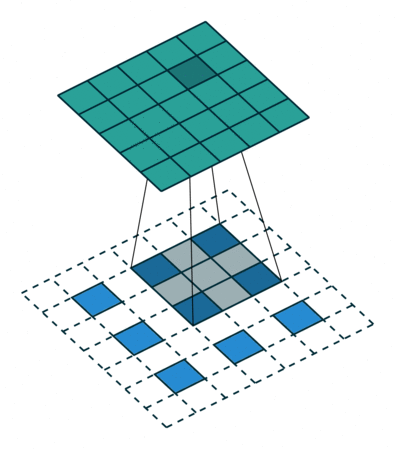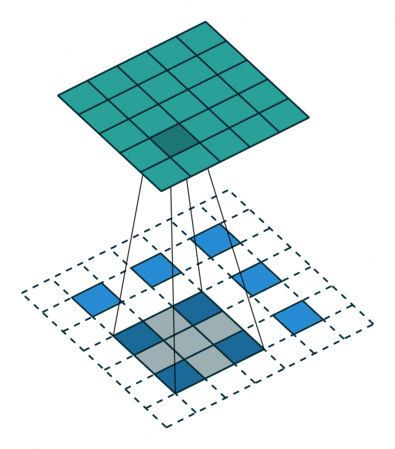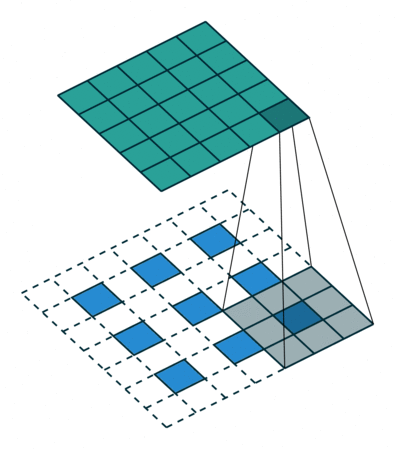
接下来给出几个例子,其中蓝色是输入图片,蓝绿色(cyan)是输出,灰色的是 kernel。 下面是两个 stride=1 的例子。 左图的参数是:input 2x2,kernel 3x3,padding 0,stride 1,Dilation 1,可以验证 output 4x4。 右图的参数是:input 5x5,kernel 3x3,padding 1,stride 1,Dilation 1,可以验证 output 5x5。
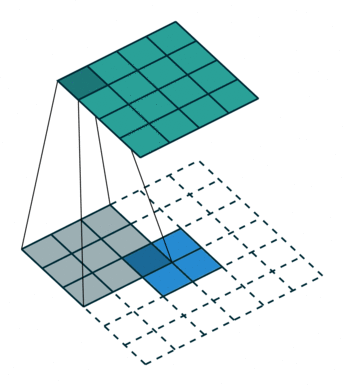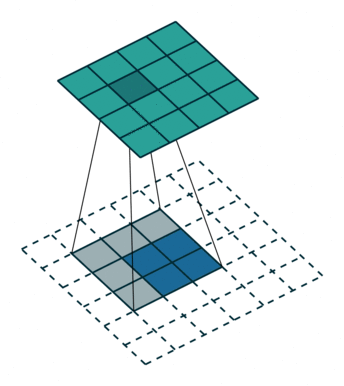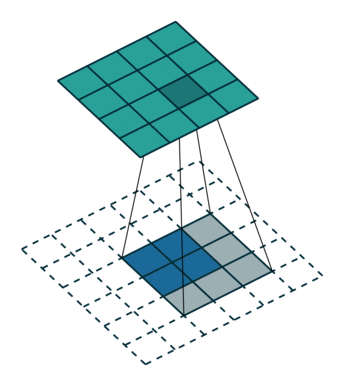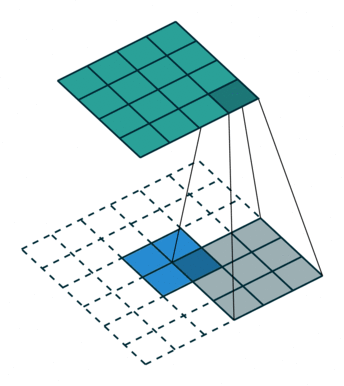
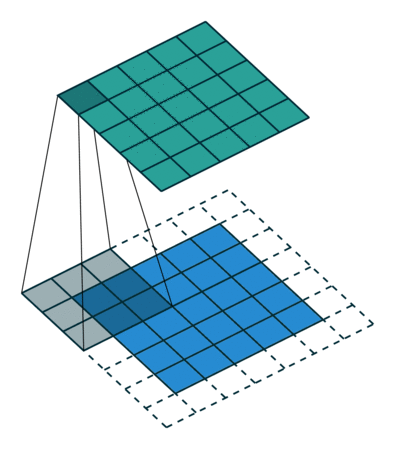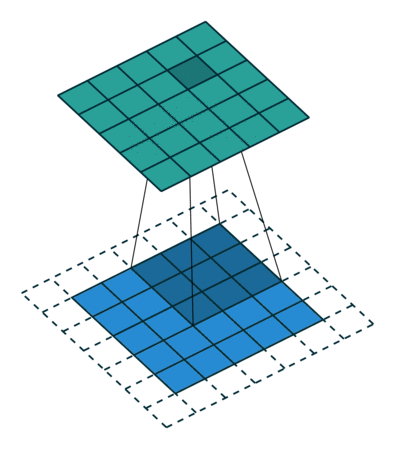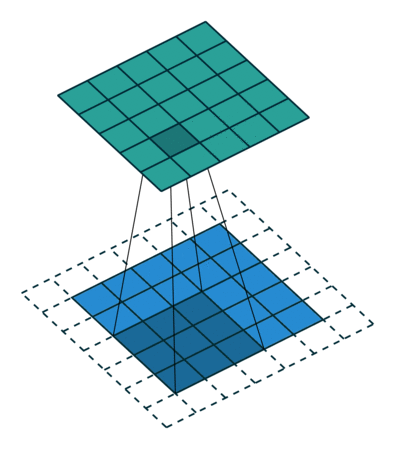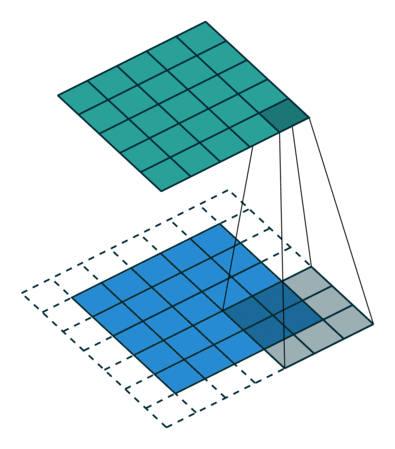
下面是两个 stride = 2 的例子。 左图的参数是:input 2x2,kernel 3x3,padding 0,stride 2,Dilation 1,可以验证 output 5x5。 右图的参数是:input 3x3,kernel 3x3,padding 1,stride 2,Dilation 1,可以验证 output 5x5。
Transposed Convolution 的一个问题是容易生成 Checkerboard Artifacts(具体参见链接[3],它还给出了可交互的图,可以设置不同的 stride 和 kernel size 查看结果是否存在 artifacts)。即,输出图片中会有某些 pixels 的颜色比其他相邻的 pixels 要深,并且呈现棋盘格分布。如下图。

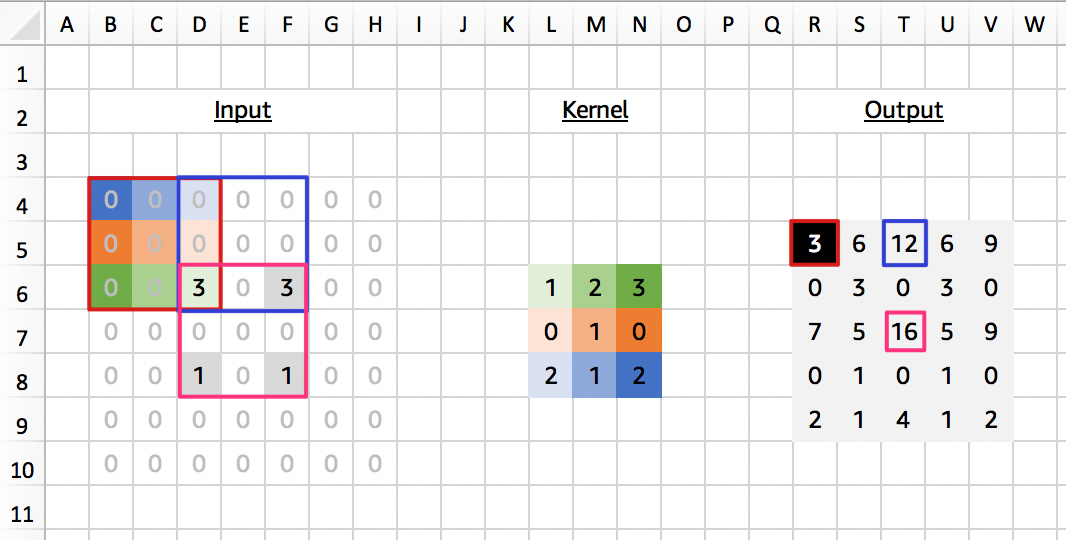
这个问题产生的原因可以用上面例子中的动画(stride = 2 那一行左边那个)来阐述。下图是和它的 dimensions 完全相同的一个有数值的例子。可以看出,输出结果中,中间某些像素位置的数值要明显高于周围的。这是因为,由于此时是在升维,在某些 stride 情况下,某些像素的卷积计算时用到的输入图片中的像素点要多于其他像素位置。如下图所示,红色框中的卷积只用到了一个原始图片的点,而蓝色框的卷积用到了 2 个,粉色框则用到了 4 个。因此,按照这个流程,用到像素点多的位置正好是输出图片中正中心的十字形的像素点。因此结果就会呈现棋盘格的样子。
这种情况只发生在 kernel size 无法被 stride 整除的情况。例如下图中,kernel size = 3, stride = 2。
该问题的解决方法就不多说了,具体参见链接 [5]。
10. Likelihood VS Probability 似然估计 Vs 概率
参考:
- 如何理解似然函数? - 知乎
- Quora问答:https://www.quora.com/What-is-the-difference-between-probability-and-likelihood-1/answer/Jason-Eisner?share=cbfeda82&srid=zDgIt
究竟什么才是 likelihood?它和概率的区别是什么?其实非常容易。其实它俩就是同一个 function $P(x\vert\theta)$ 的两种不同的称呼:
- 如果已知 $\theta$,那么 $P(x\vert\theta)$ 就是关于 $x$ 的函数(给定 $\theta$ ),它被称为概率;
- 如果已知了 $x$,那么 $P(x\vert\mathbf{\theta})$ 就是 $\theta$ 的似然估计,即:已经观察到 $x$ 的情况下,什么样的 $\theta$ 才能最大可能得到观察值 $x$,即 the $\theta$ that maximize $P(x\vert\mathbf{\theta})$
可以参考上面链接的例子。
11. 概率, PDF, CDF
参考
概率衡量的是一个事情发生的可能性。
概率密度函数 Probability Density Function (PDF) 衡量的是一个随机变量落在某个特定取值(区间)上的概率。这个概率数值上就是该变量在PDF 的这个取值(区间)上的积分。因此根据其定义,PDF数值上全都是 >=0 的,并且曲线下面总面积(即总积分)等于1,即整个概率空间的取值。
In a more precise sense, the PDF is used to specify the probability of the random variable falling within a particular range of values, as opposed to taking on any one value. This probability is given by the integral of this variable’s PDF over that range.
The probability density function is nonnegative everywhere, and the area under the entire curve is equal to 1.
而一个随机变量 $X$ 在一个数值 x 上的 Cumulative Distribution Function (CDF) 指的是 $X <= x$ 这个范围内的概率。
通常,离散情况下(discrete),随机变量 X 在某个数值 x 上的PDF就是它的概率值 $P(X=x)$。而连续情况下(continuous),理论上随机变量在任意一个数值上的 PDF 应当是0,即变量没办法精确落在某个数值上,而是它附近的一个很小的区间中。此时 X 的概率 $P(X)$ 就是PDF落在 x 附近的一个极小的区间上的积分了。
通常情况下,我们说“某种概率分布”,其实指的就是它的 PDF。例如,标准形式的高斯分布的 PDF 就是第一章中介绍的正态分布的公式。
12. 方阵矩阵的迹 Trace
方阵的迹(Trace)的定义就是它的对角线元素的和。这个操作经常有很多有用的性质。
(1)加法分解和系数提出
\[tr(A+B)=tr(A)+tr(B) \\ tr(cA)=c \cdot tr(A)\]这些都很显然,通过定义能看出。
(2)三个矩阵相乘的 Trace 的顺序可以调换:
\[tr(ABC)=tr(CAB)=tr(BCA)\]即类似于矩阵顺序从最右边开始回到左边的开头移动。注意:
- 两个矩阵相乘的 trace 不满足这个性质,即很可能 $tr(AB) \neq tr(BA)$。
(3)矩阵的迹可以结合向量相乘
\[tr(\mathbf{ab}^T)=\mathbf{b}^T\mathbf{a}\]注意这个最终结果是一个 scalar 标量,但是 $tr()$ 里面的 $ab^T$ 是矩阵。
这个性质非常有用。同理,这个可以扩展到三个矩阵和向量结合,只需要将其中的 a 或 b 替换为一个向量和矩阵相乘即可:
\[tr(\mathbf{Cab}^T)=\mathbf{b}^T \mathbf{Ca}\]如果 $\mathbf{a=b}$,那么上式就变成
\[tr(\mathbf{Caa}^T)=\mathbf{a}^T \mathbf{Ca}\](4)和特征值的关系
\[tr(A)=\sum_i\lambda_i\]即,矩阵的迹就等于全部的特征向量的和。