Diffusion Models 扩散模型学习
0. Materials
- Diffusion models 详细数学推导: https://scoste.fr/posts/diffusion/
- Diffusion Models From Scratch: 非常棒的一个包含所有基础数学推导的教程
- https://en.wikipedia.org/wiki/Fokker%E2%80%93Planck_equation#
- https://github.com/zoubohao/DenoisingDiffusionProbabilityModel-ddpm-/tree/main: DDPM的一个实现代码,在 CIFAR-10 dataset,比较简单,适合初学使用
1. Diffusion Models 基础
参考:
- An In-Depth Guide to Denoising Diffusion Probabilistic Models – From Theory to Implementation: 详细且全面讲述Diffusion和DDPM流程和数学原理。重点推荐,建议先看。
- Diffusion Models From Scratch: 非常棒并且全面的介绍,包含非常详细的公式推导和简单代码。重点推荐。
- 由浅入深了解Diffusion Model: 知乎中文介绍,不过几乎全部内容都是翻译下面这个Lilian的英文原文。
- What are Diffusion Models? Lilian Weng’s Blog. 大佬作者是目前OpenAI team leader on AI safety. 全文非常清楚详细讲述了 Diffusion 流程。数学很全面,不过缺少一些基础背景,建议看完[1]再看,或者至少结合一起看。另外作者的blog还有很多非常不错的文章值得一读。
- Generative Modeling by Estimating Gradients of the Data Distribution - Yang Song
- Diffusion Models for Image Generation – A Comprehensive Guide: 和 [1] 是同一个作者,只是这篇只总结了Diffusion的一些应用产品和技术等。写于2023年1月。
- Denoising Diffusion-based Generative Modeling: Foundations and Applications: CVPR 2022 Tutorial,有视频,概括性质总结了这个领域的原理,工作和相关进展。而CVPR 2023也有一个非常类似的Tutorial,增加了几个作者以及新进展,基础理论没变化。
1.1 背景
这里主要是翻译 Ref. [1]。
首先看图像生成问题中的一章普通的向日葵图像。

- 图像表示:它首先描述了如何特定的图像(比如一朵向日葵),需要在图像中的像素有正确的配置(它们需要有正确的值)。而这样的图像存在的空间只是整个由(256x256x3)图像空间所能表示的图像集的一小部分。
- 获取子空间点的问题:文章接着指出,如果我们知道如何从这个子空间中获取或采样一个点,我们就不需要构建“生成模型”。然而,当前我们并不知道如何做到这一点。
- 概率分布函数:文章提到,捕捉或建模这个(数据)子空间的概率分布函数(或更准确地说,概率密度函数,PDF)仍然是未知的,而且很可能过于复杂,无法理解。
- 生成模型的需求:正因为如此,我们需要“生成模型”——来弄清楚我们的数据满足的潜在可能性函数。
- PDF的说明:PS部分解释了PDF是一个“概率函数”,表示连续随机变量的密度(可能性),在这个案例中,意味着一个表示图像落在由函数参数定义的特定值范围内的可能性的函数。
- PDF的参数:PPS部分说明,每个PDF都有一组参数,这些参数决定了分布的形状和概率。分布的形状随着参数值的变化而变化。例如,在正态分布的情况下,我们有平均值µ(mu)和方差σ2(sigma),这些控制着分布的中心点和扩散。
The probability distribution function or, more precisely, probability density function (PDF) that captures/models this (data) subspace remains unknown and most likely too complex to make sense.
2. Diffusion Probabilistic Model 扩散概率模型(DPM)
参考:
- DPM 原始论文,2015年:Deep Unsupervised Learning using Nonequilibrium Thermodynamics: https://arxiv.org/pdf/1503.03585
- https://www.zhangzhenhu.com/aigc/扩散概率模型.html#diffusion-probabilistic-model: 中文教程,公式推导非常详细,重点推荐。
- Diffusion Models From Scratch: 非常棒并且全面的介绍,包含非常详细的公式推导和简单代码,不过相对较难理解。重点推荐。
- Step by Step visual introduction to Diffusion Models. - Blog by Kemal Erdem:这篇教程虽然省略了一些推导流程,但是它对基本流程的介绍非常清楚,尤其是给出了每一步对应的最终公式等,同时结合了代码以及例子,非常清楚,重点推荐。而其他文档虽然推导很完善,但是信息量过大,并且没结合代码和网络等。
- Diffusion models from scratch in PyTorch:Youtube 教程,讲了它提供的一个简单的代码实现,也是很清楚的,只是没有公式推导,可以结合下面这个视频一起看,重点推荐
- Diffusion Models: Paper Explanation and Math Explained: Youtube 视频教程,讲解的几个基础推导还是很清楚的,重点推荐。
- What are Diffusion Models? Lilian Wang’s blog,大神总结的,详细但要求高基础。**
- Diffusion Models:生成扩散模型: 中文,总结了多个教程,不过有些比较简单,省略了不少步骤。
2.1 标准流程 Structure
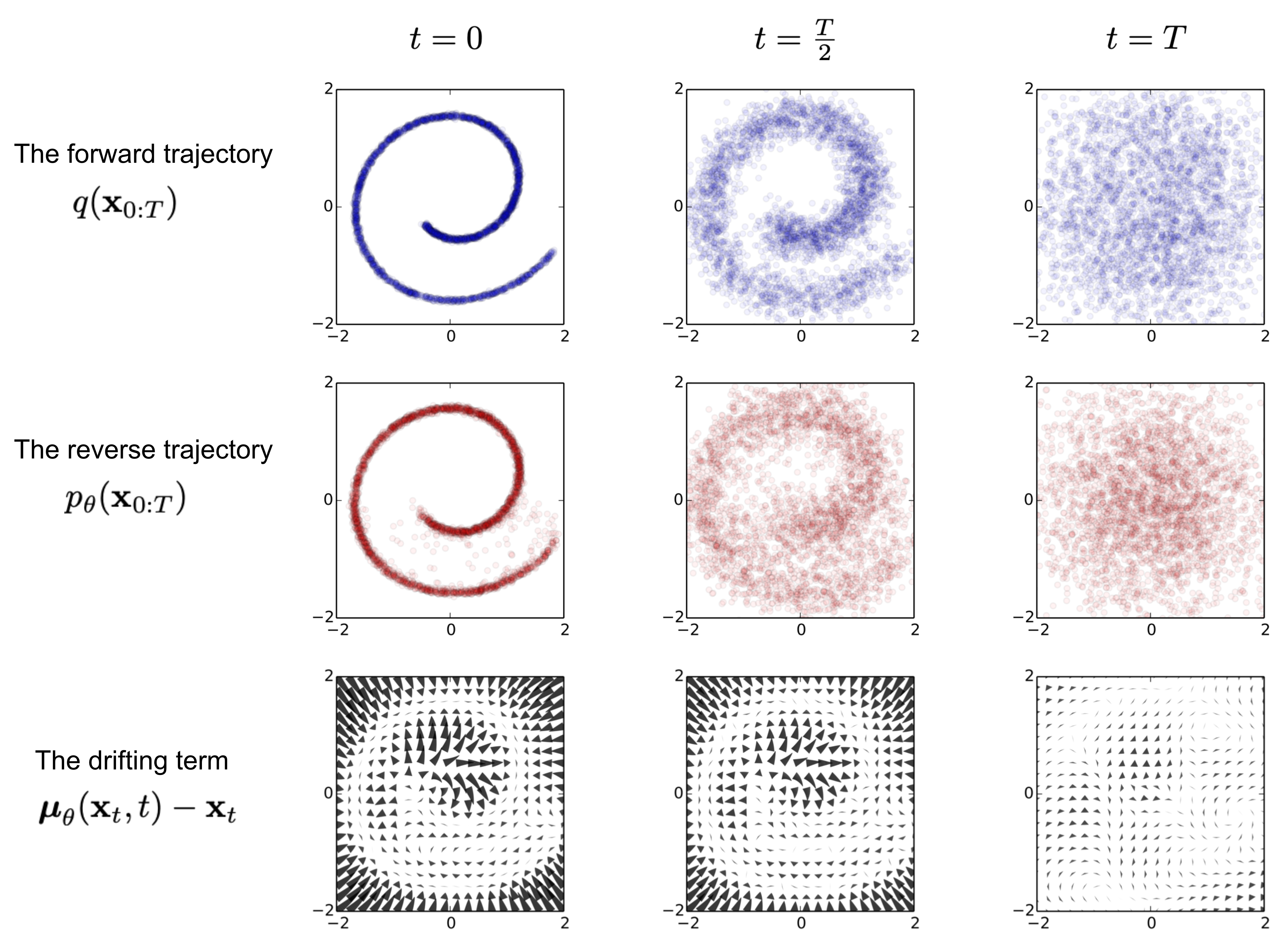
Diffusion Model 的标准流程有两个过程:
- Forward Process: 从原图每一步add noise,每个 \(x_{t}\) 和 \(x_{t-1}\) (以及 \(x_0\)原始图像相关)
- Backward Process: denoise,每个 \(x_{t-1}\) 和 \(x_0\) 相关
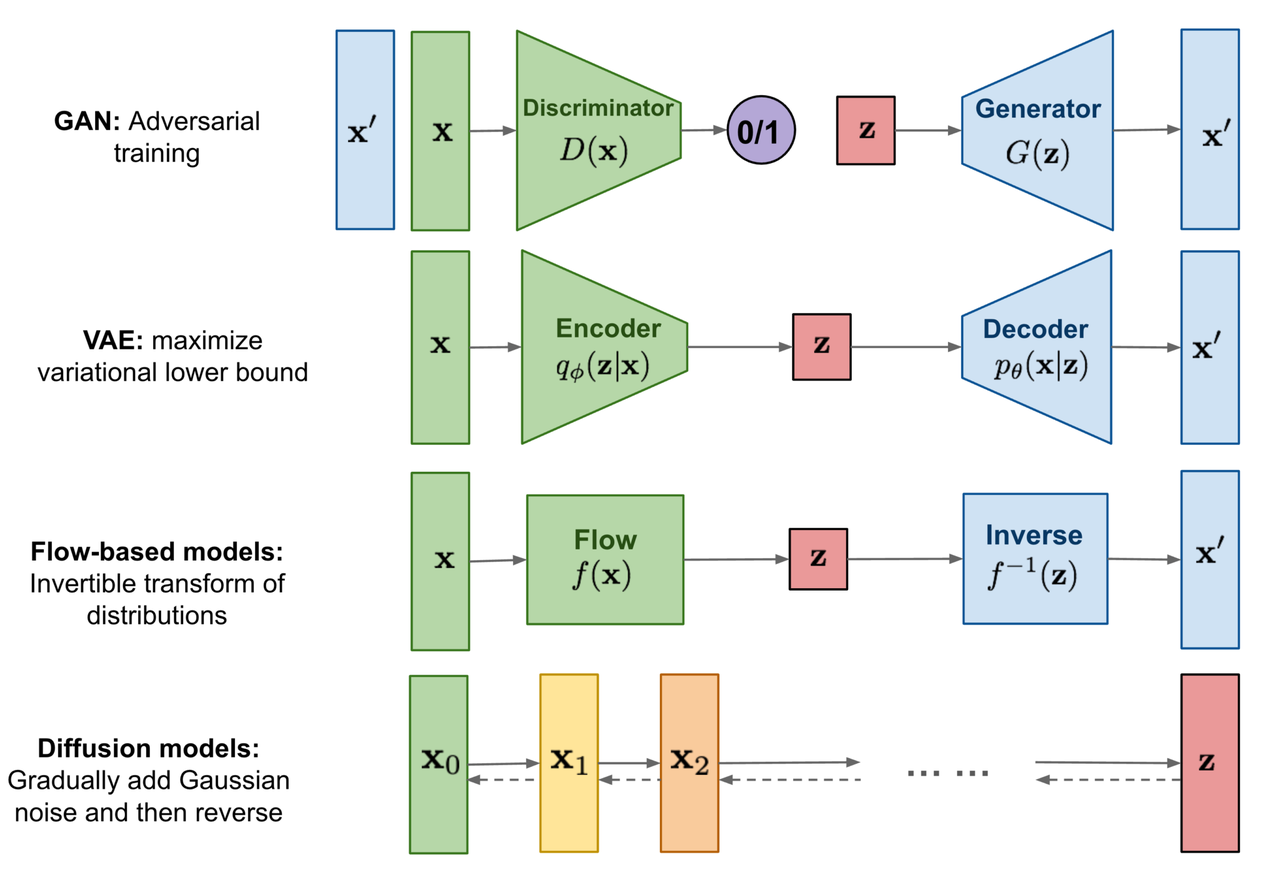
其实不难看出,它和 VAE 流程有类似的地方,两者都是将原始数据通过概率模型的形式给 Encode 到一个 latent representation,然后再用 Decode 还原出原始数据。当然区别有很多:
- Diffusion Model 的 Encode 和 Decode 都分了很多步,而 VAE 可以认为就 1 步。另外,Diffusion 这里 Encode 和 Decode 每一步的数据尺寸和原始数据是一样的,而不像 VAE 那样,encoded latent code \(z\) 通常尺寸远小于原始数据。
- Diffusion 中的前向过程(对应 Encode)的编码器 \(q(x_t\mid x_{t-1})\) 不用网络学习了,而是有一个显式的表达公式,固定为一个高斯的线性变换。这个后续会详细讲。
- 理论上当 \(T \to \infty\) 时, \(x_T\) 是一个正态分布, 即随着 \(T\) 的增大, \(x_T\) 趋近于正态分布。通过为这个线性高斯设定一个小于 1 的的渐系数, 可以使得 \(x_T\) 收敛到一个标准正态分布,即 \(\mathcal{N}(0,\textit{I})\)
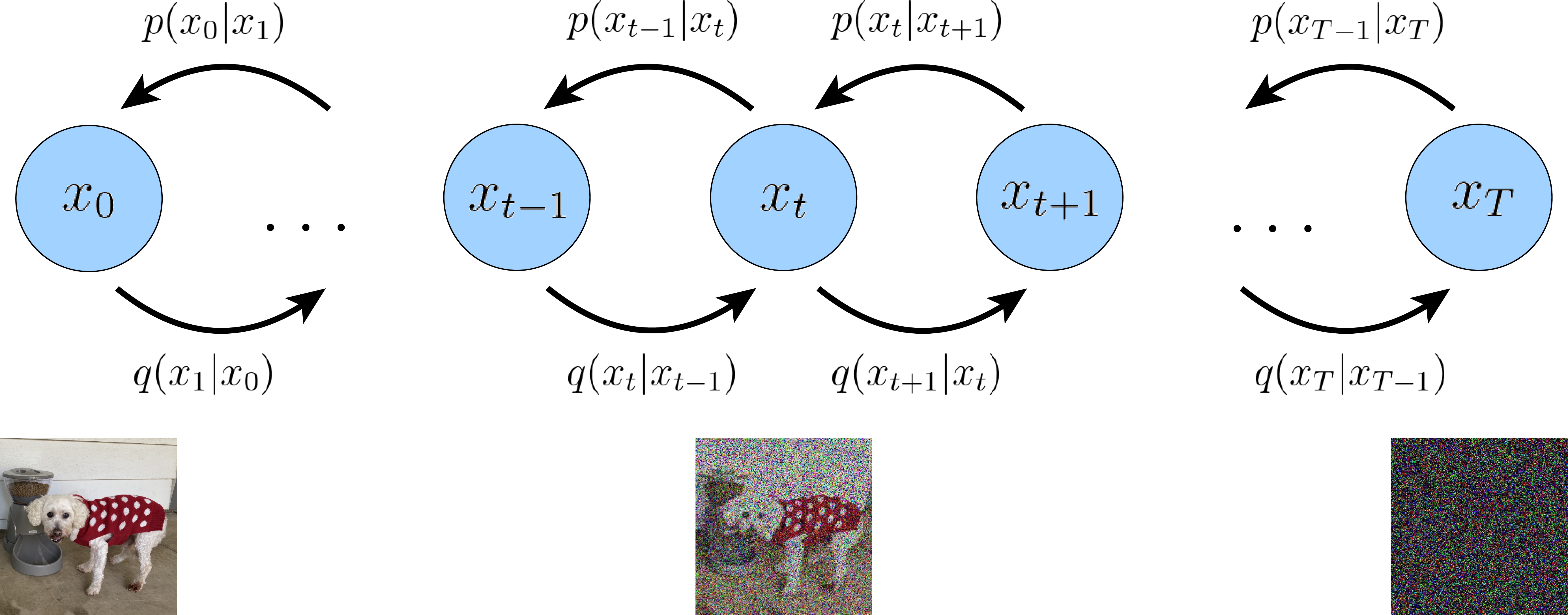
Forward 流程是从原始图片逐渐增加噪声的过程。每一步值 \(x_t\) 仅和此前一步的 \(x_{t-1}\) 相关。 \(x_0\) 是模型的起点变量,它可以代表真实图片的分布(或者说随机变量)。 从它开始,按照这个链式结构逐步的演变成一个标准的高斯分布 \(x_T \sim \mathcal{N}(0,\textit{I})\)。 整个网络的联合概率分布可以表示为(有时候也用 \(p(x_{0:T})\)来表示,这里用了 \(q\) 为了保证一致性):
\[q(x_{0:T}) = q(x_0) \prod_{t=1}^T q(x_t|x_{t-1})\]我们把从左到右的演变过程称为前向过程,因为它是把一个真实图片逐步添加噪声,并最终变成一个纯粹的随机高斯变量 \(x_T\) 的过程,所以也可以称其扩散过程。
如果按照从右到左的顺序,正好是前向扩散过程的逆过程,所以称之为 Backward 逆过程, 它可以从一个纯粹的高斯噪声(标准高斯分布)随机变量 \(x_T\) 逐步演变,最终得到一个真实图片 \(x_0\),这个过程相当于生成了一张新图片,所以也称为(图像)生成过程 ,而这个过程在统计概率学上,本质是从一个联合概率分布进行采样的过程,所以也可以称为采样(sample)过程。 同样,可以按照从右到左的顺序对联合概率进行链式分解
\[p(x_{0:T}) = p(x_T) \prod_{t=T}^1 p(x_{t-1}|x_{t})\]2.2 Forward Process 从原图增加噪声
代表真实图像 \(x_0\) 的真实概率分布 \(p(x_0)\) 的概率密度函数是不知道的, 但我们能得到一批真实的图像样本,也就是我们有 \(x_0\) 的观测样本, 此时 \(x_0\) 是已知观测值, \(x_{1:T}\) 是未知的隐变量, 这时整个马尔科夫网络的联合概率变成了一个条件概率:
\[q(x_{1:T}|x_0) = q(x_1|x_0) \prod_{t=2}^T q(x_t|x_{t-1}) = \prod_{t=1}^T q(x_t|x_{t-1})\]另外, DPM 中又假设了,每一个 \(x_t\) 都是一个高斯变量, 前向过程每一个步骤的编码器 \(q(\mathbf{x}_t \vert\mathbf{x}_{t-1})\) 是一个线性高斯变换, 所谓线性高斯变换是指 \(x_t\) 的均值和 \(x_{t-1}\) 的值是线性关系。
DPM 论文中,直接定义 \(q(\mathbf{x}_t \vert\mathbf{x}_{t-1})\) 的方差是和 \(x_{t-1}\) 无关的量 \(\beta_t I\),其中 \(0 \lt \beta_1 \lt \beta_2 \lt \dots \beta_T \lt 1\)。这么做的意义:前期方差较小,添加的噪声少,扩散速度慢;随着方差逐步加大,添加的噪声越来越多,扩散的速度加快。 \(\beta_t\) 作为一个超参数存在,人工指定它的值。
同时,论文中还指定 \(q(\mathbf{x}_t \vert\mathbf{x}_{t-1})\) 的均值 \(\mu_{x_t}\) 和 \(x_{t-1}\) 是线性关系,表示为 \(\mu_{x_t} = \sqrt{1 - \beta_t} \mathbf{x}_{t-1}\)
总结就是这样:
\[\large q(\mathbf{x}_t \vert\mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t; \sqrt{1 - \beta_t} \mathbf{x}_{t-1}, \beta_t \mathbf{I})\]即,当前的 \(x_t\) 的值是上一步 \(x_{t-1}\) 的一部分再加上一个噪声 \(\sqrt{\beta_t} \boldsymbol{\epsilon}\):
\[\mathbf{x}_t = \sqrt{1 - \beta_t} \mathbf{x}_{t-1} + \sqrt{\beta_t}\boldsymbol{\epsilon}\]其中:
- \(\boldsymbol{\epsilon}\) 是纯 \(\mathcal{N}(0,\textit{I})\) 高斯噪声
- t 是 timestep (indices),通常是 \(0,1,...,T-1\) 的整数,T 是 total timesteps 例如 100。越大意味着添加噪声的步数越多。
- 步长 step size 是由一个 variable schedule \(\beta_t\) 控制,\(\beta_t\) 在默认的 DPM 模型中是提前定义的常量,是 [start,end] 区间中的等分的小数,例如 [0.0001, 0.02] 区间中平分成 T 份的等分小数,长度和 t 相等。不过实际应用中通常会用 non-linear 生成形式,具体定义方法后面专门的介绍。可以看出,刚开始 \(\beta_t\)通常很小,因此增加的噪声也很少,后期就会越来越大。其他一些变种方法中 \(\beta_t\) 也可以被学习。
幸运的是, \(x_t\) 有一个显式的仅和 \(x_0\) 有关表达结果,而无需使用网络来预测它。
继续推导可以得到的表达式。定义 \(\alpha_t = 1 - \beta_t\) 以及累计积 \(\bar{\alpha}_t = \prod_{i=1}^t \alpha_i\) 之后得到:
\[\begin{aligned}\mathbf{x}_t &= \sqrt{\alpha_t}\mathbf{x}_{t-1} + \sqrt{1 - \alpha_t}\boldsymbol{\epsilon}_{t-1} & \text{ where } \boldsymbol{\epsilon}_{t-1}, \boldsymbol{\epsilon}_{t-2}, \dots \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \\ &= \sqrt{\alpha_t \alpha_{t-1}} \mathbf{x}_{t-2} + \sqrt{\alpha_t(1-\alpha_{t-1})}\epsilon_{t-2} + \sqrt{1-\alpha_{t}}\epsilon_{t-1} \\ &= \sqrt{\alpha_t \alpha_{t-1}} \mathbf{x}_{t-2} + \sqrt{1 - \alpha_t \alpha_{t-1}} \bar{\boldsymbol{\epsilon}}_{t-2} & \text{ where } \bar{\boldsymbol{\epsilon}}_{t-2} \text{ merges two Gaussians} \\&= \dots \\&= \sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon} \end{aligned}\]上面第 2-3 行用到了高斯分布的一个性质:两个高斯分布 \(\mathcal{N}(\mathbf{0}, \sigma_1^2\mathbf{I})\) 以及 \(\mathcal{N}(\mathbf{0}, \sigma_2^2\mathbf{I})\) 相加(或称为合并)就相当于一个新的高斯分布 \(\mathcal{N}(\mathbf{0}, (\sigma_1^2 + \sigma_2^2)\mathbf{I})\)。对于上面第2行的第2项,本来是 \(\sqrt{\alpha_t(1-\alpha_{t-1})}\epsilon_{t-2} + \sqrt{1-\alpha_{t}}\epsilon_{t-1}\) 这样的两个正态分布相加,合并后就相当于一个正态分布,其方差就是两个系数的平方和,正好就是 \(1-\alpha_{t}\alpha_{t-1}\)。然后带入到上面公式中时需要用标准差,即要开根号,就是上面第3行了。而中间省略的地方是,显然可以按照规律一直计算到 t = 0,不难看出大部分项都被消掉了。
因此,最终结果很简洁:
\[q(\mathbf{x}_t \vert \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_t; \color{red} {\sqrt{\bar{\alpha}_t} \mathbf{x}_0, (1 - \bar{\alpha}_t)\mathbf{I}} \color{black} ) \\ \mathbf{x}_t = \color{red} {\sqrt{\bar{\alpha}_t} \mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t} \boldsymbol{\epsilon}}\]其中 \(\bar{\alpha}_t\) 是累计积 \(\bar{\alpha}_t = \prod_{i=1}^t \alpha_i\) 以及 \(\alpha_t = 1 - \beta_t\)
这是一个图例说明 Forward Process 的流程,只列出了几步:
常见问题和解答
- 为什么要有系数 ?
前向扩散过程是希望 \(x_t\) 渐进趋近于标准正态分布,即均值趋近于 0, 方差趋近于单位方差 \(I\) ,并且 \(x_t\) 只和它的上一步 \(x_{t-1}\) 有关,同时两者是线性高斯变化,也就是两者的关系必然是某个系数乘上 \(x_{t-1}\) 的线性关系。
- \(\alpha_t\) 为什么小于 1 ?
因为需要 \(\mu_{x_t} \to 0\),所以这个系数必然是小于 1 的。
- 什么均值前的系数要有根号?即,为何是 \(\mu_{x_t} = \sqrt{\alpha_t} x_{t-1}\) 而不是 \(\mu_{x_t} = \bar{\alpha}_t x_{t-1}\)?
这是因为,我们要维持在理想情况下,整个前向扩散过程的均值和方差不变。即,如果初始的分布 \(x_0 \sim \mathcal{N}(0,\textit{I})\) 时,那么会有任意的 \(x_t\) 的分布会满足 \(\mu_{x_t} = 0\) ,也要满足 \(\Sigma_{x_t} = I\)。
这里不妨验证一下方差和均值的变化。首先是均值:
\[E(x_t) = E(\sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}) = \sqrt{\bar{\alpha}_t}E(\mathbf{x}_0) + \sqrt{1 - \bar{\alpha}_t}E(\epsilon) = 0\]这里第 2 项的噪声的期望就是 0,因为它就是标准正态分布的噪声去,其均值是 0。
接着是方差。
\[Var(x_t) = Var(\sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}) = \bar{\alpha}_t Var(x_0) + (1-\bar{\alpha}_t)Var(\epsilon) = \bar{\alpha}_t + (1 - \bar{\alpha}_t) = 1\]因此,不难发现,用根号下的 \(\sqrt{\bar{\alpha}_t}\) 是为了满足方差稳定。而如果不用根号,那么方差就会变为
\[Var(x_t) = Var({\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}) = \bar{\alpha}_t^2 Var(x_0) + (1-\bar{\alpha}_t)Var(\epsilon) = \bar{\alpha}_t^2 + (1 - \bar{\alpha}_t)\]这个方差将不是1,并且会小于 1(因为 \(\bar{\alpha}_t < 1\))。因此随着 t 的增大,这个方差将变小的特别快。这个很不好,因为它意味着原始的数据信号在前向过程中消失的太快了(the original image vanishes (its signal becomes tiny) too early in the diffusion steps)。
例如,当 t = 0 时候,由于 \(\bar{\alpha}_t\) 是所有的 \(1 - \beta_t\) 的乘积,而 \(\beta_t\) 初始时非常接近于 0, 因此 \(\bar{\alpha}_t\) 是约等于 1。而随着 \(t\) 增大,\(\bar{\alpha}_t\) 很快就会变得远小于 1(因为是很多个小数 \(1 - \beta_t\) 的乘积)。比如是 0.001 吧。此时 \(x_t = \bar{\alpha}_t\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}\) 相当于使用了 \(0.001\mathbf{x}_0\) 而不是平方根即约 \(0.03\mathbf{x}_0\)。这说明, \(x_t\) 的来源中,来自 \(x_0\) 的信号部分将迅速减少,而来自 noise 的部分将占据非常大的比重(the noise dominates almost immediately)。这就意味着,在早期的增加噪声的过程中,噪声所占的比重将迅速增大,从而使得结果变得过于 noisy,而 learning signal 将很快消失(因为来自 \(x_0\) 的这部分太少了)。而如果使用的是带根号的均值 \(\sqrt{\alpha_t}\),因为它保持方差尽量不变,因此它会类似线性的逐步平稳增加噪声。
有关 \(\beta_t\) 的实现
实际代码中通常是这样生成的
linear_start = 0.00085
linear_end = 0.012
n_steps = 1000
beta = torch.linspace(linear_start ** 0.5, linear_end ** 0.5, n_steps, dtype=torch.float64) ** 2
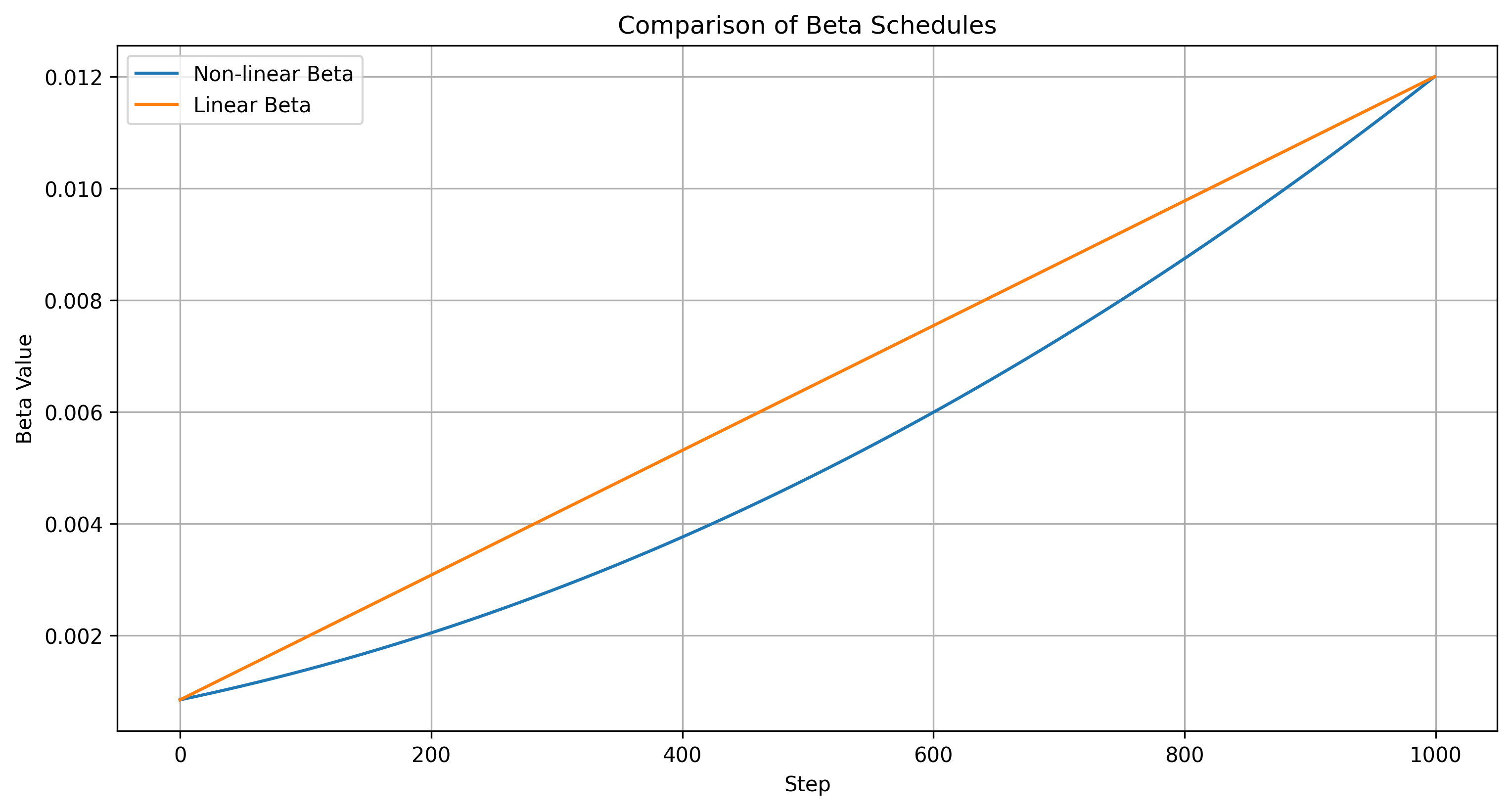
注意最后这一步,它是首先对两头取 square root 平方根后,接着在两者之间平均取 n_steps 个值,最后再平方。显然,这样的结果是一个 non-linear 非线性的取值(其实就是个二次函数分布 quadratic),而不是常规的那种线性的(即这样 torch.linspace(linear_start, linear_end, n_steps) )。不难看出,区间两头不变依然是 linear_start 和 linear_end。那么,这样的好处是什么?
下面是来自 Claude AI 的回答:
This non-linear spacing can be beneficial in diffusion models because:
- It allows for finer control over the noise schedule in the early steps of the diffusion process, where small changes can have a significant impact.
- It provides a smoother transition between the low-noise and high-noise regimes of the diffusion process.
- This particular spacing has been found empirically to work well in many diffusion model implementations.
总结来说,这种non-linear的分布会使得开始时变化慢,后期变化快(e.g., closer to each other at one end and further apart at the other end),这种分布对于很多应用都有用,尤其是常见的 learning rate schedules 和 beta schedules in diffusion models。
下面是我画的对比两种分布的曲线图,Non-Linear分布前期的变化较缓慢(梯度小),后期才逐渐变大。
2.3 Reverse (or Backward) Process 逆向过程,从噪声恢复原图
Backward/Reverse Diffusion Process 就是反向了上面的过程,即我们想从一个纯高斯噪声 \(\mathbf{x}_T \sim \mathcal{N}(\mathbf{0}, \mathbf{I})\) 中逐步减去噪声并最终还原出原始图像 \(x_0\)。
前面已经提到了,逆向过程中的联合概率分布是
\[p(x_{0:T}) = p(x_T) \prod_{t=T}^1 p(x_{t-1}|x_{t})\]不过很难计算这个 \(p(x_{t-1}\mid x_{t})\) 的值,它不存在解析解。于是,类似此前的 VAE 的流程,不妨用一个神经网络来预测这个条件概率分布。接下来就用 VAE 中的 ELBO 最大证据下界的思想来说明如何学习它。
2.3.1 下界函数 ELBO
我们知道学习一个概率分布的未知参数的常用算法是极大似然估计, 极大似然估计是通过极大化观测数据的对数概率(似然)实现的。 在这里,整个网络的联合概率分布是 \(p(x_{0:T})\) ,其中,我们只有 \(x_0\) 的观测数据(样本) ,没有 \(x_{1:T}\) 的观测样本, 因此我们极大化的是边缘分布 \(p(x_0)\) ,而不是联合分布 \(p(x_{0:T})\) 。边缘分布可以通过边际化得到
\[p(x_0) = \int p(x_{0:T}) dx_{1:T}\]即,为了计算似然估计 \(x_0\) 的最大概率,就要遍历全部可能的 \(x_{1:T}\) 的结果。不难发现,这也是 VAE 中要优化的对象,当时是通过 ELBO 下界函数来推导的(参见我的另一个文档:Generative Models 1: VAE )。这里也用同样的方法推导一下扩散模型的 ELBO 如何。
根据最大似然理论,已知一批观测样本 \(x_0\) ,我们想要计算它的最大可能的概率:
\[\begin{aligned}{\log p(x_0)}&= {\log \int p(x_{0:T}) dx_{1:T}}\\&= {\log \int \frac{p(x_{0:T})q(x_{1:T}|x_0)}{q(x_{1:T}|x_0)} dx_{1:T}} \ \ \ ; \text{分子分布乘以相同项}\\ &= {\log \mathbb{E}_{q(x_{1:T}|x_0)}\left[\frac{p(x_{0:T})}{q(x_{1:T}|x_0)}\right]} \ \ \ ; \text{根据期望定义}\\&\geq {\mathbb{E}_{q(x_{1:T}|x_0)}\left[\log \frac{p(x_{0:T})}{q(x_{1:T}|x_0)}\right]} \ \ \ ;根据\text{Jensen}不等式: 任意凹函数有\varphi(E(x)) >= E(\varphi(x)) \\ &= {\mathbb{E}_{q(x_{1:T}|x_0)}\left[\log \frac{p(x_T)\prod_{t=1}^{T}p_{\theta}(x_{t-1}|x_t)}{\prod_{t = 1}^{T}q(x_{t}|x_{t-1})}\right]} \ \ \ ;多变量的联合概率分布的贝叶斯展开\\&= {\mathbb{E}_{q(x_{1:T}|x_0)}\left[\log \frac{p(x_T)p_{\theta}(x_0|x_1)\prod_{t=2}^{T}p_{\theta}(x_{t-1}|x_t)}{q(x_T|x_{T-1})\prod_{t = 1}^{T-1}q(x_{t}|x_{t-1})}\right]} \ \ \ ;乘积中提出来一项 \\&= {\mathbb{E}_{q(x_{1:T}|x_0)}\left[\log \frac{p(x_T)p_{\theta}(x_0|x_1)\prod_{t=1}^{T-1}p_{\theta}(x_{t}|x_{t+1})}{q(x_T|x_{T-1})\prod_{t = 1}^{T-1}q(x_{t}|x_{t-1})}\right]} \ \ \ ; 切换了分子中的连乘积的下标符号\\&= {\mathbb{E}_{q(x_{1:T}|x_0)}\left[\log \frac{p(x_T)p_{\theta}(x_0|x_1)}{q(x_T|x_{T-1})}\right] + \mathbb{E}_{q(x_{1:T}|x_0)}\left[\log \prod_{t = 1}^{T-1}\frac{p_{\theta}(x_{t}|x_{t+1})}{q(x_{t}|x_{t-1})}\right]} \ \ \ ; 展开\\&= {\mathbb{E}_{q(x_{1:T}|x_0)}\left[\log p_{\theta}(x_0|x_1)\right] + \mathbb{E}_{q(x_{1:T}|x_0)}\left[\log \frac{p(x_T)}{q(x_T|x_{T-1})}\right] + \mathbb{E}_{q(x_{1:T}|x_0)}\left[ \sum_{t=1}^{T-1} \log \frac{p_{\theta}(x_{t}|x_{t+1})}{q(x_{t}|x_{t-1})}\right]} \ \ \ ; 继续展开\\&= {\mathbb{E}_{q(x_{1:T}|x_0)}\left[\log p_{\theta}(x_0|x_1)\right] + \mathbb{E}_{q(x_{1:T}|x_0)}\left[\log \frac{p(x_T)}{q(x_T|x_{T-1})}\right] + \sum_{t=1}^{T-1}\mathbb{E}_{q(x_{1:T}|x_0)}\left[ \log \frac{p_{\theta}(x_{t}|x_{t+1})}{q(x_{t}|x_{t-1})}\right]} \ \ \ ;求和的期望等于期望的求和\\&= \mathbb{E}_{q(x_{1}|x_0)}\left[\log p_{\theta}(x_0|x_1)\right] + \mathbb{E}_{q(x_{T-1}, x_T|x_0)}\left[\log \frac{p(x_T)}{q(x_T|x_{T-1})}\right] + \sum_{t=1}^{T-1}\mathbb{E}_{q(x_{t-1}, x_t, x_{t+1}|x_0)}\left[\log \frac{p_{\theta}(x_{t}|x_{t+1})}{q(x_{t}|x_{t-1})}\right] \ \ \ ; 更新了期望的计算范围\\ &= {\underbrace{\mathbb{E}_{q(x_{1}|x_0)}\left[\log p_{\theta}(x_0|x_1)\right]}_\text{reconstruction term}} - {\underbrace{ KL({q(x_T|x_{T-1})}||{p(x_T)})}_\text{prior matching term}} - {\sum_{t=1}^{T-1}\underbrace{\mathbb{E}_{q(x_{t-1}, x_{t+1}|x_0)}\left[ KL( {q(x_{t}|x_{t-1})}{p_{\theta}(x_{t}|x_{t+1})})\right]}_\text{consistency term}}\end{aligned}\]解释:
- 第3-4行是将联合概率分布 \(p(x_{0:T})\) 和 \(q(x_{1:T}\mid x_0)\) 展开成条件概率的乘积形式了。例如 \(p\) 的结果很简单 \(p(x_{0:T})=p(x_T)\prod_{t=1}^{T}p_{\theta}(x_{t-1}\mid x_t)\),这是因为 \(p()\) 函数即逆向过程中, \(x_t\) 只和 \(x_{t+1}\) 相关,和后面的 \(x_{t+2}, x_{t+3} …\) 等无关,因此条件概率可以简化了。另一个 \(q\) 的展开同理,在正向过程中, \(x_t\) 只和 \(x_{t-1}\) 相关,和其他无关,因此也能简化。
- 倒数第3行到倒数第2行的区别是更新了期望的概率的范围。比如,倒数第3行的第1项是从 \(q(x_{1:T}\mid x_0)\) 的范围变成了 \(q(x_1\mid x_0)\),这是因为,这一项按照期望的计算公式展开:
即,我们要计算的是这里方括号内部的函数 \(f(x_{1:T})=\ln p_{\theta}(x_0\mid x_1)\) 的期望,但是是在整个 \(x_{1:T}\) 的分布上计算。而 \(\ln p_{\theta}(x_0\mid x_1)\) 显然只和 \(x_1\) 这一个未知数相关,和其他的 \(x_2, …\) 等等都无关。因此,利用概率的性质,可以去掉积分范围中的和未知数无关的量。下面是来自 ChatGPT 的解释:

倒数第3行的其他两项也同理,都是去掉了和待计算的函数的期望中无关的未知数,从而改变了积分的范围。
2.3.2 推导
我们没办法直接估计 \(p(\mathbf{x}_{t-1} \vert \mathbf{x}_t)\) 的值,因为这其实就相当于用模型直接预测整个数据集的全部数据,显然不可能。因此,我们必须要再找到一个 \(\mathbf{x}_{t-1}\) 的分布规律,然后来预测这个规律,从而逐步推导出最终的原始图像 \(x_0\)。这里我们直接可以假定,反向过程的 \(\mathbf{x}_{t-1}\) 也会满足某一个和 \(\mathbf{x}_{t}\) 和步数 \(t\) 相关的 Gaussian 分布:
\[p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t) = \mathcal{N}(\mathbf{x}_{t-1}; \boldsymbol{\mu}_\theta(\mathbf{x}_t, t), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t))\]这是因为:
- 根据 DDPM 原文,It is noteworthy that the reverse conditional probability is tractable when conditioned on \(x_0\)。即,因为 Reverse Process 是 Forward Process 的逆过程,因此从 \(x_t\) 和 \(x_0\) 一定能反向推导出 \(x_{t-1}\)。
- 理论上讲,如果前向过程每一步添加的 noise 非常小(即 \(\beta_t\) 很小),那么反向的概率 \(q(x_{t-1} \mid x_t)\) 也会非常接近一个 Gaussian。
于是,不妨表达如下:
\[q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_{t-1}; \color{blue}{\tilde{\boldsymbol{\mu}}}(\mathbf{x}_t, \mathbf{x}_0), \color{red}{\tilde{\beta}_t} \mathbf{I})\]因此,接下来就是要知道这个 Gaussian 的均值和方差可以表达成什么形式。
继续推导。基于贝叶斯公式:
\[\begin{aligned} q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) &= \frac{ q(\mathbf{x}_{t}, \mathbf{x}_{t-1}, \mathbf{x}_0) }{ q(\mathbf{x}_{t},\mathbf{x}_{0})} \\ &= q(\mathbf{x}_t \vert \mathbf{x}_{t-1}, \mathbf{x}_0) \frac{ q(\mathbf{x}_{t-1}, \mathbf{x}_0) }{ q(\mathbf{x}_t ,\mathbf{x}_0)} \\ &= q(\mathbf{x}_t \vert \mathbf{x}_{t-1}, \mathbf{x}_0) \frac{ q(\mathbf{x}_{t-1} \vert \mathbf{x}_0) }{ q(\mathbf{x}_t \vert \mathbf{x}_0) } \\ &\propto \exp \Big(-\frac{1}{2} \big(\frac{(\mathbf{x}_t - \sqrt{\alpha_t} \mathbf{x}_{t-1})^2}{\beta_t} + \frac{(\mathbf{x}_{t-1} - \sqrt{\bar{\alpha}_{t-1}} \mathbf{x}_0)^2}{1-\bar{\alpha}_{t-1}} - \frac{(\mathbf{x}_t - \sqrt{\bar{\alpha}_t} \mathbf{x}_0)^2}{1-\bar{\alpha}_t} \big) \Big) \\ &= \exp \Big(-\frac{1}{2} \big(\frac{\mathbf{x}_t^2 - 2\sqrt{\alpha_t} \mathbf{x}_t \color{blue}{\mathbf{x}_{t-1}} \color{black}{+ \alpha_t} \color{red}{\mathbf{x}_{t-1}^2} }{\beta_t} + \frac{ \color{red}{\mathbf{x}_{t-1}^2} \color{black}{- 2 \sqrt{\bar{\alpha}_{t-1}} \mathbf{x}_0} \color{blue}{\mathbf{x}_{t-1}} \color{black}{+ \bar{\alpha}_{t-1} \mathbf{x}_0^2} }{1-\bar{\alpha}_{t-1}} - \frac{(\mathbf{x}_t - \sqrt{\bar{\alpha}_t} \mathbf{x}_0)^2}{1-\bar{\alpha}_t} \big) \Big) \\ &= \exp\Big( -\frac{1}{2} \big( \color{red}{(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}})} \mathbf{x}_{t-1}^2 - \color{blue}{(\frac{2\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{2\sqrt{\bar{\alpha}_{t-1}}}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0)} \mathbf{x}_{t-1} \color{black}{ + C(\mathbf{x}_t, \mathbf{x}_0) \big) \Big)} \end{aligned}\]说明:
- 第 1-3 行就是使用贝叶斯公式;
- 第4行就是将第3行的 Gaussian 展开成标准形式 \(g(x)=\frac{1}{(2\pi\sigma^2)^\frac{1}{2}} \exp(-\frac{(x-\mu)^2}{2\sigma^2})\) ,去掉了前面的系数(上面的 \(\propto\) 符号表示正比于),然后用前面 Forward Process 推导出的表达式带入:
例如第4行第1项就是:
\[q(\mathbf{x}_t \vert \mathbf{x}_{t-1}, \mathbf{x}_0)=q(\mathbf{x}_t \vert \mathbf{x}_{t-1})\propto = \exp{(-\frac{1}{2}\frac{(\mathbf{x}_t-\sqrt{\alpha_t}\mathbf{x}_{t-1})^2}{\beta_t})}\]另外两项同理。这里又使用了 \(e^a e^b = e^{a+b}\)的性质,将第3行的分母上的 \(q(\mathbf{x}_t \mid \mathbf{x}_0)\) 转成了第4行最后一项的减法。
- 第5行就是将第4行展开;
- 最后1行就是简单合并成二次方的形式 \(ax^2 + bx + c\) 这样,合并成 \(\mathbf{x}_{t-1}\) 的二次表达式。
- \(C(\mathbf{x}_t, \mathbf{x}_0)\)是和 \(x_{t-1}\)无关的量,可以忽略。
继续化简。使用高斯分布的标准表达式 \(g(x)=\exp(-\frac{(x-\mu)^2}{2\sigma^2})\) 来展开 \(q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0 ) = \mathcal{N}(\color{blue}{\tilde{\boldsymbol{\mu}}}(\mathbf{x}_t, \mathbf{x}_0), \color{red}{\tilde{\beta}_t} \mathbf{I})\) 得到:
\[q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0 ) \propto \exp (-\frac{1}{2}\frac{(\mathbf{x}_{t-1}-\tilde{\boldsymbol{\mu}}(\mathbf{x}_t, \mathbf{x}_0))^2}{\tilde{\beta}_t})\]然后对比该式子和前面推导的式子的最后1行的 \(\mathbf{x}_{t-1}^2\) 项前面的系数,两者肯定要相等,因此不难看出:
\[\begin{aligned}\tilde{\beta}_t = \sigma^2 &= 1/(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}}) = 1/(\frac{\alpha_t - \bar{\alpha}_t + \beta_t}{\beta_t(1 - \bar{\alpha}_{t-1})})= \color{blue}{\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t} \end{aligned}\]接着对比 \(\mathbf{x}_{t-1}\) 项的系数,同样两者要相等:
\[\begin{aligned} \tilde{\boldsymbol{\mu}}_t (\mathbf{x}_t, \mathbf{x}_0) &= (\frac{\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1} }}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0) * \sigma^2 \\ &= (\frac{\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1} }}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0)/(\frac{\alpha_t}{\beta_t} + \frac{1}{1 - \bar{\alpha}_{t-1}}) \\&= (\frac{\sqrt{\alpha_t}}{\beta_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1} }}{1 - \bar{\alpha}_{t-1}} \mathbf{x}_0) \color{green}{\frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t} \\&= \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1 - \bar{\alpha}_t} \mathbf{x}_0 \end{aligned}\]再利用前面 Forward Process 的表达式,可以反推出用 \(x_t\) 表示 \(x_0\)
\[\mathbf{x}_0 = \frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}_t)\]带入上式后得到最终表达结果:
\[\begin{aligned}\tilde{\boldsymbol{\mu}}_t&= \frac{\sqrt{\alpha_t}(1 - \bar{\alpha}_{t-1})}{1 - \bar{\alpha}_t} \mathbf{x}_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1 - \bar{\alpha}_t} \frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}_t) \\&= \color{red}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_t \Big)}\end{aligned}\]可以看出,\(\mathbf{x}_{t-1}\) 就只和 \(\mathbf{x}_{t}\)以及 \(\epsilon_t\) 相关了。而 \(\mathbf{x}_{t}\) 可以用 Forward Process 公式计算出来。于是,我们可以设计一个网络来预测每一步的噪声 \(\epsilon_t\),然后即可从 \(\mathbf{x}_{t}\) 开始一步步的还原出最终的 \(\mathbf{x}_{0}\)。
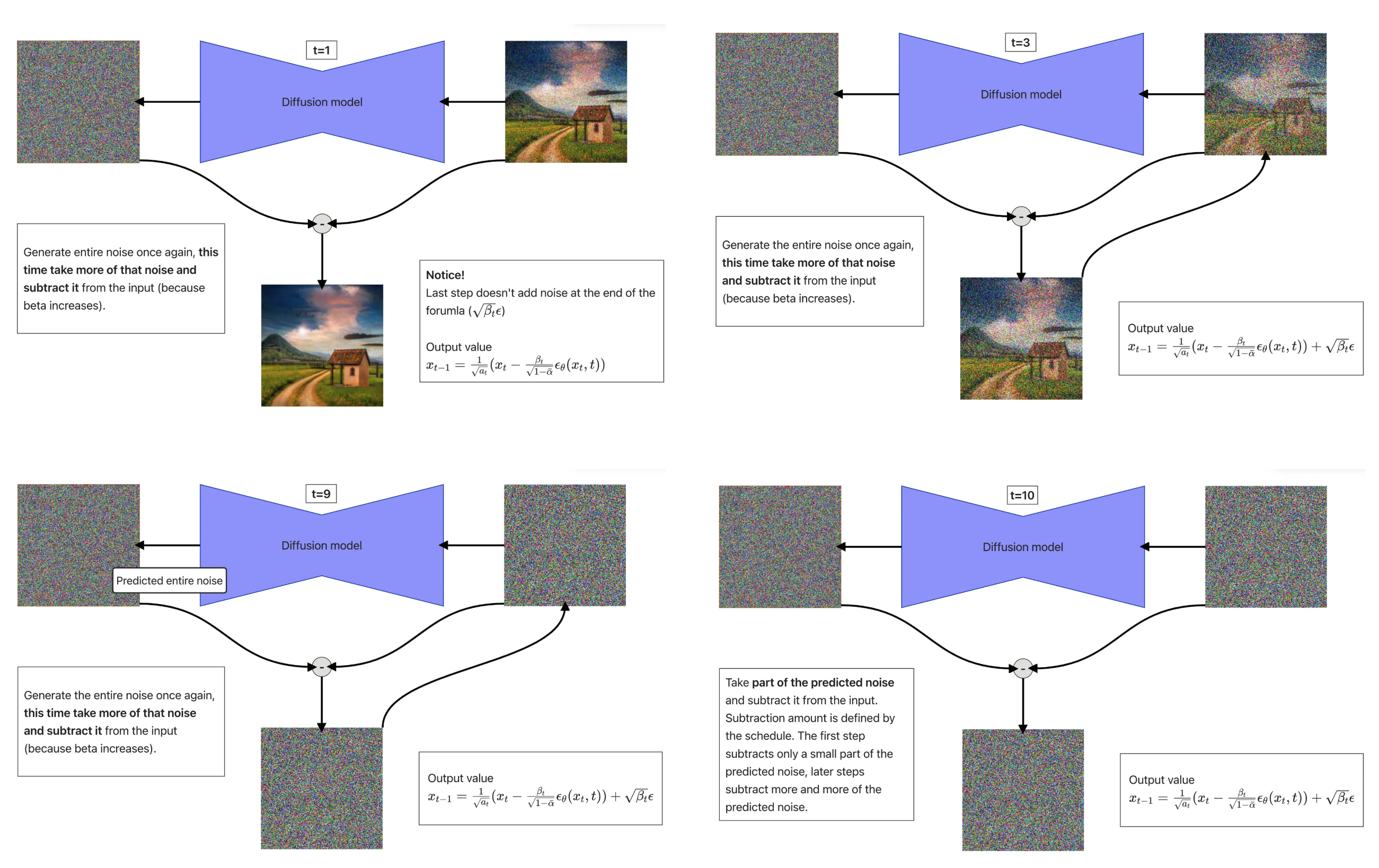
一个图例 (Ref: https://arxiv.org/pdf/1503.03585):
下面图例说明了 Reverse Process 的流程,从 t = 10 开始到 t=1 结束。注意最后这一步不需要最后的 variance 项。
2.4 Training Loss 训练目标损失函数
参考:
其实在 Reverse Process 中,我们的目标是估计 \(\mathbf{x}_{t-1}\) 的分布 \(p_\theta(\mathbf{x}_{t-1} \vert \mathbf{x}_t) = \mathcal{N}(\mathbf{x}_{t-1}; \boldsymbol{\mu}_\theta(\mathbf{x}_t, t), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t))\) 。于是,一种直接想法是,我们用一个网络来估计 \(\tilde{\boldsymbol{\mu}}_t\),不妨记网络的预测值是 \(\boldsymbol{\mu}_\theta\) 。
回顾上一节得到的表达式 \(\tilde{\boldsymbol{\mu}}_t = \frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_t \Big)\)。因为训练时 \(x_t\) 其实是已知的(通过 Forward Process 的公式直接得到),因此预测 \(\tilde{\boldsymbol{\mu}}_t\) 其实就相当于是预测 \(\boldsymbol{\epsilon}_t\),记 \(\boldsymbol{\epsilon}_t\) 的预测值是 \(\boldsymbol{\epsilon}_\theta\),那么:
\[\begin{aligned}\boldsymbol{\mu}_\theta(\mathbf{x}_t, t) &= \color{blue}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) \Big)} \\\text{Thus }\mathbf{x}_{t-1} &= \mathcal{N}(\mathbf{x}_{t-1}; \frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) \Big), \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t))\end{aligned}\]于是,我们的目标就是最小化预测的均值和理论的均值之差:
\[\begin{aligned}L_t &= \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}} \Big[\frac{1}{2 \| \boldsymbol{\Sigma}_\theta(\mathbf{x}_t, t) \|^2_2} \| \color{blue}{\tilde{\boldsymbol{\mu}}_t(\mathbf{x}_t, \mathbf{x}_0)} - \color{green}{\boldsymbol{\mu}_\theta(\mathbf{x}_t, t)} \|^2 \Big] \\&= \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}} \Big[\frac{1}{2 \|\boldsymbol{\Sigma}_\theta \|^2_2} \| \color{blue}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_t \Big)} - \color{green}{\frac{1}{\sqrt{\alpha_t}} \Big( \mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\boldsymbol{\epsilon}}_\theta(\mathbf{x}_t, t) \Big)} \|^2 \Big] \\&= \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}} \Big[\frac{ (1 - \alpha_t)^2 }{2 \alpha_t (1 - \bar{\alpha}_t) \| \boldsymbol{\Sigma}_\theta \|^2_2} \|\boldsymbol{\epsilon}_t - \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)\|^2 \Big] \\&= \mathbb{E}_{\mathbf{x}_0, \boldsymbol{\epsilon}} \Big[\frac{ (1 - \alpha_t)^2 }{2 \alpha_t (1 - \bar{\alpha}_t) \| \boldsymbol{\Sigma}_\theta \|^2_2} \|\boldsymbol{\epsilon}_t - \boldsymbol{\epsilon}_\theta(\sqrt{\bar{\alpha}_t}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\boldsymbol{\epsilon}_t, t)\|^2 \Big] \end{aligned}\]上式的期望括号内就是我们的 Training Loss 了。于是,我们的神经网络就变成了训练 \(\boldsymbol{\epsilon}_\theta\) 来预估 \(\boldsymbol{\epsilon}_t\),而在 Forward Process 中可以看出,\(\boldsymbol{\epsilon}_t\) 正是纯 \(N(0,1)\) 的高斯噪声,它其实和 \(t\) 没关系,一直都是高斯噪声,所以可以写成 \(\epsilon\)。
而 DDPM 论文又进一步指出,在实际 Diffusion Training 中忽略前面的 weight 系数更好,因此最终 Loss 就非常简单了,它就是一个标准纯噪声 \(\epsilon\) 减去模型推理的结果 \(\epsilon_{\theta}(x_t,t)\) (有时候后面也会加上一个常数 C):
\[\large loss = \epsilon - \epsilon_{\theta}(x_t,t)\]补充说明:
- 反向过程中,最初始的 \(x_T\) 就是纯 \(\mathcal{N}(\mathbf{0}, 1)\) 的高斯噪声,按照上面递推公式每次从 \(x_t\) 计算 \(x_{t-1}\) 直到最终还原出 \(x_0\)
- \(\epsilon_t = \epsilon_{\theta}(x_t,t)\) 其实就是 Predicted Noise,即通过我们的神经网络 Diffusion UNet 模型的输出(它的输入就是 \(x_t\) 和 \(t\),而 \(x_t\)来自 Forward Process 的结果)。注意它指代的其实是这一步需要 remove 的全部噪声。即:我们期待用 \(x_t\) 减去 \(\epsilon_{\theta}(x_t,t)\) 直接就能得到原始图像 \(x_0\)。当然实际上,根据上述公式,Reverse Process 流程是每次用 \(x_t\) 减去 \(\epsilon_{\theta}(x_t,t)\) 的一部分(即前面的ratio比值 \(\frac{\beta_t}{\sqrt{1-\bar\alpha_1}}\))。容易看出当 t 较大时,这个比值很小(因为分子 \(\beta_t\) 初始最小,之后逐渐增大,而分母 \(\alpha_t\)是累计积,t 越大它越小,故ratio开始最小,之后逐渐增大),因此刚开始时候减去的噪声很少;后续随着t减小,这个ratio会逐渐增大,减去的噪声也会越来越多。
- 注意上式是 \(t>1\) 时的情况。当 \(t=1\) 即最后一步计算 \(x_0\) 时,需要去掉最后面的 \(\sqrt{\tilde{\beta}_t}\epsilon\) 项,即
- DDPM 论文还指出, \(\tilde{\beta}_t\) 也可以直接取值为 \(\tilde{\beta}_t=\beta_t\),实验中两者结果很类似。有些教程直接就用了这种更简单的形式。原文(来自Section 3.2):The first choice is optimal for \(x_0∼ N(0, I)\), and the second is optimal for \(x_0\) deterministically set to one point.
2.3 Training and Sampling 流程
基本就是前面的 Forward Process 和 Reverse Process (Sampling) 的流程总结:
