Transformer 学习
0. 参考材料 References
- Attention is All you need 原始论文:https://arxiv.org/pdf/1706.03762.pdf
- 视频讲解 attention 机制的基础原理,只针对 Attention,讲的非常细:Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
- 从RNN开始讲起到Transformer的概述,也引用了上面 [1] 中的视频做成了动图,不过对 Transformer 整体流程 的回顾太简单了:https://builtin.com/artificial-intelligence/transformer-neural-network
- [推荐] 这个是很有名的一个给出了从头到尾的全程 coding 来讲解 Attention 机制,值得认真学习,适合最先看。只是它只讲述了 attention 并没有整个 Transformer 流程:Understanding and Coding the Self-Attention Mechanism of Large Language Models From Scratch
- [推荐] 这个教程非常详细给出了整个 Transformer 网络全程的全部细节,每个步骤都有动画,并给出了全程视频,非常指的看,唯一缺点可能是没有代码。适合最先看:*Illustrated Guide to Transformers- Step by Step Explanation。视频:https://youtu.be/4Bdc55j80l8
- 大牛 Andrej 对 Transformer 的全程讲解,Stanford 课程,也结合了代码,这个算是终极材料了,将的更深,可以最后看:CS25 I Stanford Seminar - Transformers United 2023: Introduction to Transformers w/ Andrej Karpathy
- [强烈推荐] 这个是 Transformer 原作者给出的官方代码,超级推荐,代码可用并且 step by step 非常细。只是没有讲解过程,因此适合最后代码实战时候看: The Annotated Transformer
- 非常好的有全程图例的 Transformer 回顾,全程没有公式,而是用各种图例展示流程。不过因为流程介绍不够详细,因此适合同其他材料一起看,而不是单独看: The Illustrated Transformer
1. 以 RNN 为代表的 Seq2Seq 模型回顾
本章结合了Ref [1,2,3]。
从前面的 RNN 和 LSTM 的结构可以看出,两者的共同点是每一个单元 $h_i$ 的获取都依赖于上一个单元 $h_{i-1}$ 的结果,因此这显然是没办法并行的。也因此,两者的训练都很慢。尽管 LSTM 通过 gates 的设计可以支持更长的记忆,但是它其实还是有一定的 vanishing gradients 问题(即,它也没办法记忆非常长的距离。举例对比的话,RNN可以支持个位数到十位数的单词长度,LSTM可以支持上百个,但是也就这样了)。并且 LSTM 的训练有时候甚至比 RNN 还要慢。
Ref [1] 即 Transformer 原始论文中的一段评价:
Recurrent models typically factor computation along the symbol positions of the input and output sequences. Aligning the positions to steps in computation time, they generate a sequence of hidden states ht, as a function of the previous hidden state $h_t−1$ and the input for position $t$.
接下来我们再一次先回顾 RNN 以及 LSTM 这种 recurrent network 框架的基本架构,然后引出 Attention 机制。
1.1 序列到序列的映射模型 Sequential to Sequential (seq2seq) Model
参考:基本就是翻译 Ref [2]
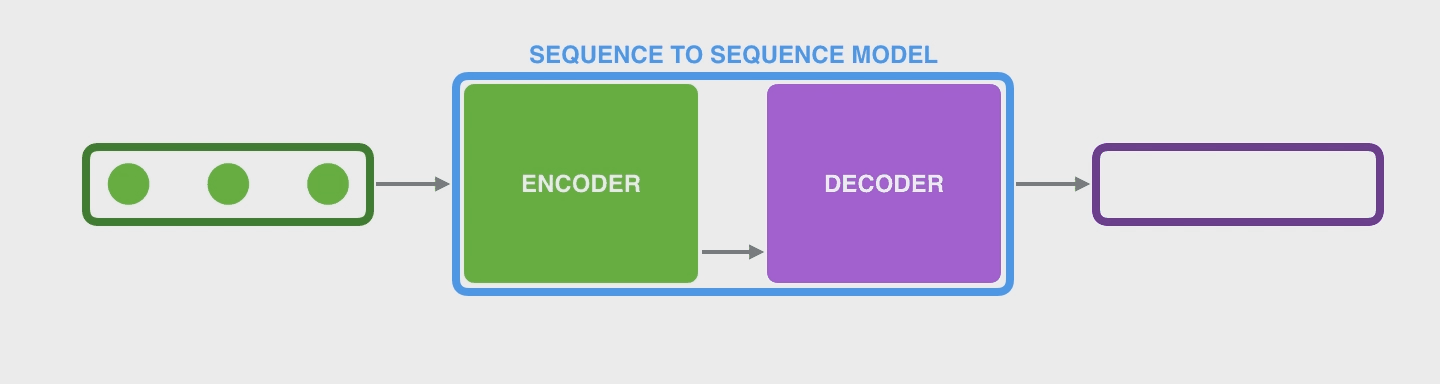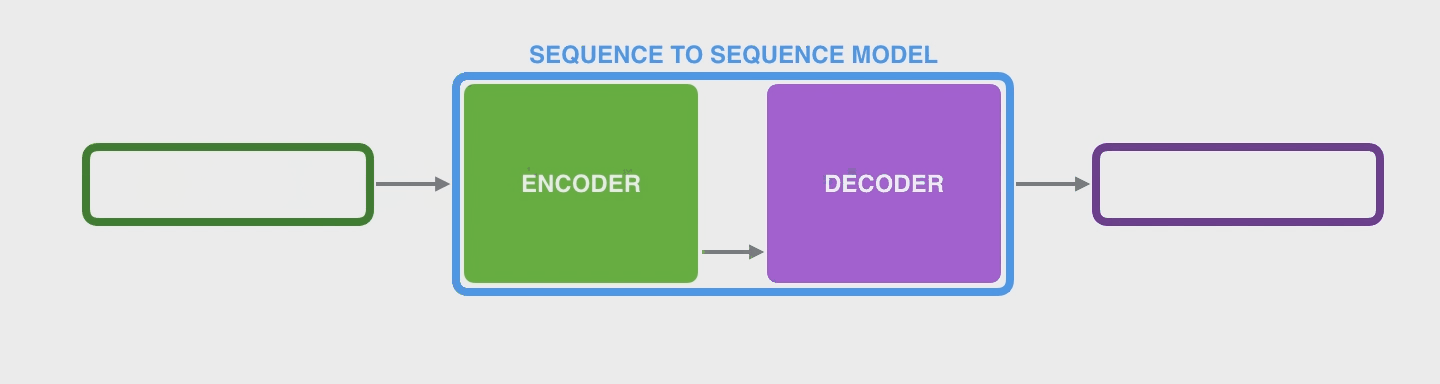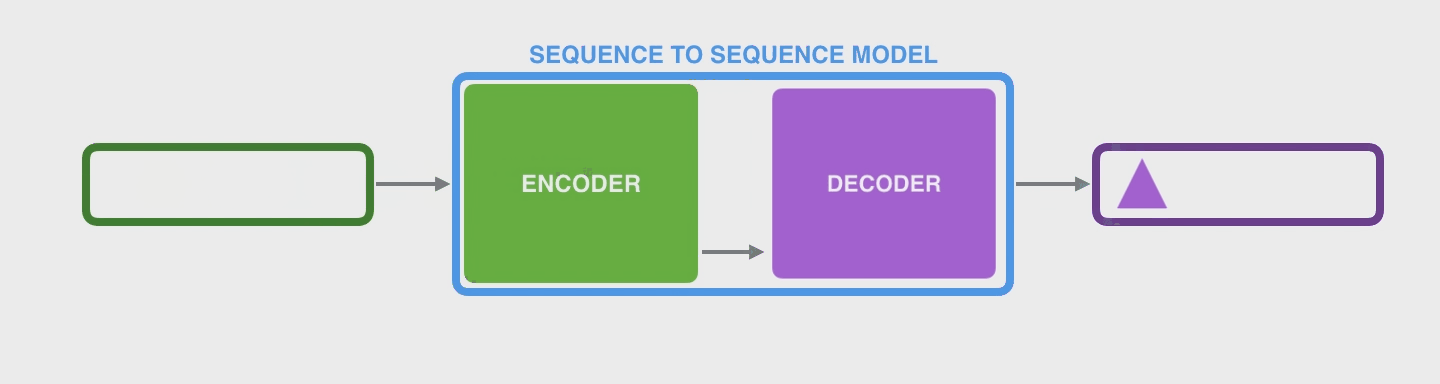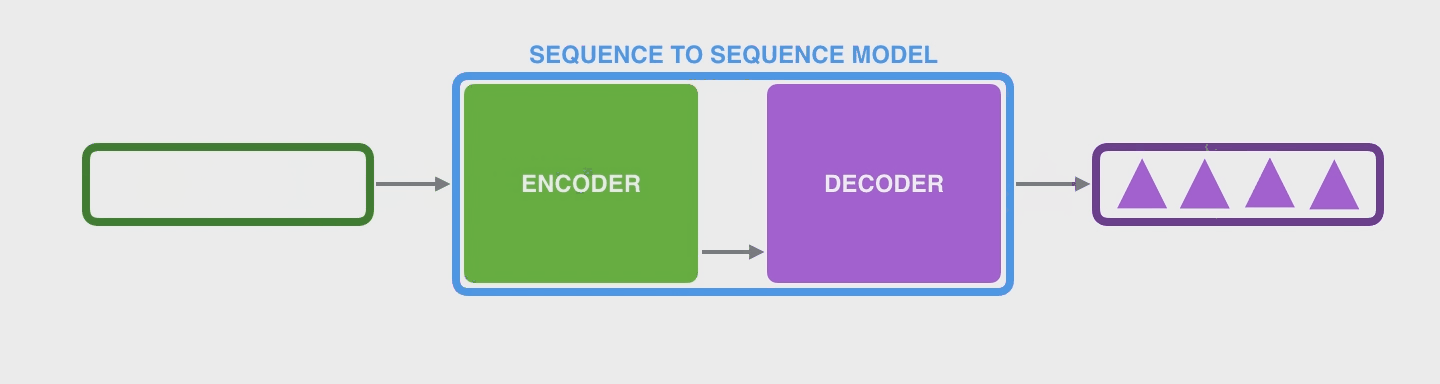
首先,一个 sequence-to-sequence model “序列到序列”映射的模型顾名思义就是将一个序列映射到另一个序列

以机器翻译的模型为例,这个序列可以是一个句子(单词序列),模型就会按照单词传入顺序一个一个处理:

1.2 RNN为代表的 seq2seq model 原理
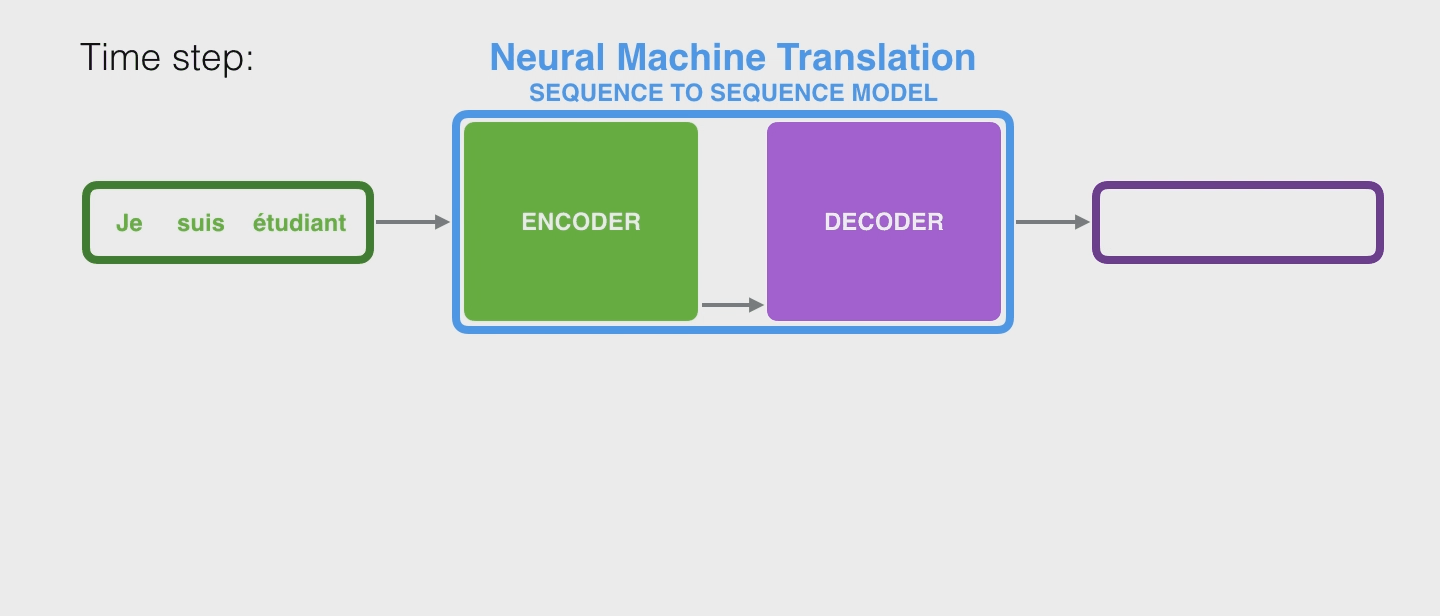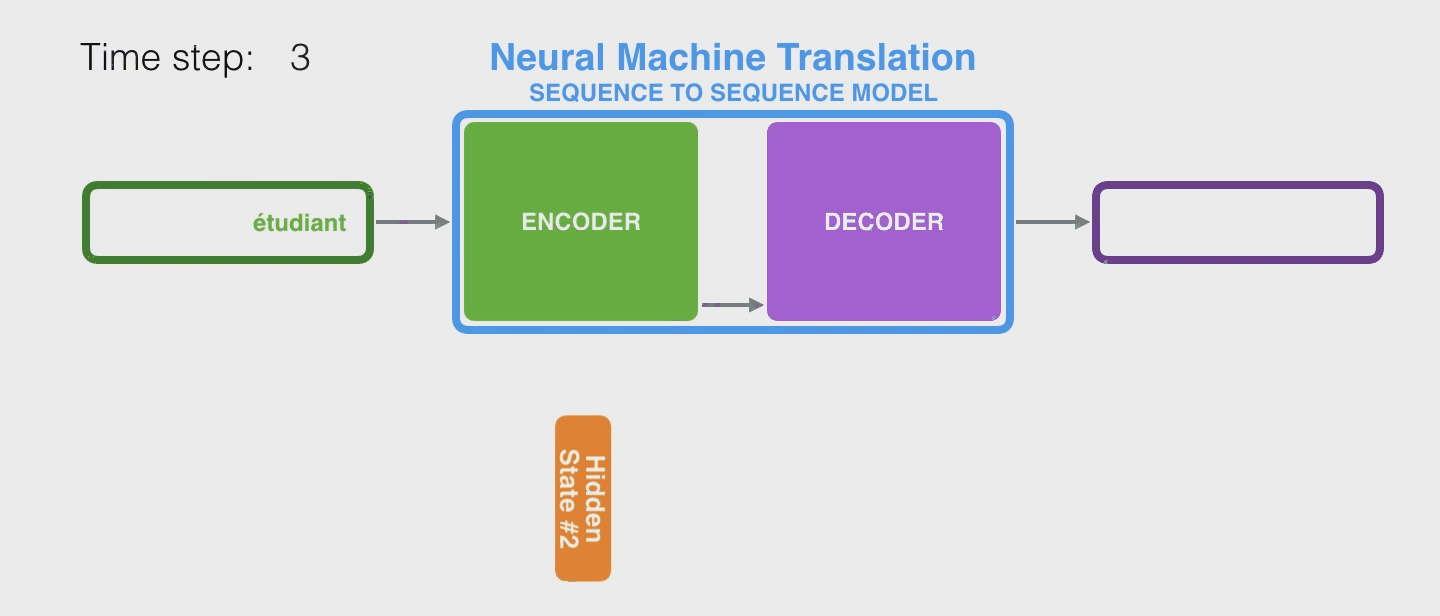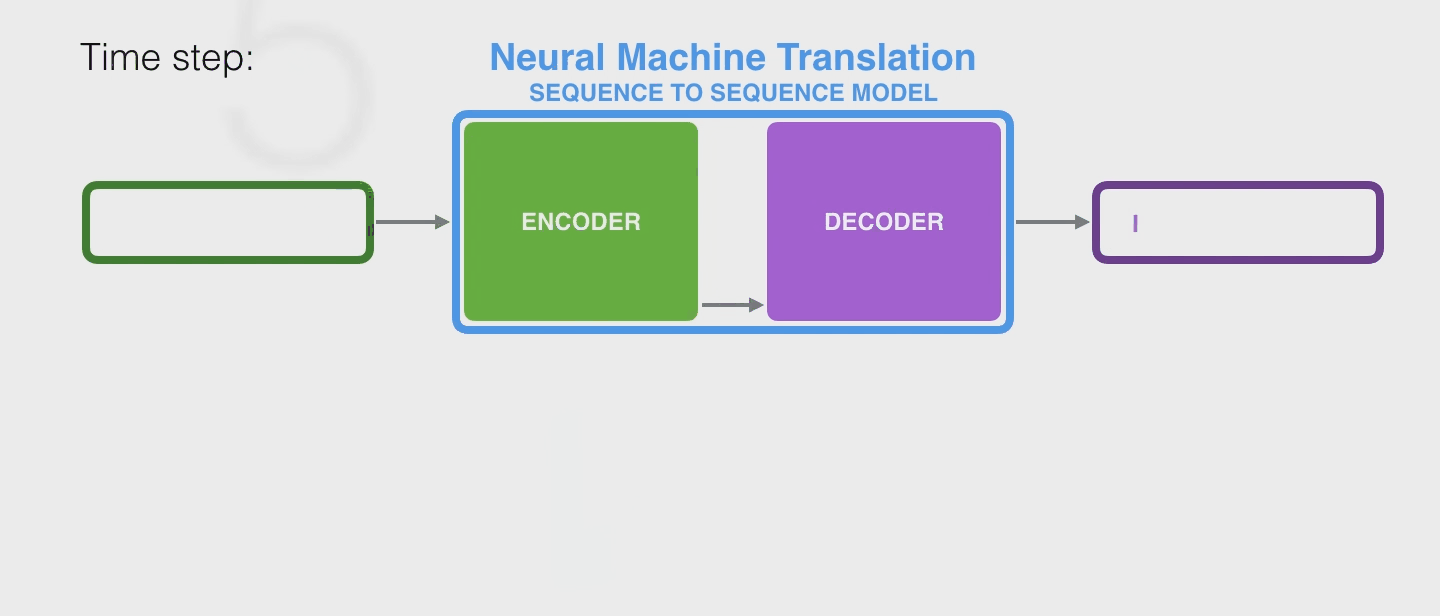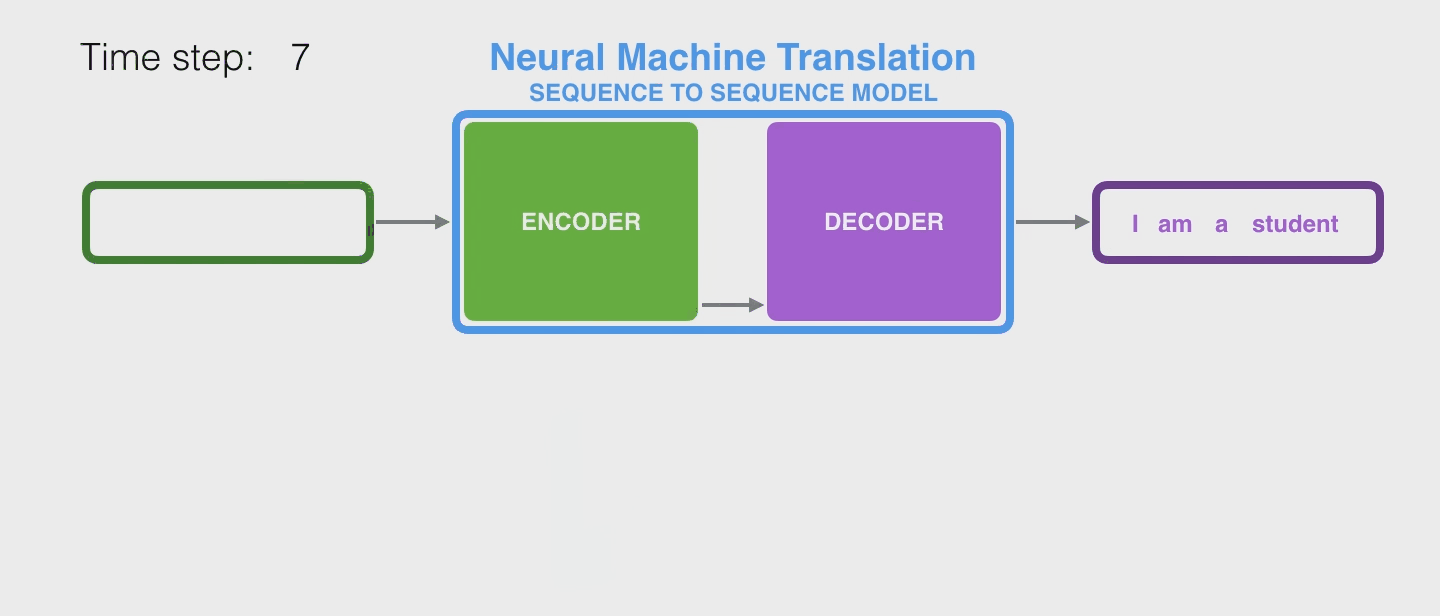
通常这种 seq2seq model 都会给出一个 Encoder 和一个 Decoder,其中 Encoder 传入输入序列,将其编码为称作 context vectors (或者直接称为 context)的结果,然后传入 Decoder 解码出最终的输出。
机器翻译中也是如此
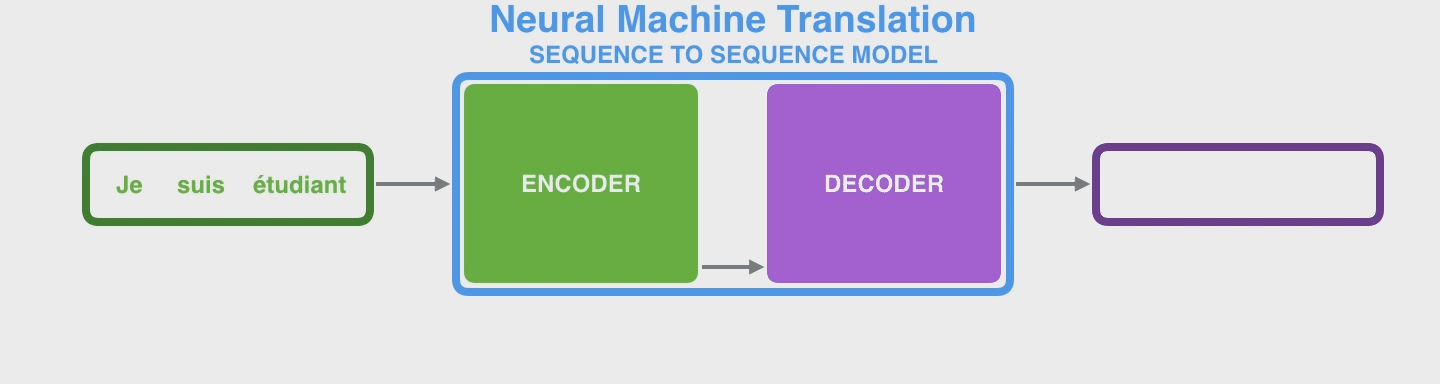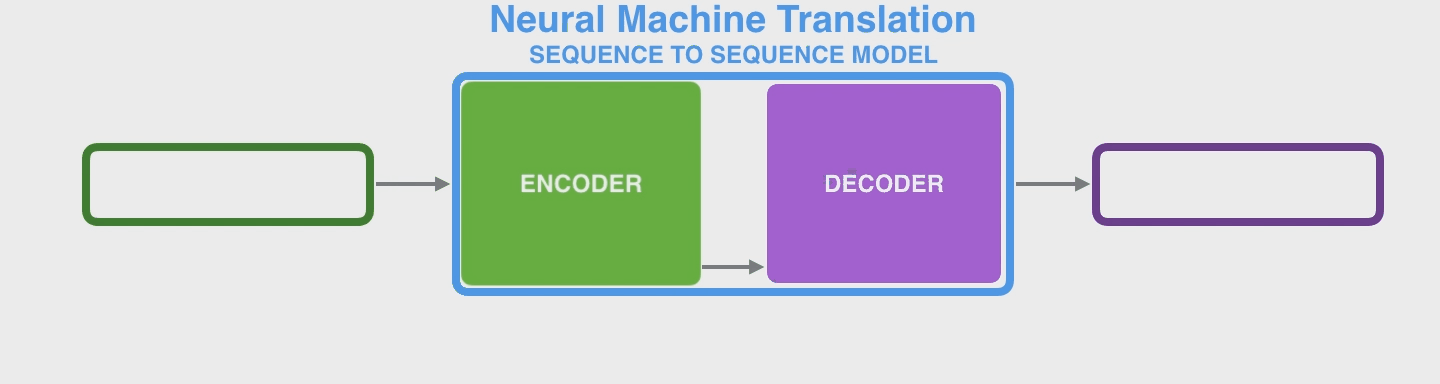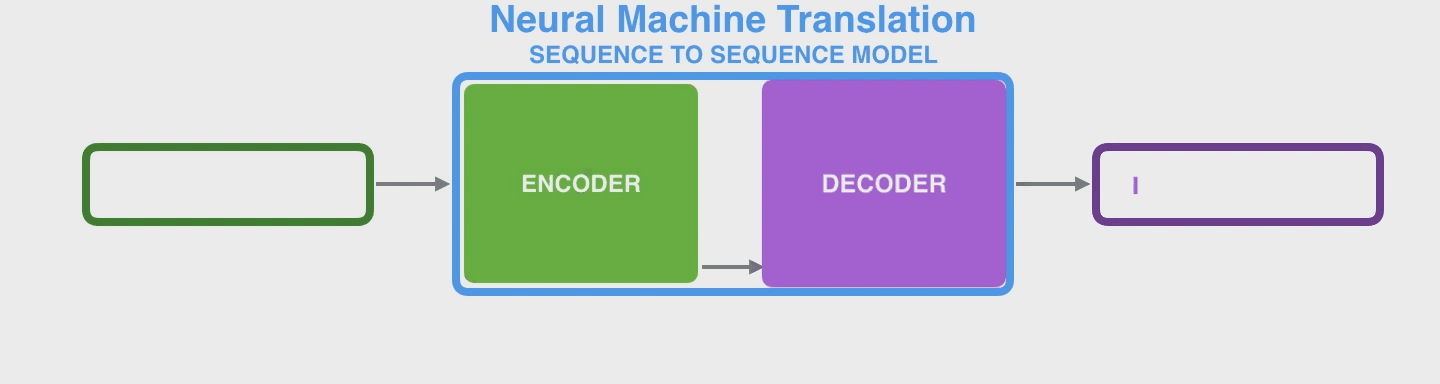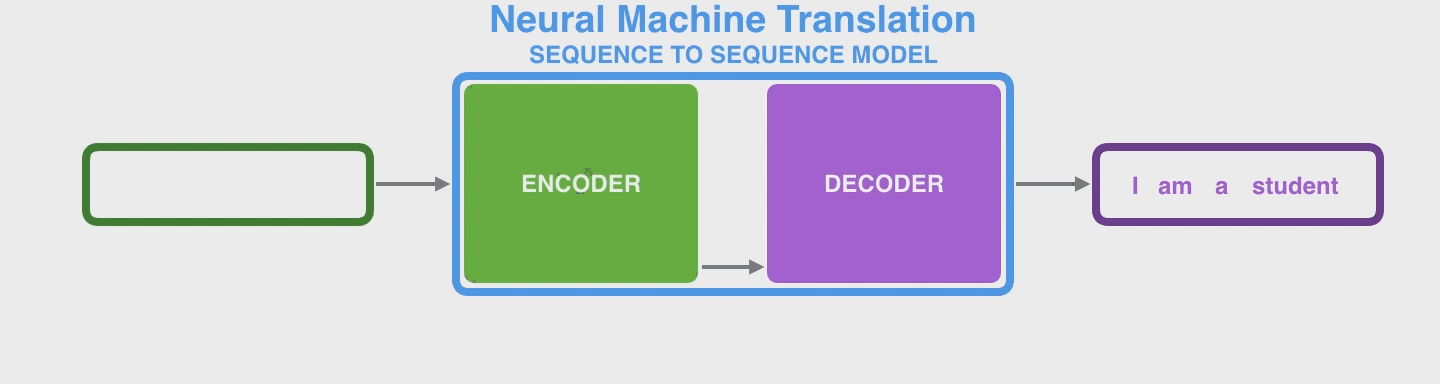
那么 context 是什么呢?对于每个全部的输入 items,例如单词words,它会被 Encoder 编码成为一个 context vector, 可以认为就是一个1D vector 向量(如果是高维那么flatten开后还是一维)。例如下图中设定了一个 size 4 的 contex vector(而实际引用中通常更长一些,例如256, 512 or 1024等)。这个维度值通常就是 hidden units or hidden size。

在机器学习中,Encoder和Decoder通常被设计成 recurrent neural networks (RNN) 模型 (recurrent意思类似是它 只有一批权重需要更新,每次传入数据都更新它自己),
而通常 context vector 的⻓度就是 RNN 模型的 hidden units 的个数。例如如果设计一个 hidden units = 512 的 RNN/LSTM 网络,那么每个 context vector ⻓度 就是 512, 因此所有输入 items 的 context vectors 就是 Nx512 数组。
1.3 对原始输入单词做 Vector Embedding
在机器翻译任务中,我们通常首先要把原始的 word 单词先做一个 embedding 得到 embedding vector,然后再传入 RNN Encoder 中。这个 word embedding 有专门的算法来做,就类似一个 word to vector 的 one-on-one mapping,并且 vector 的结果考虑到了单词之间的语义信息(例如两个相近的单词的vectors也相近,之类的)。coding 时通常使用 pytorch 提供的 embedding 即可。通常 vector size 有200或者300之类的,数值上通常都是-1到1之间的。下图是以长度为 4 的 vector embedding 为例简化一下。
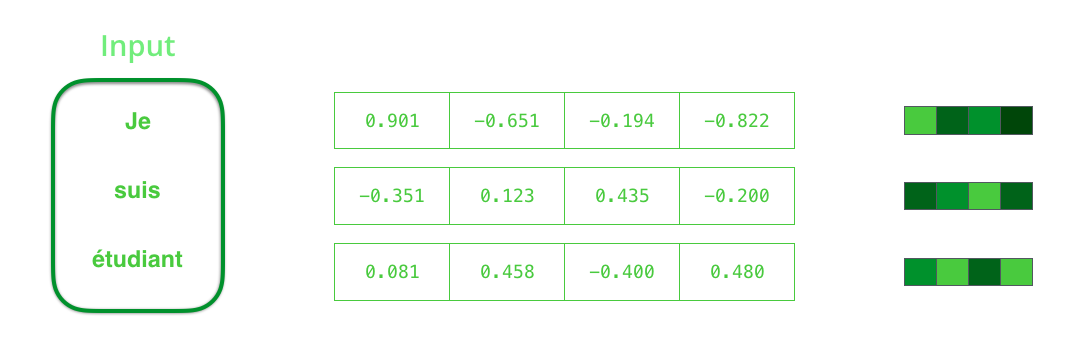
这里参考 Ref. [5]给出的一个简单的代码,将一个6个单词输入的句子中的每个 word index 映射到 embedding vector 上。
import torch
sentence = 'Life is short, eat dessert first'
sentence_split = sentence.replace(',', '').split()
dc = {s:i for i,s in enumerate(sorted(sentence_split))}
sentence_int = torch.tensor([dc[s] for s in sentence_split])
print(sentence_int)
torch.manual_seed(123)
embed = torch.nn.Embedding(6, 16)
embedded_sentence = embed(sentence_int).detach()
注意,在代码实现中,我们通常是将每个word先转换成它对应的 word index integer,例如可以使用一个包含了全部 words 的 word-to-index dictionary。然后再将word index做 embedding得到 vector。
1.4 RNN流程和细节
Okay 现在就可以总结回顾一下 RNN 模型的流程了(LSTM本质上和RNN是类似的,只是增加了多个gates操作使得对历史记忆能力提升了,框架不变)。首先直接上动图。
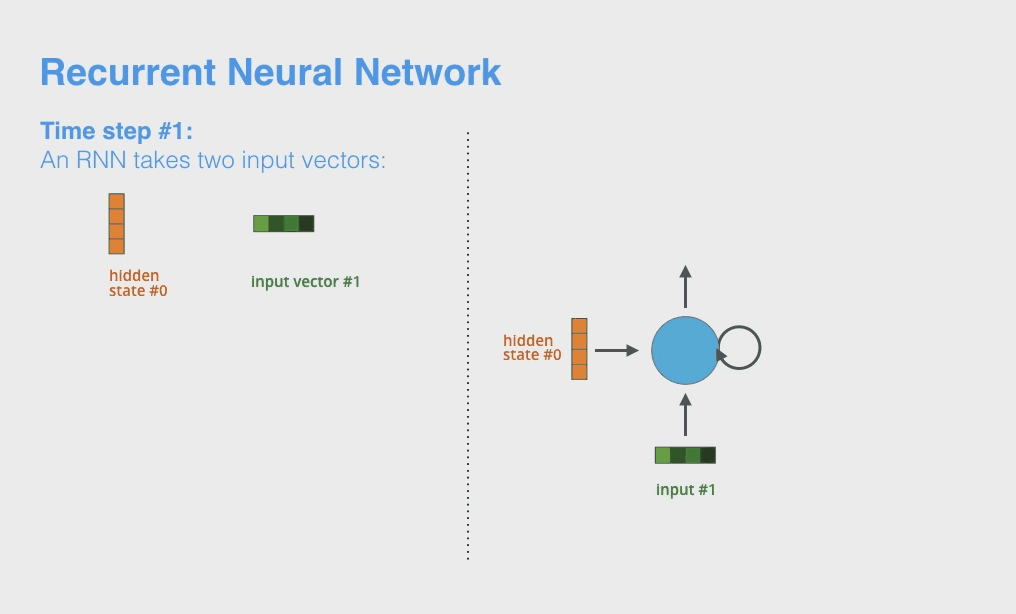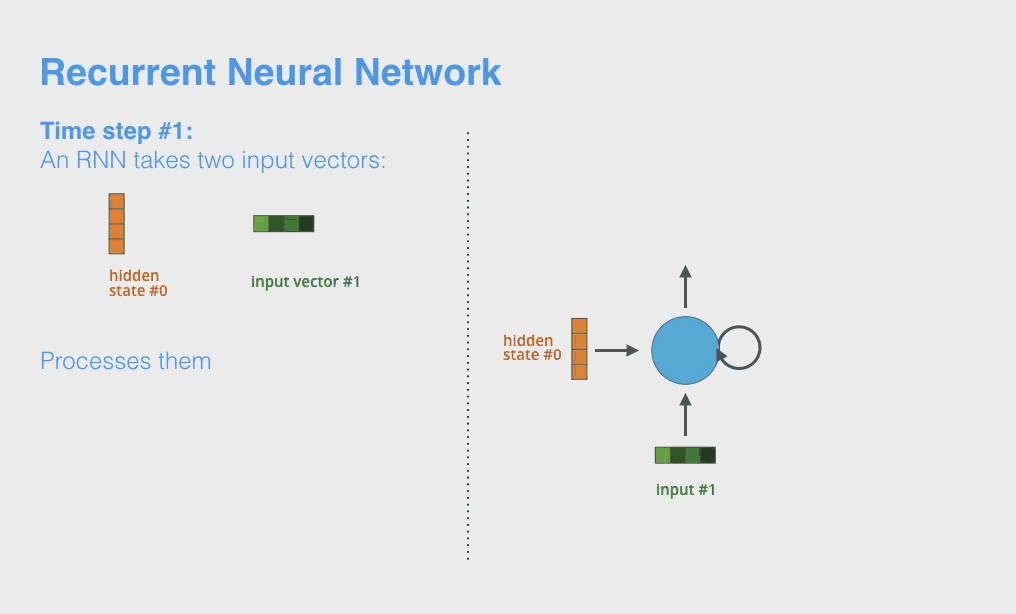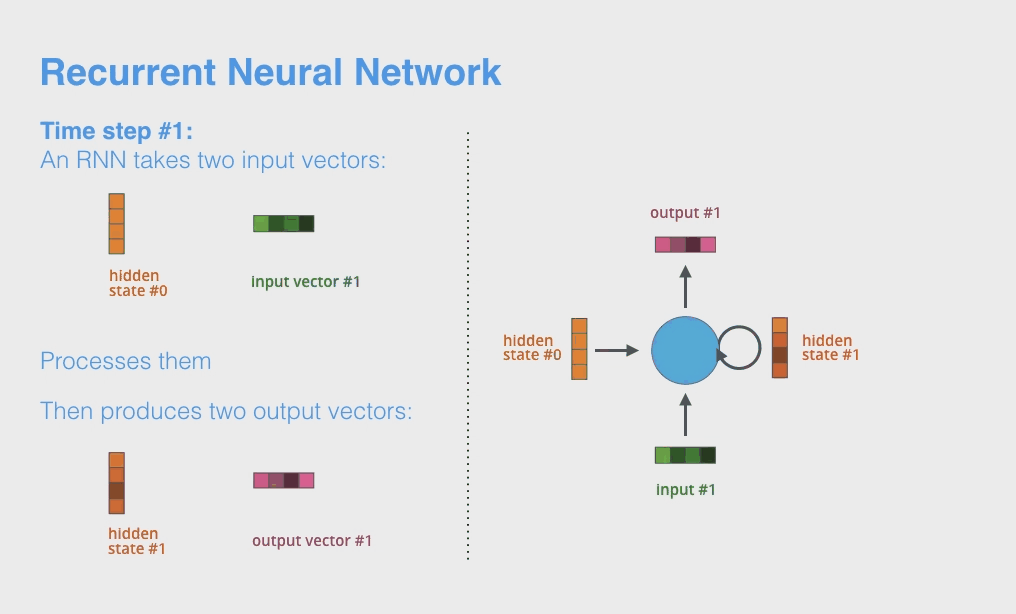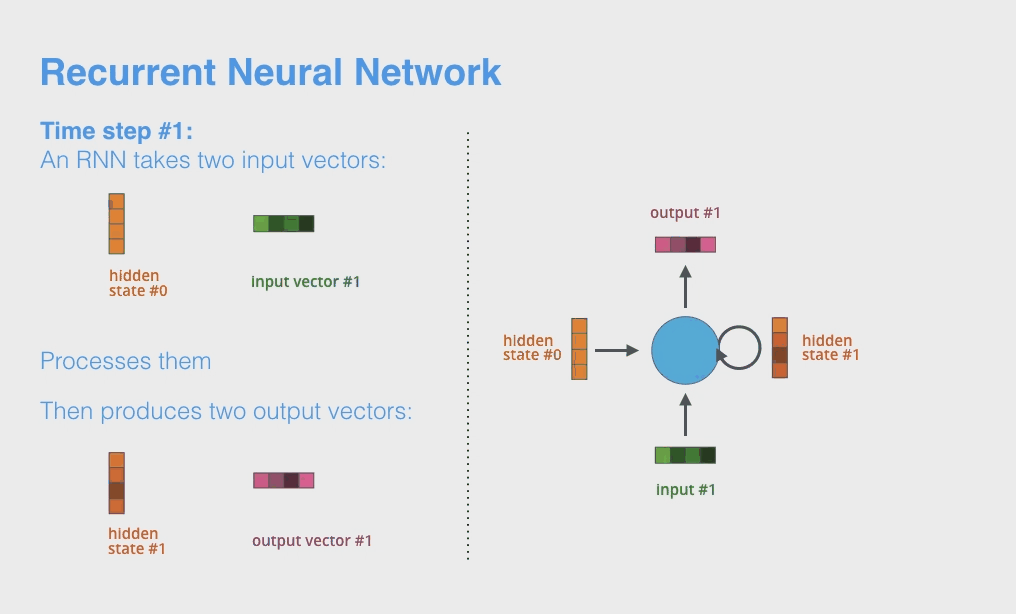
1.4.1 单层RNN的计算步骤
RNN也分为单层和多层,这里首先以单层 single layer 为例。
RNN 中定义了 hidden state,长度就是 Hidden units 的长度。在RNN网络结构中,每个 hidden unit 就只有一个一维的 weight vector 和另一个平移向量即 $\mathbf{w}_i$ 组成,它们的长度就和输入的每一个 word embedding vector $\mathbf{v}_t$ 长度相等,而做的事情就类似这样的点乘再求和:
\[h_{it} = \mathbf{w}_i\mathbf{v}_t +b_i\]这里的 $t$ 就是输入单词的 index,而 $i$ 则是 hidden unit index, $b_i$ 是 i-th hidden unit 对应的 bias,注意它是一个标量。因此最后的 $h_{it}$ 也是一个标量。RNN 每次每次传入一个 $\mathbf{v}_t$ ,我们通常称为一个 time step,如上面的动图。
记 $D$ 是 #hidden units, $T$ 是输入的句子的单词总个数。
不妨以 $D=256$ 为例。那么,对于每一步 $t$ 像刚刚这样的 $h_{it}$ 的计算就会有 256 次,因此得到的全部的 256 个 $h_{it}$ 就组成了这一个 time step $t$ 的 hidden state 的结果,显然它是长度为 256 的一维向量,记录为:
\[\mathbf{h}_t = (h_{1t}, h_{2t}, \ldots, h_{Dt})\]通常 RNN 还会考虑到上一步的 hidden state,因此刚刚这个计算会纠正为这样:
\[h_{it}=\mathbf{w}_i \mathbf{v}_t + \mathbf{h}_{t-1}\mathbf{b}_i\]$\mathbf{h}_{t-1}$ 就是上一步的 hidden state 结果, $\mathbf{b}_i$ 则是bias,注意此时它们就都是一个向量了,长度就是#hidden units。
可以看出,对于每个 time step的计算中,使用的都是同一批即全部的 hidden unites 中的 $\mathbf{w,b}$ 一起运算,而不是每次的输入都有新的。最终,重复了 $T$ 次(即单词总个数)计算后,得到了最终的 hidden state 结果,而这个最后一个 time step 就是我们上面所称的 context vector 了,可以看出它的长度是和 hidden units 相等的。
下面是我绘制的整个流程的计算示意图(下面图中以 hidden units 改为 8 为例方便绘制)。这里将核心运算画在了不同的框子里是方便理解,其实容易看出每个框中的 $w_i, b_i$ 都是同一批。此时再回到上面看RNN的动图,相信会有更深的理解了。注意图中有些向量没有用粗体。
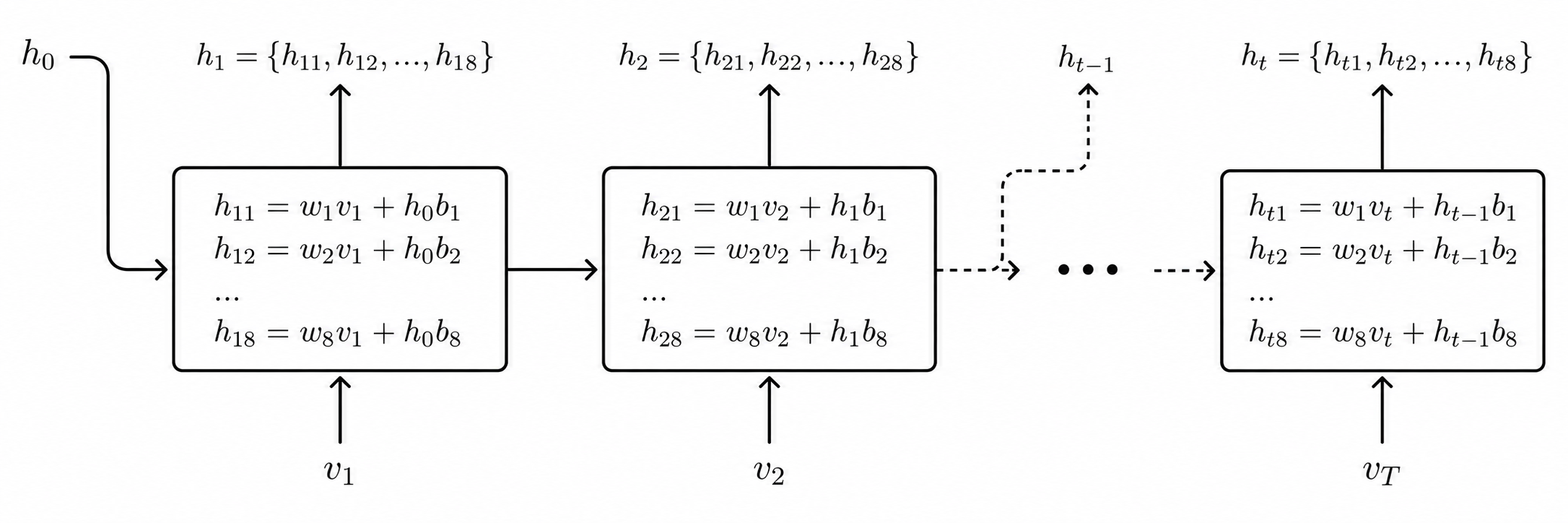
不难看出,这个 RNN 模块中的参数就是 #(hidden units) x $D$ x 2(即全部的 w, b 的参数量),其中 $D$ 是输入的 embedding vector 的长度。
另外,通常在 pytorch 等代码实现中,类似的 RNN 结构通常会同时返回:
- 每一个 time step 得到的全部 hidden states 结果,即全部 $T$ 个单词的 $\mathbf{h}_0, \mathbf{h}_1, \ldots, \mathbf{h}_t$
- 最后一个 time step t 的 hidden state $\mathbf{h}_t$(即 context vector)。
1.4.2 多层RNN结构
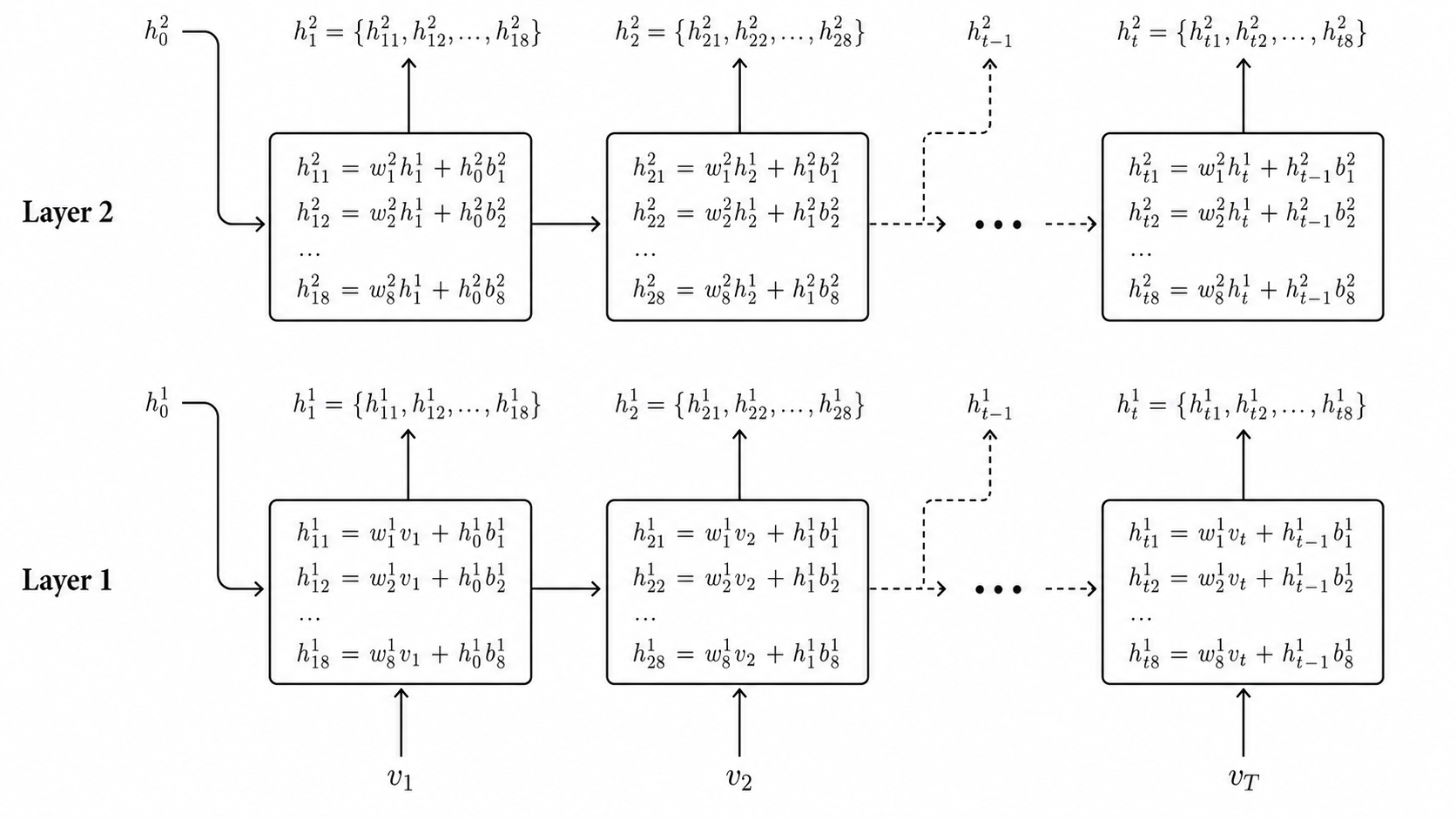
多层的 RNN 结构就相当于上面单层的一个扩展,上面这一排我们就认为是一层,因此多层就是(在图例中所示的上面)多增加几层,然后每一层的节点的输入是下面一层的 hidden state 输出。
下图给出了两层 RNN 的一个例子。这里每个符号增加了一个上标1和2代表了属于第1层和第2层(横向上看)。第2层的(下面方向来的)输入此时不是 $\mathbf{v}_t$,而是对应的第1层输出的 hidden state,其余的流程全都一样。整个网络的输出此时多了一层的结果,例如 pytorch LSTM 会同时返回:
- 每一个time step得到的最后一层(图中就是第2层)的全部 hidden states 结果,即:
- 最后一个时间 t 的所有层的 hidden state(图中就是 $h_t^1, h_t^2$).
前者维度就还是 $T$,后者维度变成了 #Layers x #(hidden units),因为每一层都会输出。例如,pytorch LSTM 的 API 介绍(LSTM ‒ PyTorch 2.0 documentation),它返回的参数中,output 就是1,而 $h_n$ 就是2。
1.4.3 总结 RNN 并引出 Attention 机制
继续以机器翻译为例,RNN是这样工作的
其实传入 decoder 后,它通常也会维持一个 hidden state 不断传入下面,上图中作者也没画出来,因为不是重点。
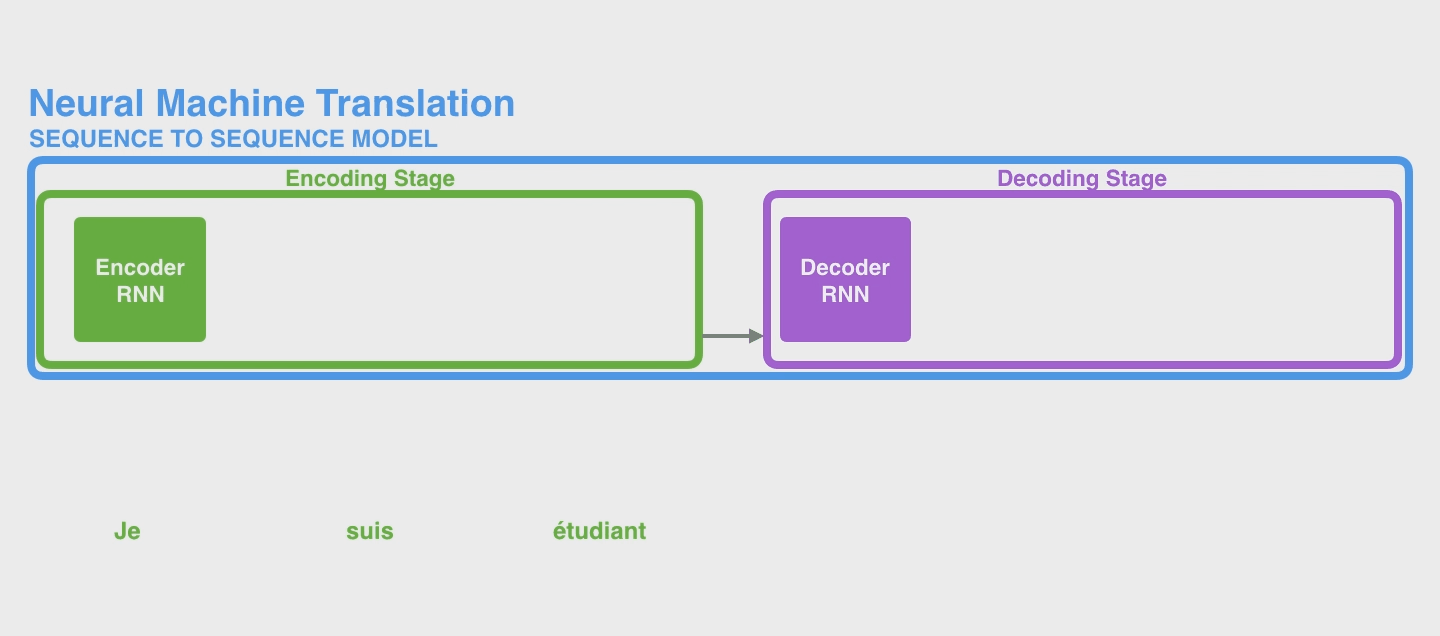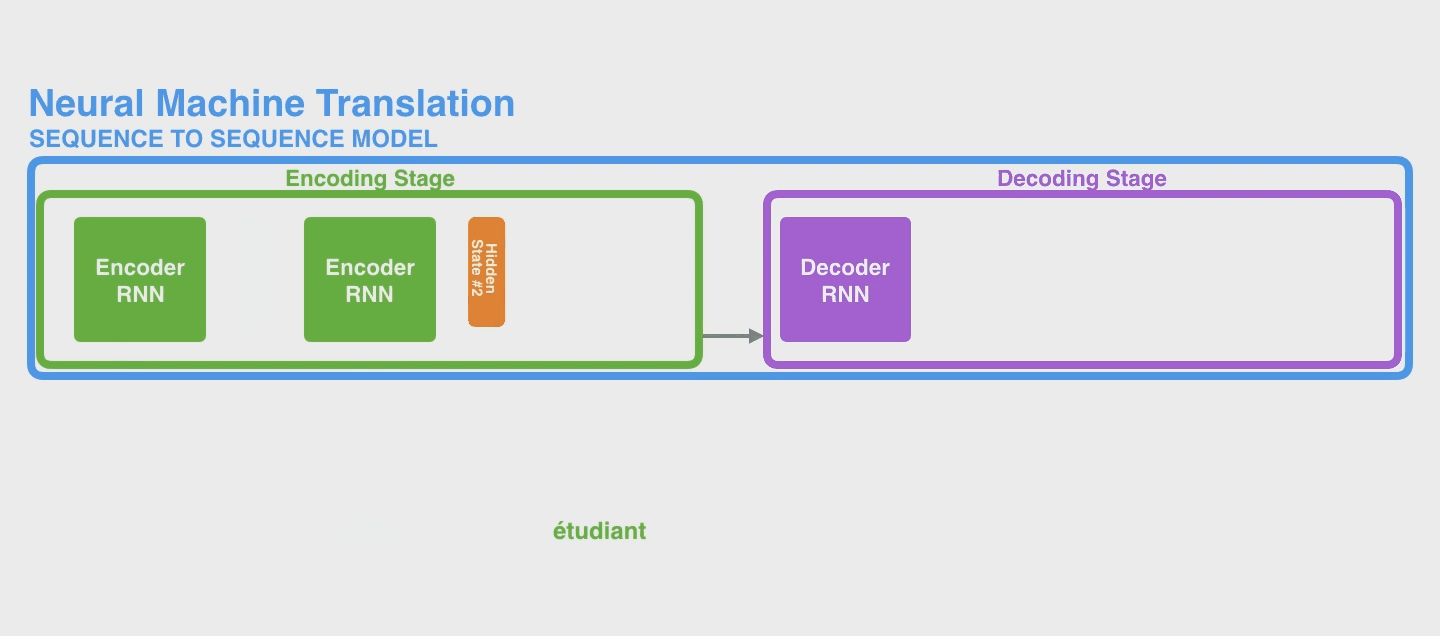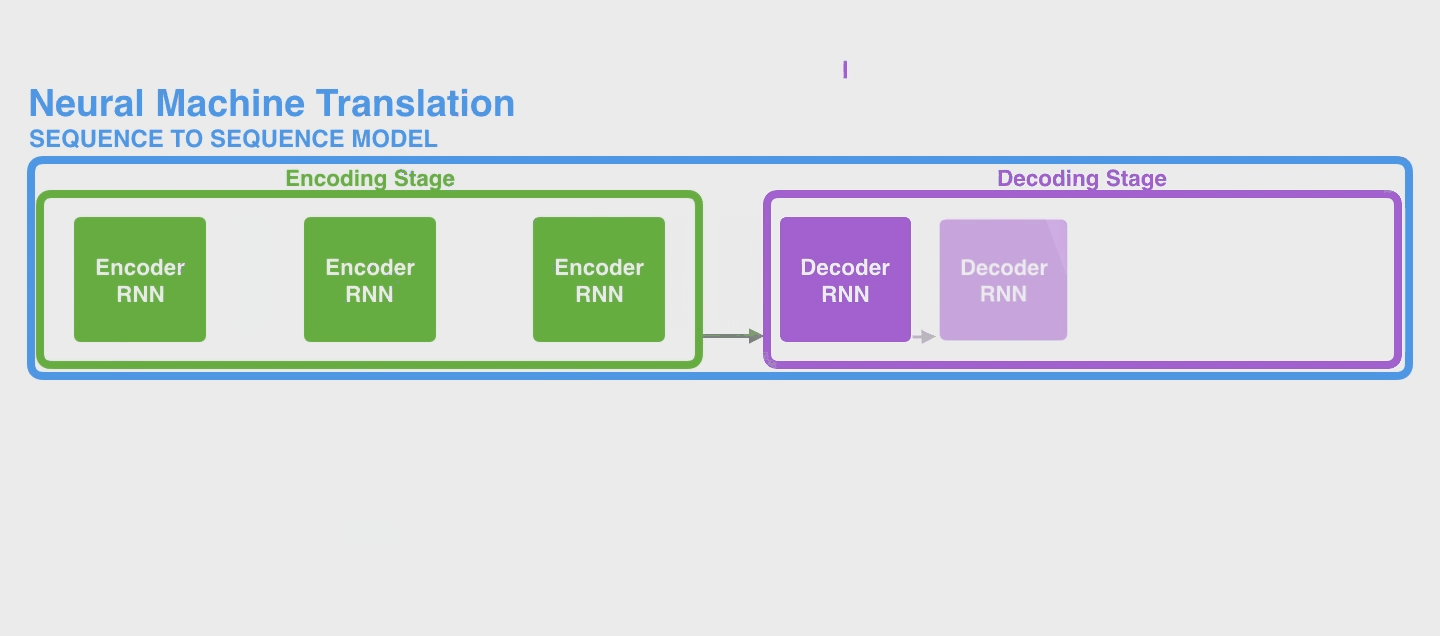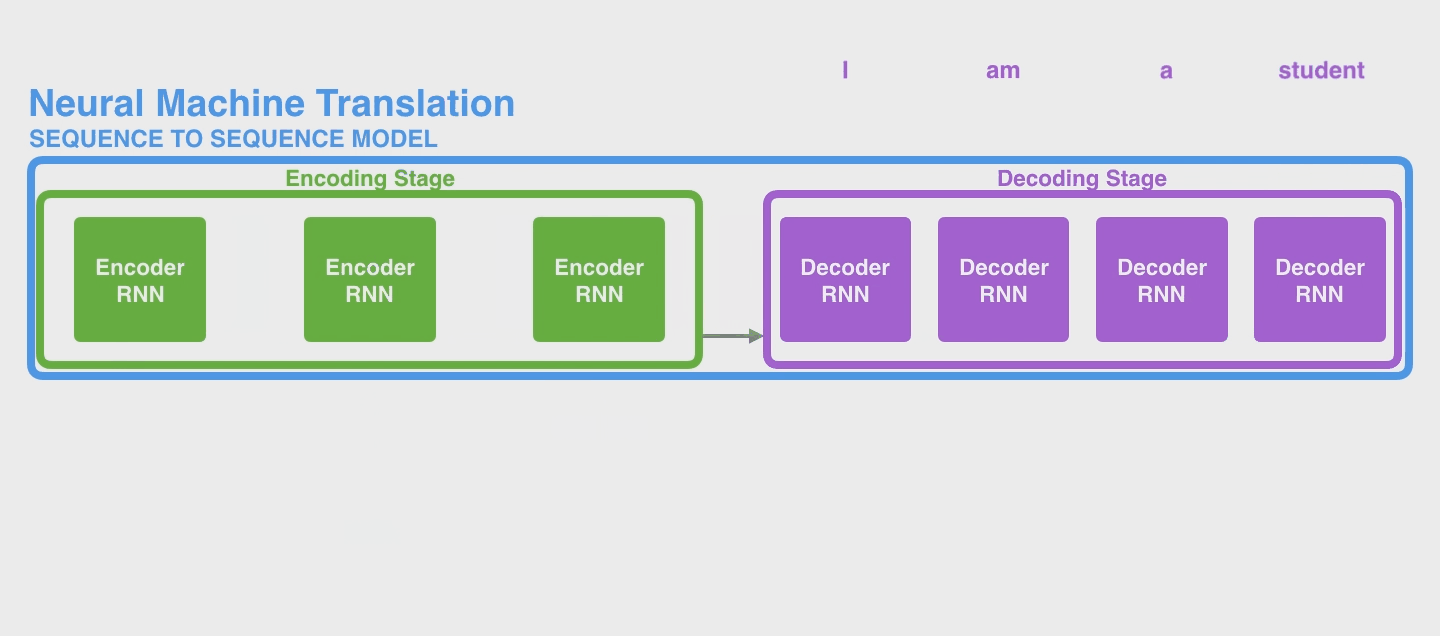
下面是一个 seq2seq model 的完整的例子。下图中是把 Encoder module 和 Decoder Module 分别画了很多个 copy 方便理解,实际上还都是只有一个而已。当然实际上,即便你也可以将 Encoder 的所有 hidden states 的结果传入 Decoder(例如LSTM的output返回的是全部 hidden states),不过这些 hidden states 之间也没有偏向性,即它们起到的作用(权重)是相同的。
2. Attention 流程和机制
参考 Ref. [2,3]
2.1 Attention 机制
接下来终于引出了 Attention 机制了。相比于前面介绍的以 RNN 为代表的 seq2seq 模型传入的 hidden states,以 Attention 机制为基础的 Decoder 的区别是:
- 它传入数据更多。Attention机制会传入 Encoder 的每一个 time step 的全部的 hidden states到 Decoder,而不是像前面一样只传入最后一步的 states;
- 它会提前对 hidden states 做一步额外操作:给每个 hidden state 打一个评分(score),然后得到 scored/weighted hidden states,目的是将打分高的 hidden states 给较高的权重,提升其在 Decoder 中的作用,相反会降低得分低的 states 的重要性。
可以看出,Attention 机制会有选择的对不同的数据给不同的”attention”。这是因为,通常在以机器翻译为例的任务中,翻译结果中某些单词显然会和原始输入之间某一些单词关系更大,而和其他的单词关系小。因此,attention机制就会更好的本来关系紧密的输入和输出更好的绑定/映射到一起。
下图展示了这个机制的一个例子,可以看出它展示了上面的第1点,将全部的hidden states传入 Decoder。
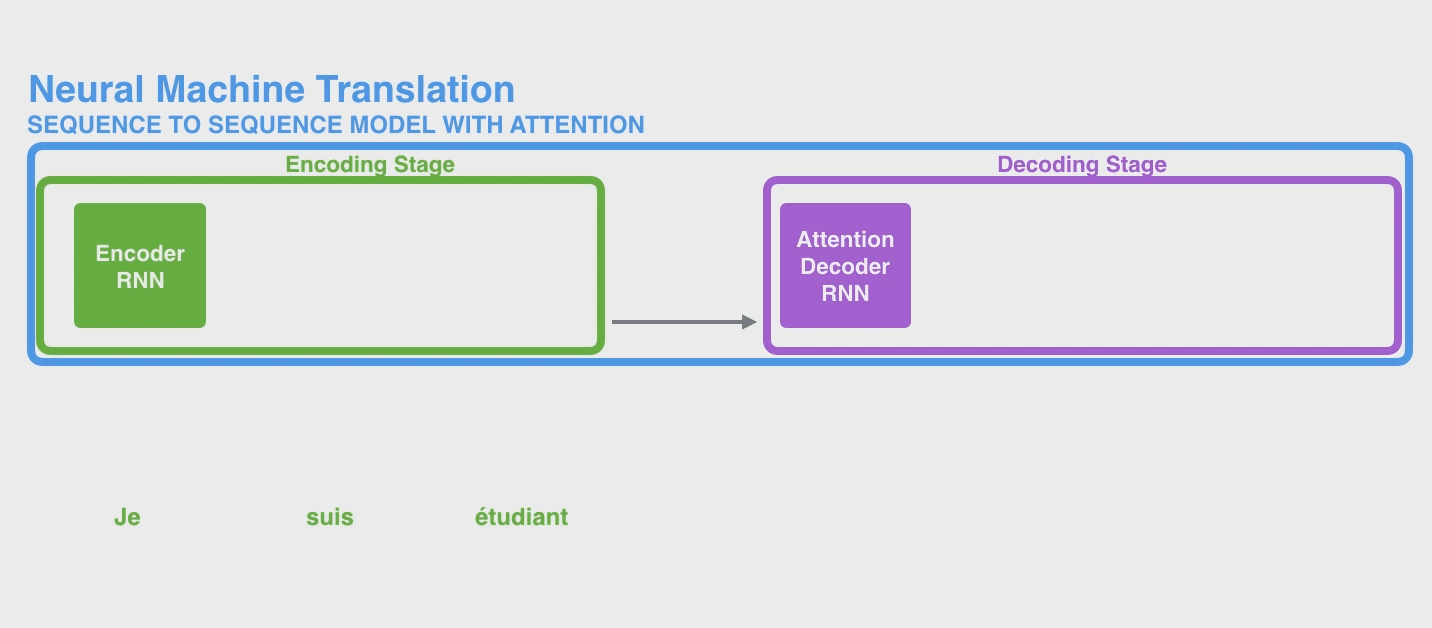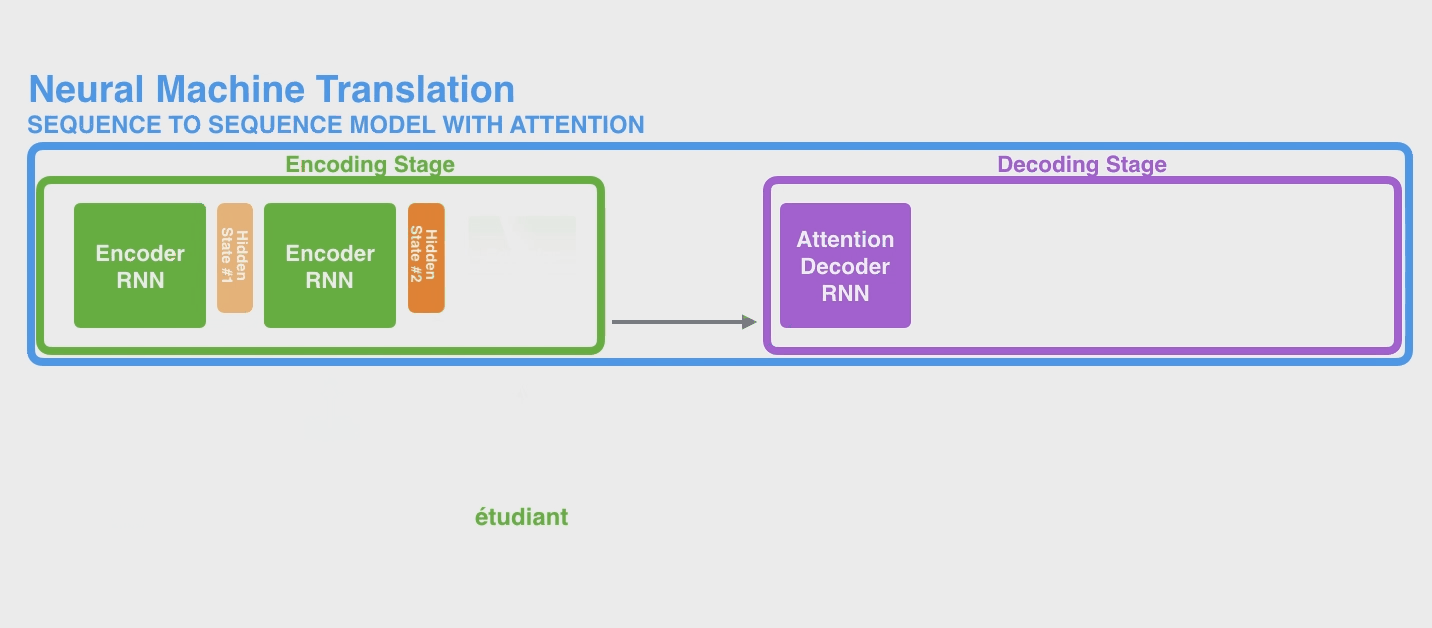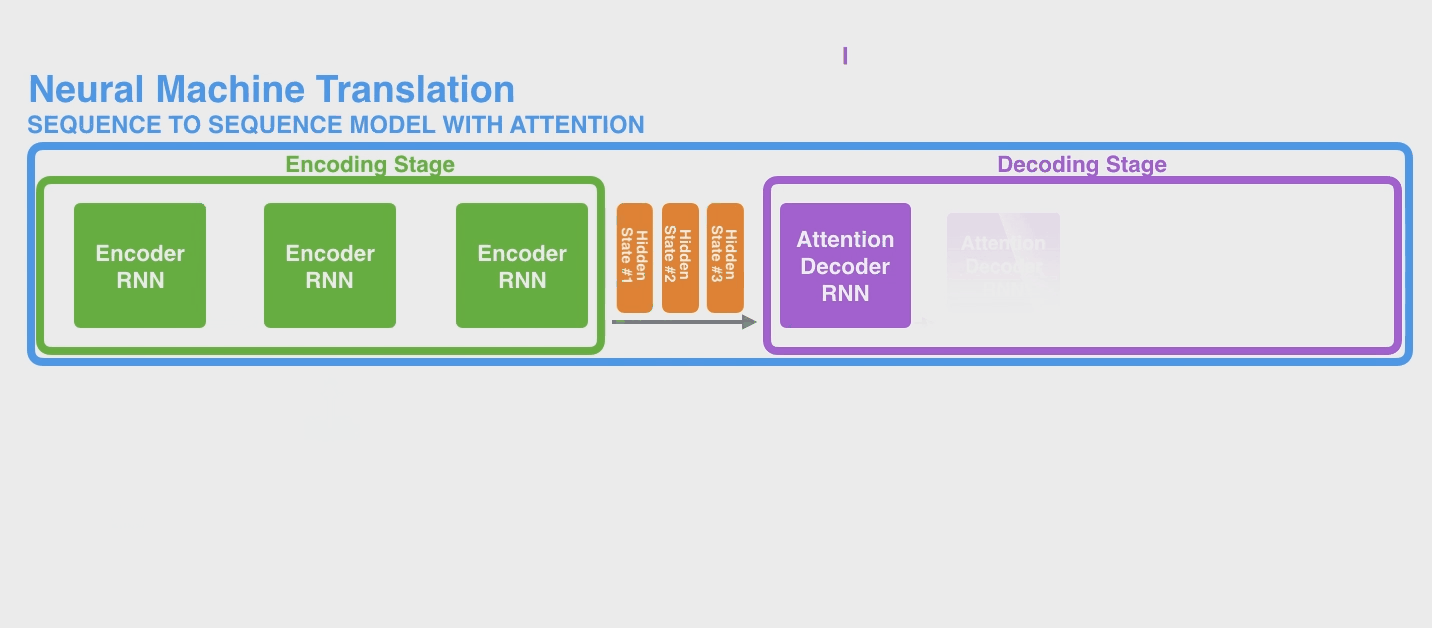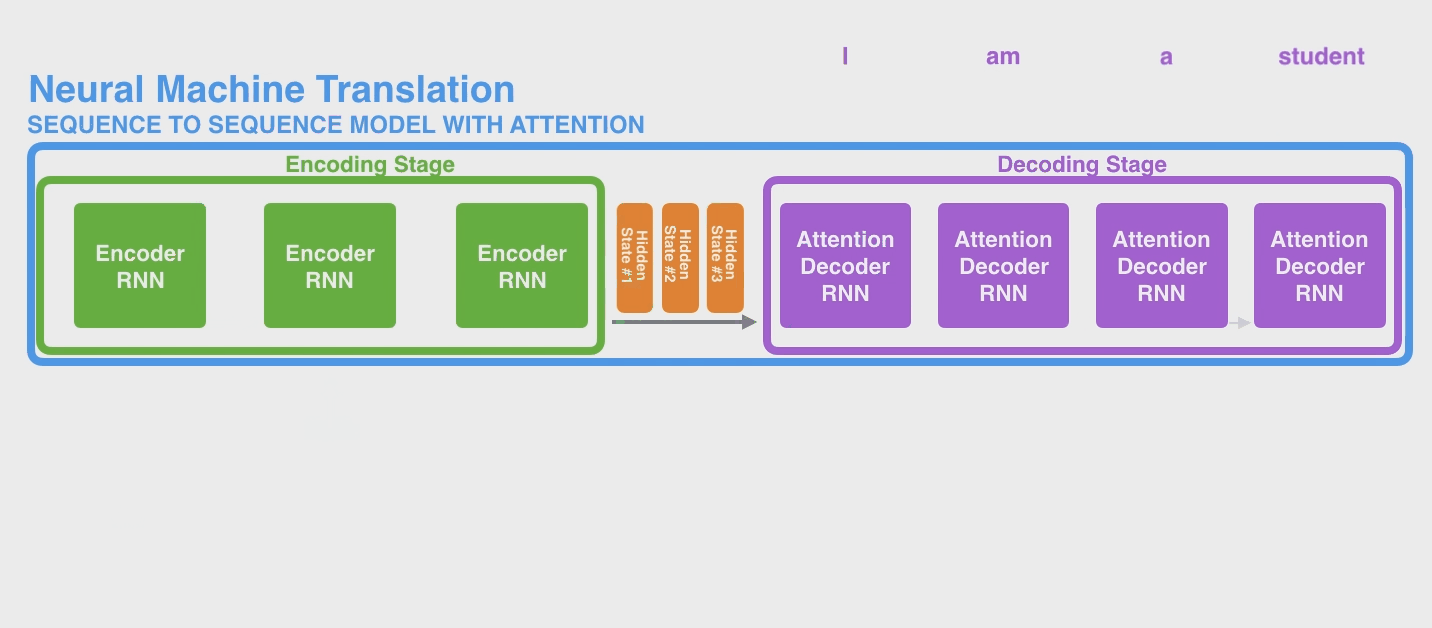
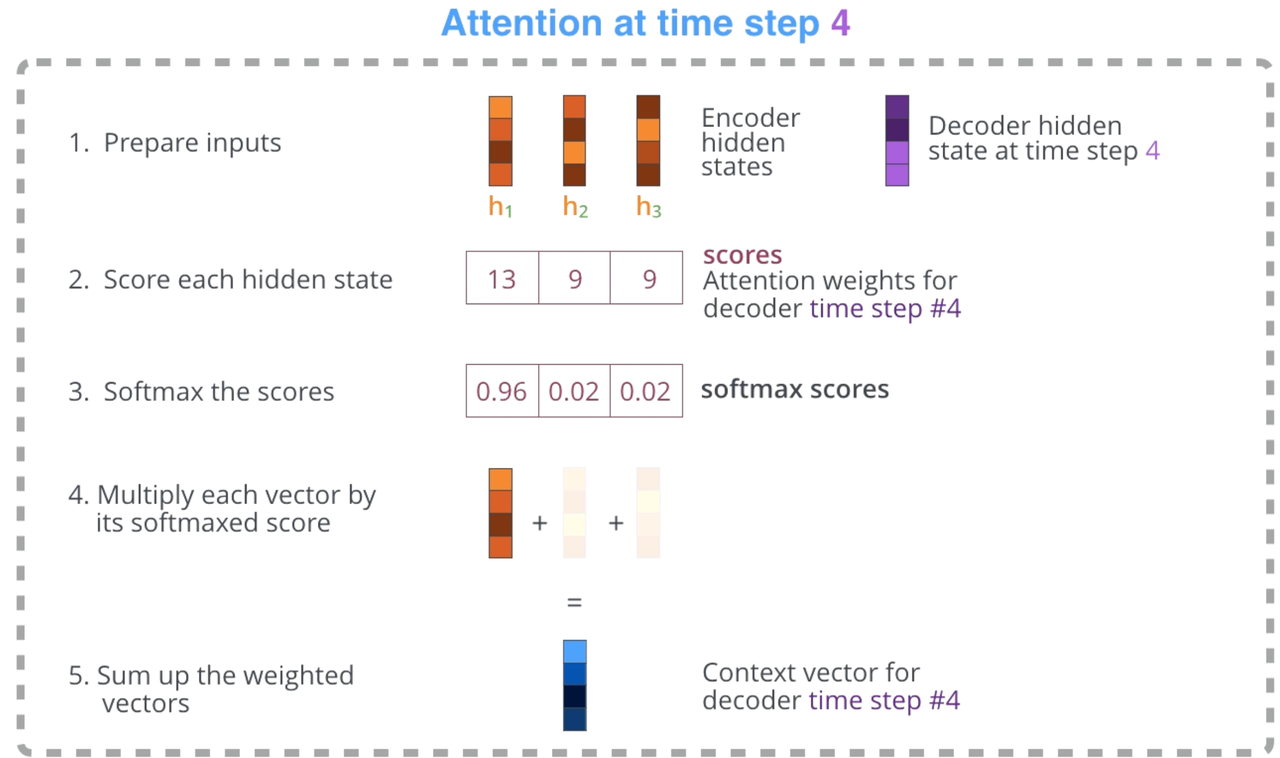
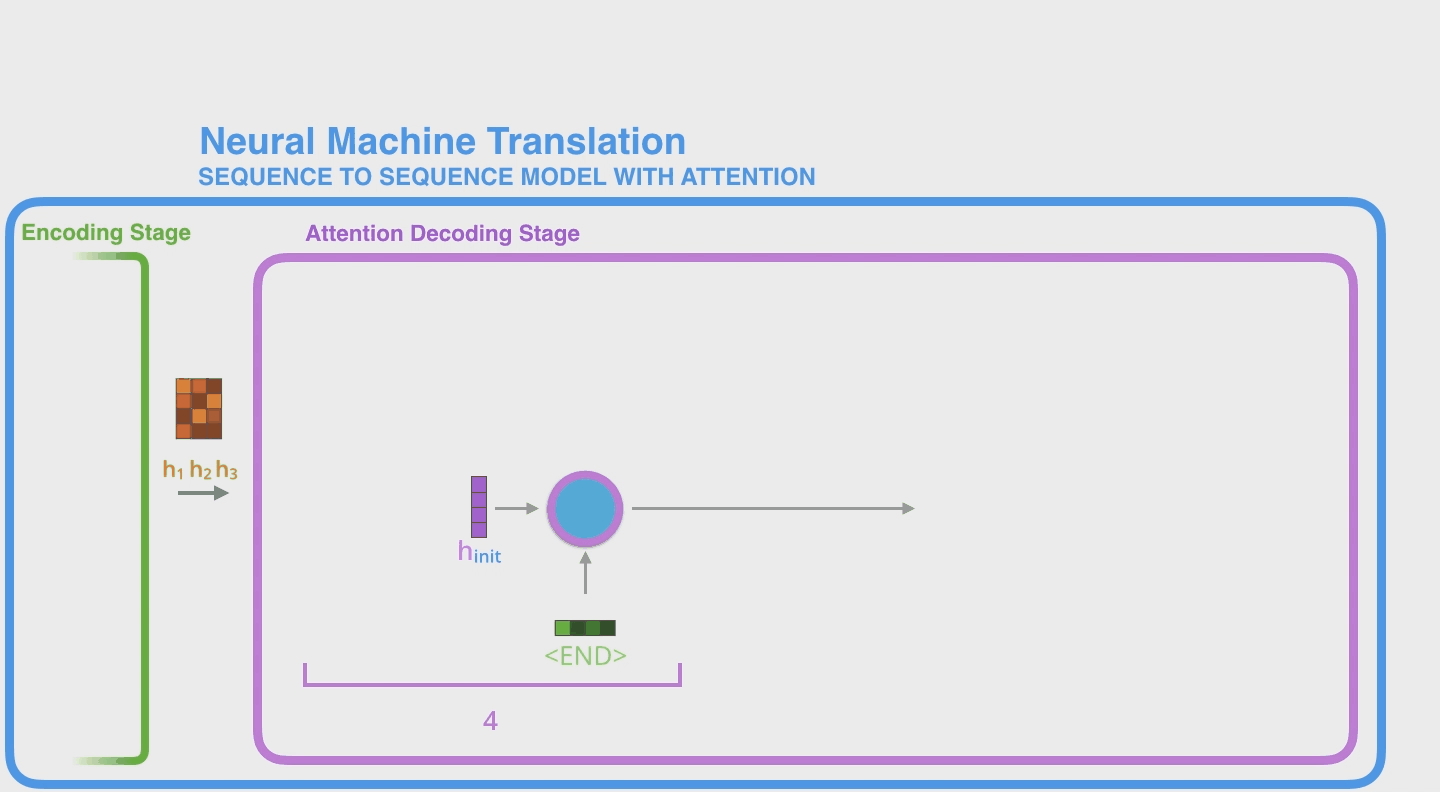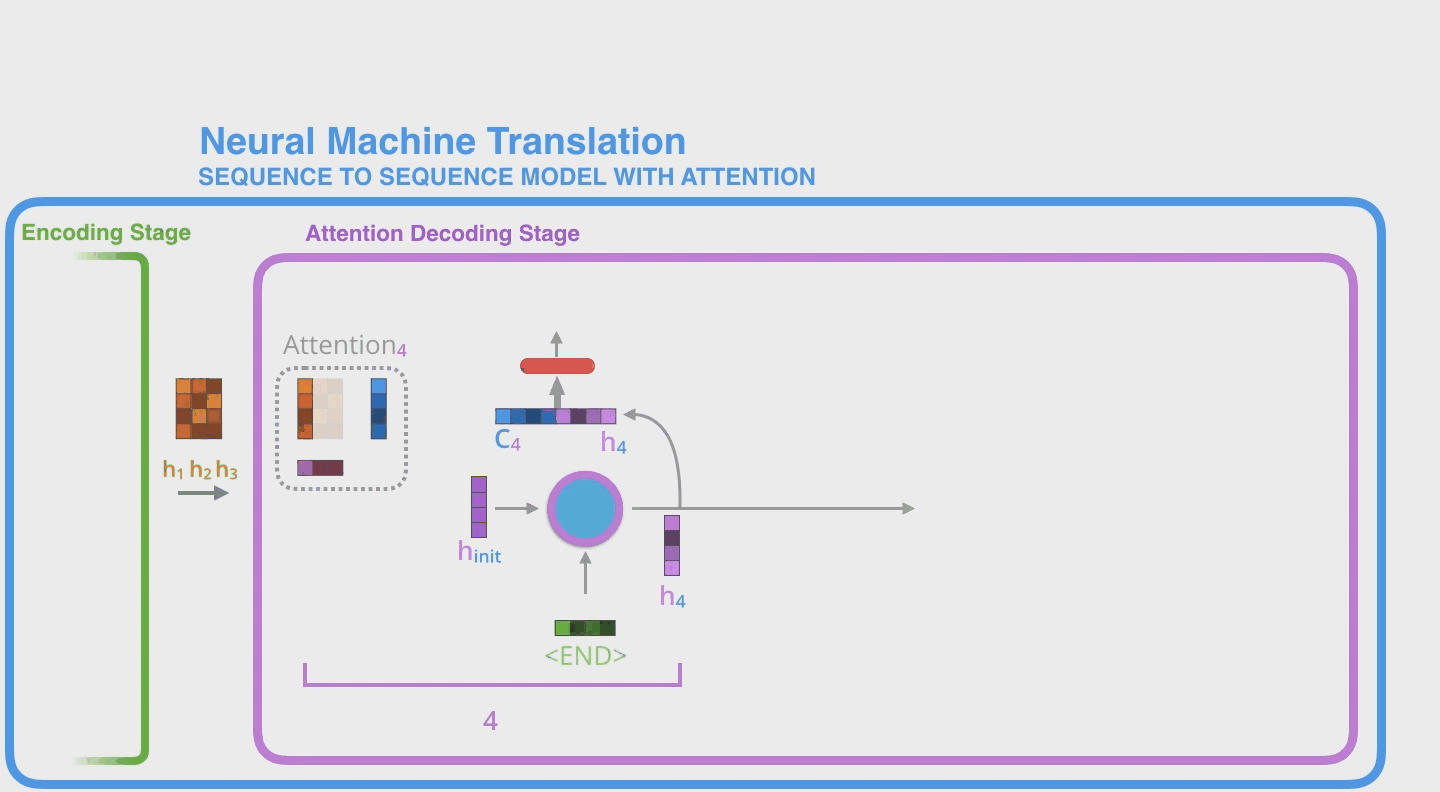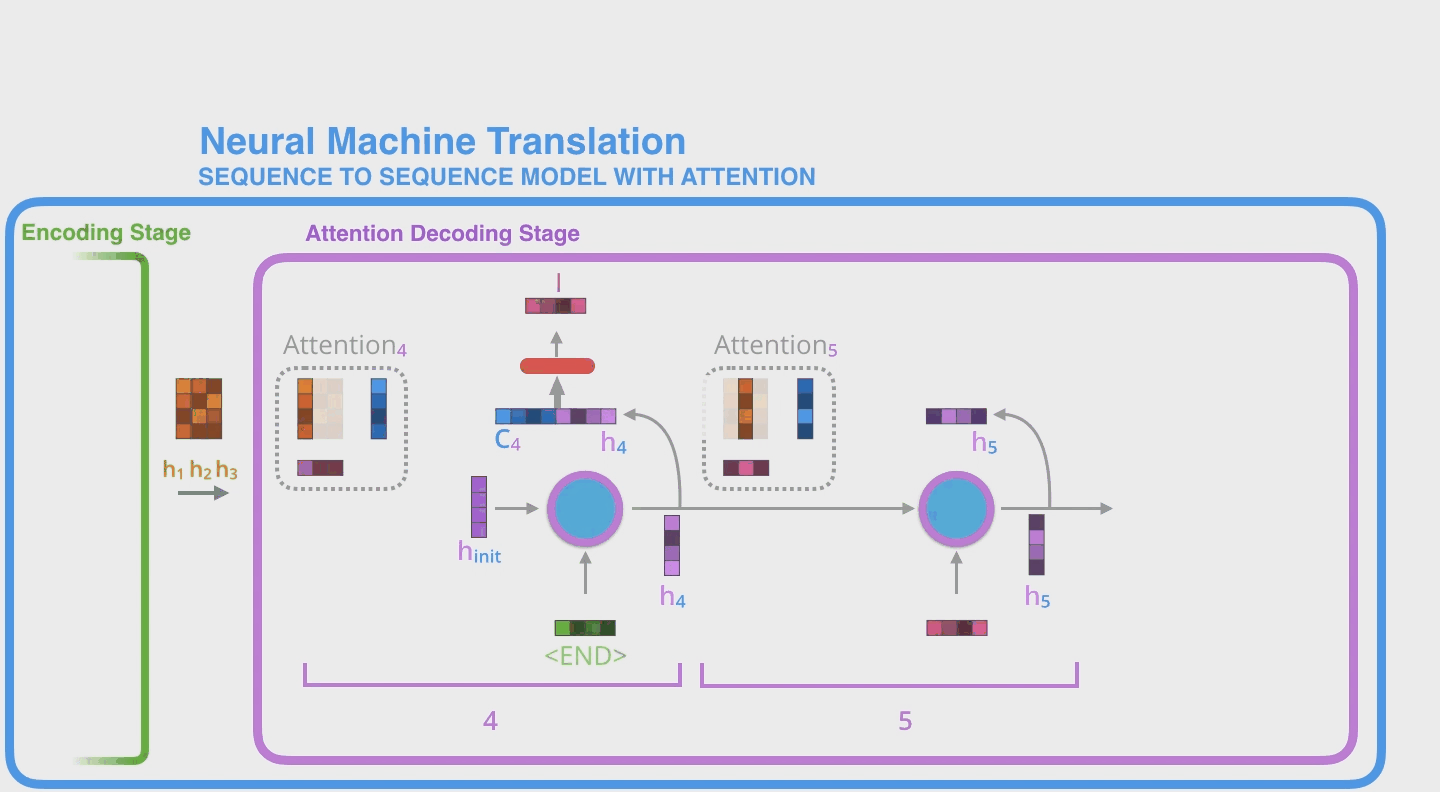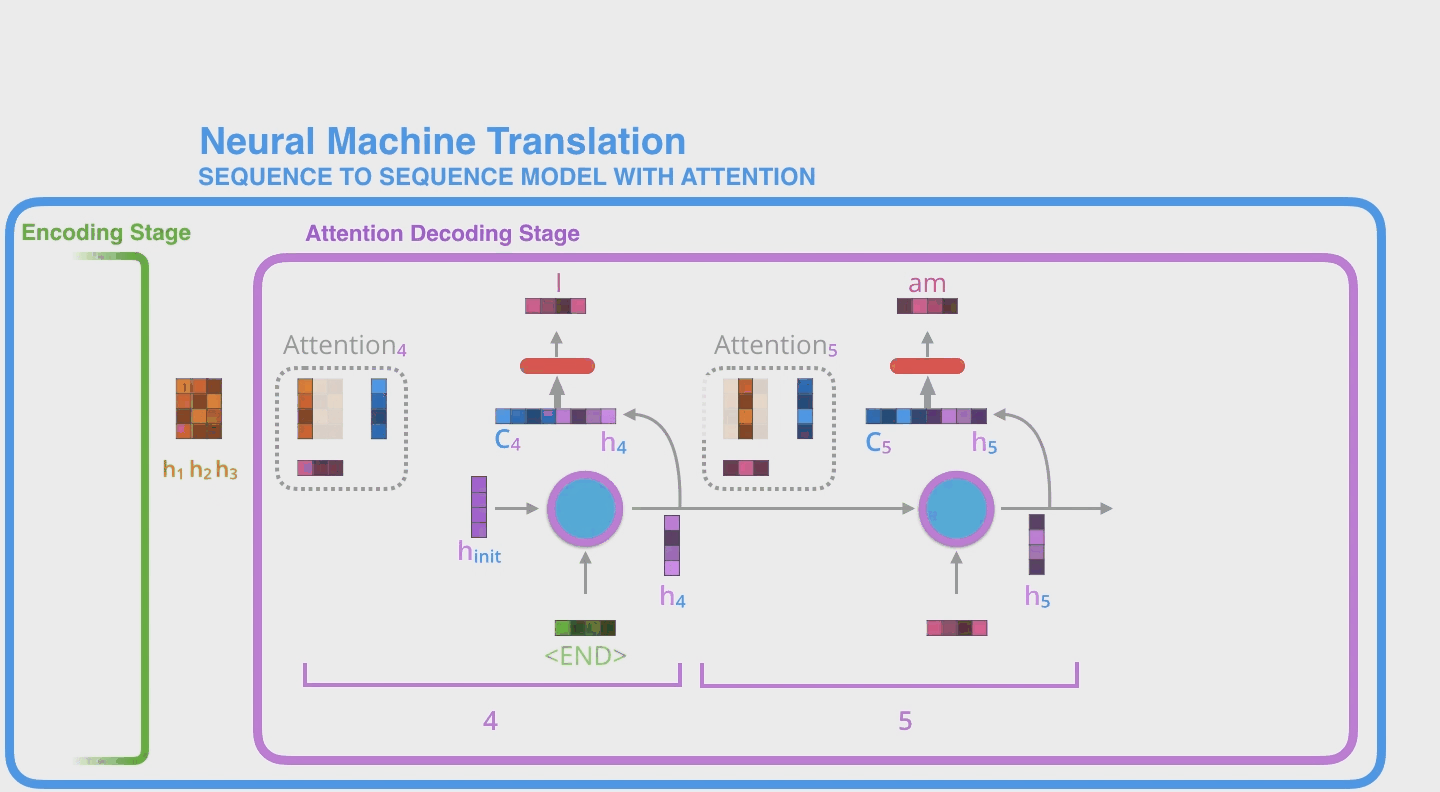
这里用一个简单的例子介绍一下 Attention Decoder 流程具体在做什么事情。这里是以 step 4 为例(这里还是延续了此前的例子,即只有3个单词的输入。因此这里的 step4 其实就指的是 Decoder 的第1个step)。Attention Decoder首先会对 Encoder Hidden States做一个打分,然后用 hidden vector 和 scores 相乘得到加权 weighted states,最后再全部相加得到这一步的最终的 context vector。
2.2 Attention 流程
整个Attention流程机制如下所示。
This scoring exercise is done at each time step on the decoder side.
Let us now bring the whole thing together in the following visualization and look at how the attention process works:
- The attention decoder RNN takes in the embedding of the
<END>token, and an initial decoder hidden state. - The RNN processes its inputs, producing an output and a new hidden state vector (h4). The output is discarded.
- Attention Step: We use the encoder hidden states and the h4 vector to calculate a context vector (C4) for this time step.
- We concatenate h4 and C4 into one vector.
- We pass this vector through a feedforward neural network (one trained jointly with the model).
- The output of the feedforward neural networks indicates the output word of this time step.
- Repeat for the next time steps
视频中以 time step 4 即 Decoder 第一步(其实就是 Encoder 结束后,因为输入单词就3个)为例:
- Decoder RNN 的输入有两个:1) 全部的 Encoder 的 hidden states;2) Decoder RNN 的上一步的 hidden states。因为这是 Decoder 第一步,因此这里用的是代表了
<END>这个单词的 embedding vector。 - 接着就是常规的 RNN 流程。得到 Decoder Hidden States output vector $\mathbf{h}_i$;
- 额外处理:对每个输入的 hidden state 打分(打分流程其实也是加上了新的权重,然后训练学习得到的,之后会说明)。打分是基于 softmax 平衡分数,使得最终 scores 在0-1之间。
- 打分后,对每个score乘以对应的 hidden vector,再相加得到最终的 attention context vector。
- 之后,将这个 attention context vector 和 Decoder RNN 返回的 hidden states 链接到一起,组成更长的向量,作为一个新的网络 feedforward neural network 的输入,然后输出就是最终的这一个 step 的 hidden states vector 了。
下面是这个流程的具体例子,用不同颜色深浅度代表 score 大小,很好显示单词之间的关联度。

另一个更⻓的机器翻译的例子,这个更明显。

3. Transformer 框架和流程
本章参考材料 Ref. [5,6,7]。
首先再来简单看一下 attention mechanism 的特点:可以将注意力集中到每一个历史单词上,实现 generate words 1 by 1。
在预测将来的每个单词时,attention机制可以将注意力集中到过去每一个关系紧密的历史单词上。
通过和 RNN 以及 GRU/LSTM 的对比可以更清楚:RNN的 reference window最小,体现为记忆力最短; LSTM/GRUs 的框架可以更⻓一些。作为对比,Attention机制理论上是可以实现无限⻓度的记忆(只要 compute resources 足够多),它可以使用到所有相关的历史context。

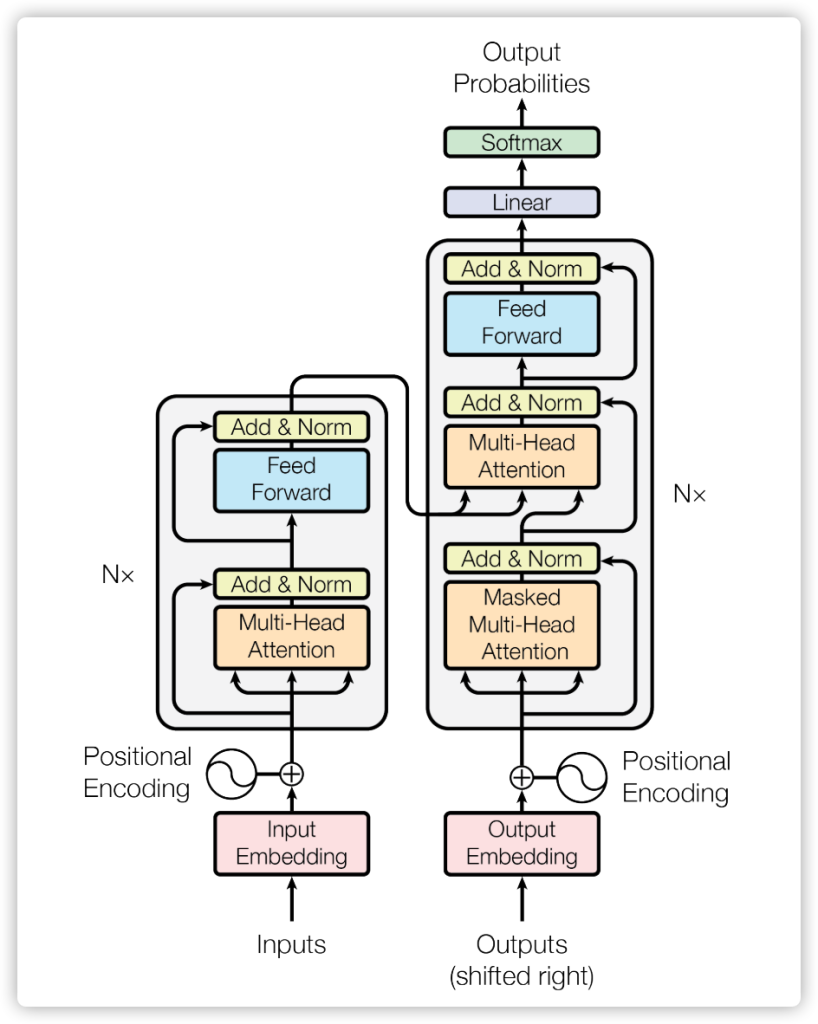
3.1 Transformer 流程图
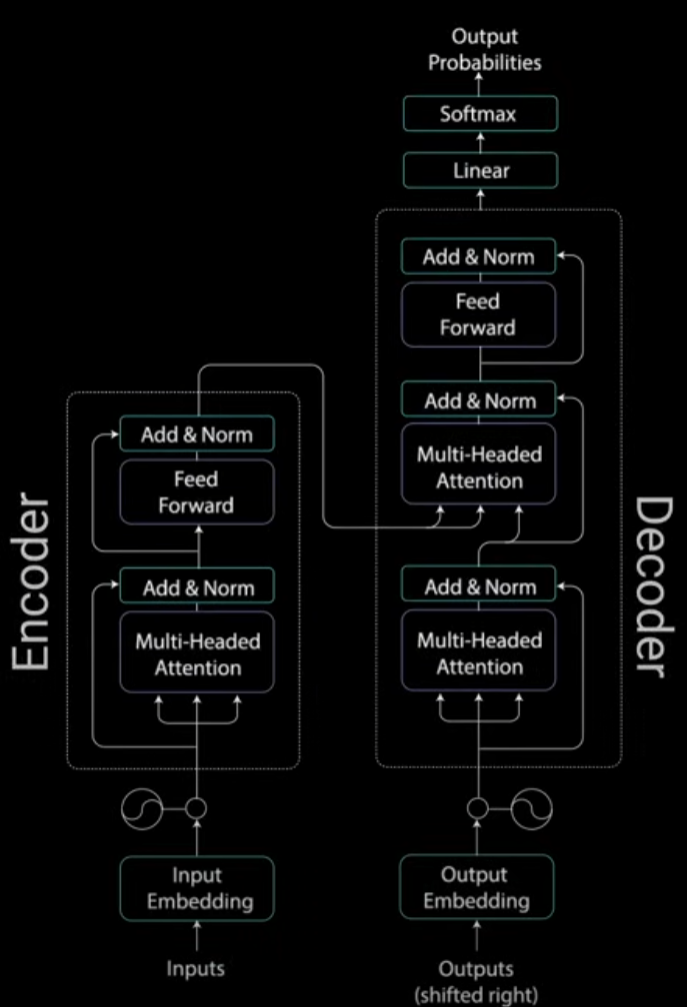
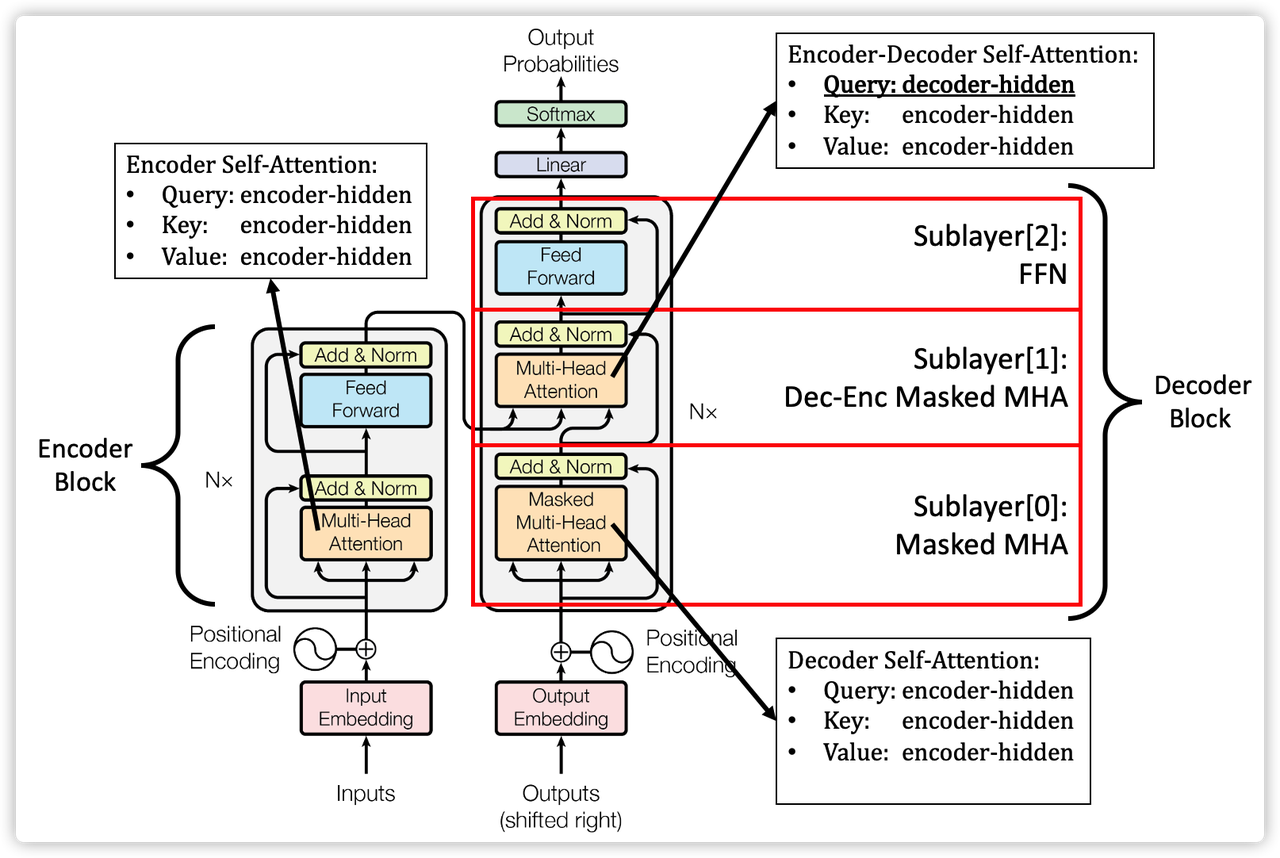
Transformer方法整体框架
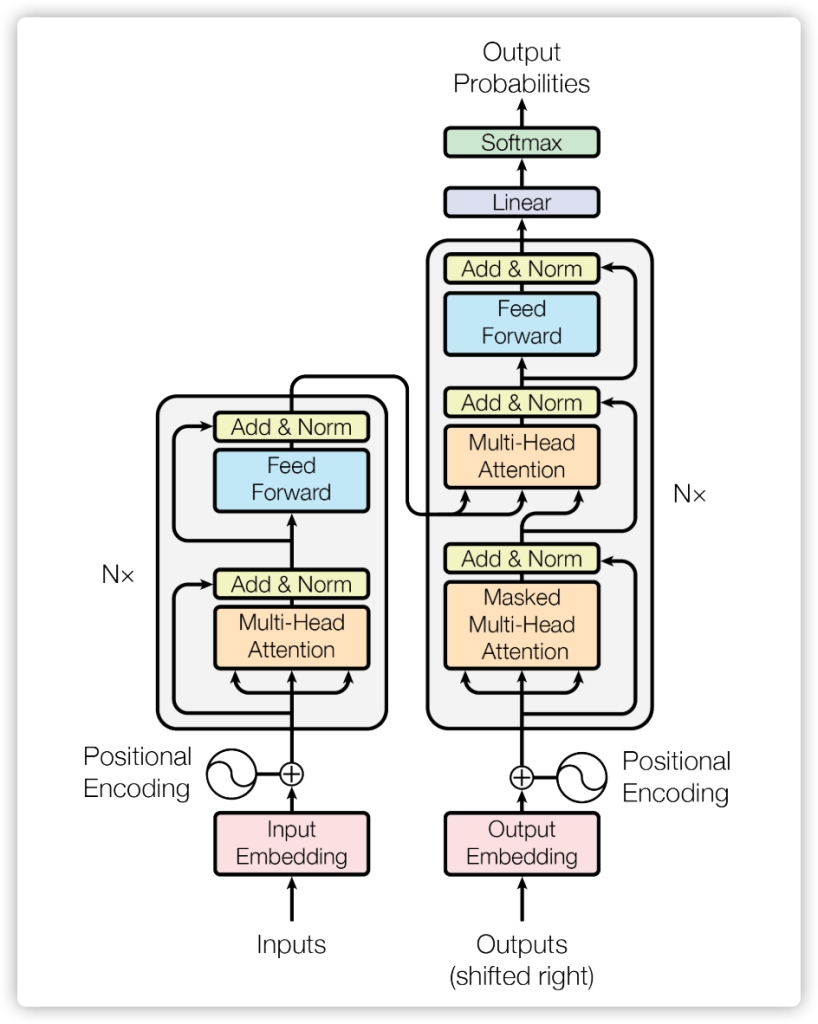
整个框架流程可以分为几大模块:
- Data Preprocessing 预处理:包含 input embedding 和 Positional Encoding。
- Encoder 模块:针对输入数据做 Encoding,核心就是 Multi-Headed Attention
- Decoder 模块:针对输入和输出数据一起做 Decoding,核心也是 Multi-Headed Attention
其中的核心框架是 Multi-Headed Attention,它实现的 Attention 机制就称为 Self-Attention。
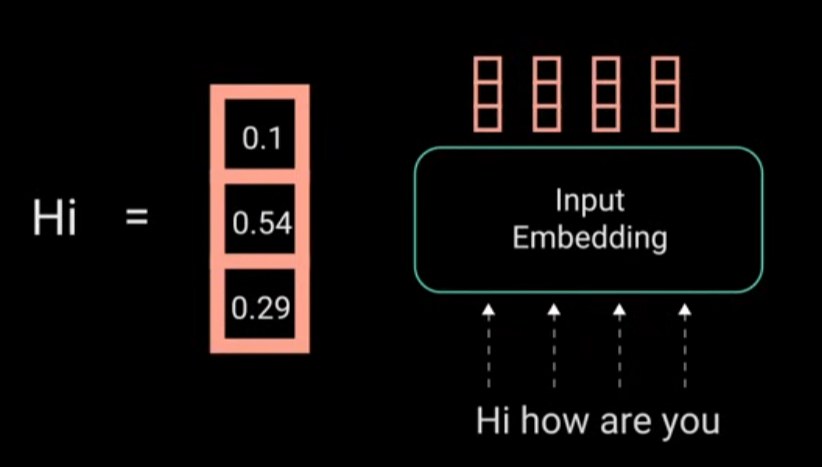
3.2 Data Preprocessing 数据预处理
数据预处理就包含两个部分: input word embedding 和 Positional Encoding 。
3.2.1 输入处理 Input Embedding
这个没有变化,前面 Section 1.3 讲过了,将每个单词映射为一个 embedding vector。图中以 Embedding Dimension=3 为例。
简单实现
用一个6个单词的句子为输入(即认为vocabulary size=6),Embedding dimension=16。
import torch
sentence = 'Life is short, eat dessert first'
sentence_split = sentence.replace(',', '').split()
# 使用当前sentence建立word-to-pos dictionary
dc = {s:i for i,s in enumerate(sorted(sentence_split))}
# 使用当前dictionary中每个单词的位置
sentence_int = torch.tensor([dc[s] for s in sentence_split])
print(sentence_int)
torch.manual_seed(123)
# Embedding会将word index映射到vector
embed = torch.nn.Embedding(len(sentence_split), 16)
embedded_sentence = embed(sentence_int).detach() # 6x16 array
而实际实现中,我们经常会用预定义的 vocabulary dictionary来定义 tokenizer,将每个word转成对应的 index,然后做 embedding。
官方实现
参考 Ref [7] 的官方代码。实现其实不难了。
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
代码中经常用 $d_{model}$ 这个参数代表 embedding vector dimension,例如 $d_{model}=512$。注意,Transformer标准流程中,做完 Embedding 后还会再乘以 $\sqrt{d_{model}}$ 做一下标准化缩放处理。
3.2.2 Positional Encoding 增加位置信息到 Embedding Vectors
- 其他参考:A Gentle Introduction to Positional Encoding in Transformer Models, Part 1 - MachineLearningMastery.
这一步就是流程图中的,接着 Input Embedding 后面的这个符号:
原文说,目的是给 embedding vectors 增加一个 word position index 信息,原因是 Transformer 中已经没有 RNN 这种 recurrent network 结构了(即分为 time steps 这种1-by-1输入的流程),而是类似一群 Linear Layers 这种,因此需要对每个单词的 embedding 做一个位置上的区分和记录。
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence.
作者的方法是增加一种特别的 position encoding 到 embedding vector 中。方法是使用了 sin/cos 函数。下图中的公式所示。

其中 $pos$ 是 position index,即前面的 step 值,即每个单词传入顺序的 index ,范围就是 $[0,T-1]$, $T$ is max length of all sentences。而 $i$ 是在 embedding dimension 中的 index 位置,它的范围是 $[0,D-1]$,而D是 embedding dimension size,即图中的 $d_{model}$
上面公式是针对奇数和偶数的 embedding index 位置交替使用 sin/cos 函数计算。不难看出,最终每个单词的 Positional Embedding 结果也是长度 $D$ 的向量,因此可以和原始的 vector embedding X 相加,得到最终的 Positional Embedding Vector。即结果:X = X + PE。它会作为后面的整个 Encoder Layer 的输入。
指的注意的是,Positional Embedding 这个计算流程是独立于 X 存在的(即它并非X的函数),它不包含待训练的参数(代码中可以用 requires_grad_(False) 标明)
官方实现
来自Ref. [7] 中的官方实现: https://nlp.seas.harvard.edu/annotated-transformer/#positional-encoding
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
# 注意这里只计算偶数位置,对应就是公式中的2i。
# 另外这里用了exp(i*log10000)=pow(10000,i)来计算后者
div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)
)
# 按照位置的奇偶性来分配sin or cos计算
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # 最后增加最前面维度,方便和输入的x相加
self.register_buffer("pe", pe)
def forward(self, x):
# x: (b,T,d_model), pe: (1,max_len,d_model)
# T通常是这个batch中的所有sentences的max length(其实经常它就等于max_len)
# max_len则通常是整个数据集全部sentences的max length,所以max_len>=T
# 因此下面两者可以相加
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return self.dropout(x)
NOTE for this code:
- 它使用了 exp 和 log 结合的方式来公式中的 power(10000, 2i) 运算。
- 注意公式中的 2i 和 2i+1 只是为了区分奇数和偶数位置。实现中,2i会作为整体传入,而它显然就是个偶数。因此 div_term 中只实现了偶数位置的计算,而在下面一行的 pe 计算时,分成 sin/cos 计算并放在 pe 中的对应的奇数和偶数的位置。
- 注意,Positional Embedding 的实现是无需参与训练的,因此要设置为 requires_grad_(False)
3.3 Encoder 流程图
整个 Encoder Layer 以及 Encoder Input 形式是这样。它包含了 N 个重复模块,每个模块称为一个 EncoderLayer,其中的核心是 Multi-Headed Attention 以及 Feed Forward。接下几个章节分开介绍。
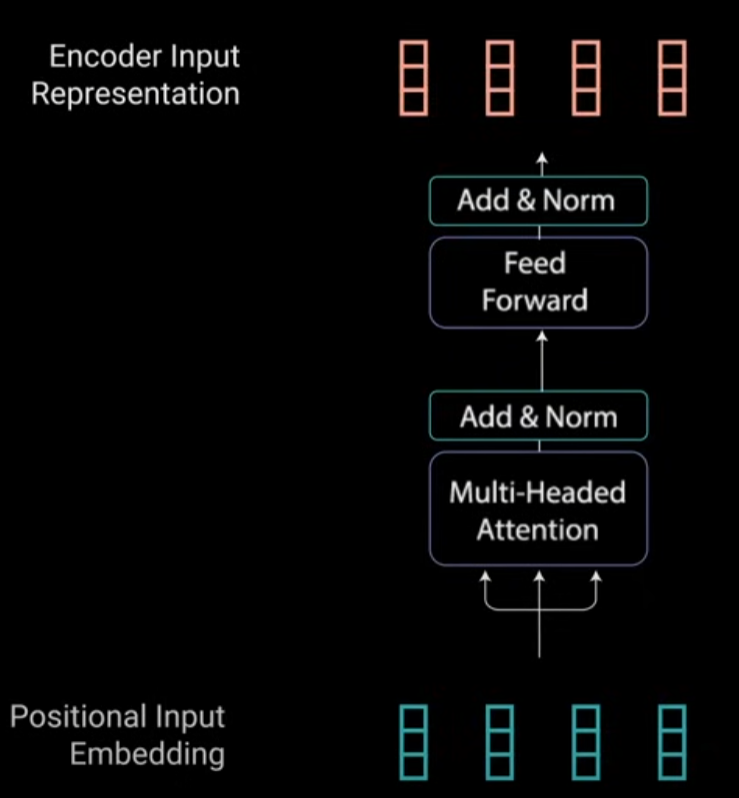
3.4 Self Attention 单头注意力机制
Multi-Headed Attention 多头注意力机制的核心还是 Self Attention,也可以认为是 Single Headed Attention 单头机制。
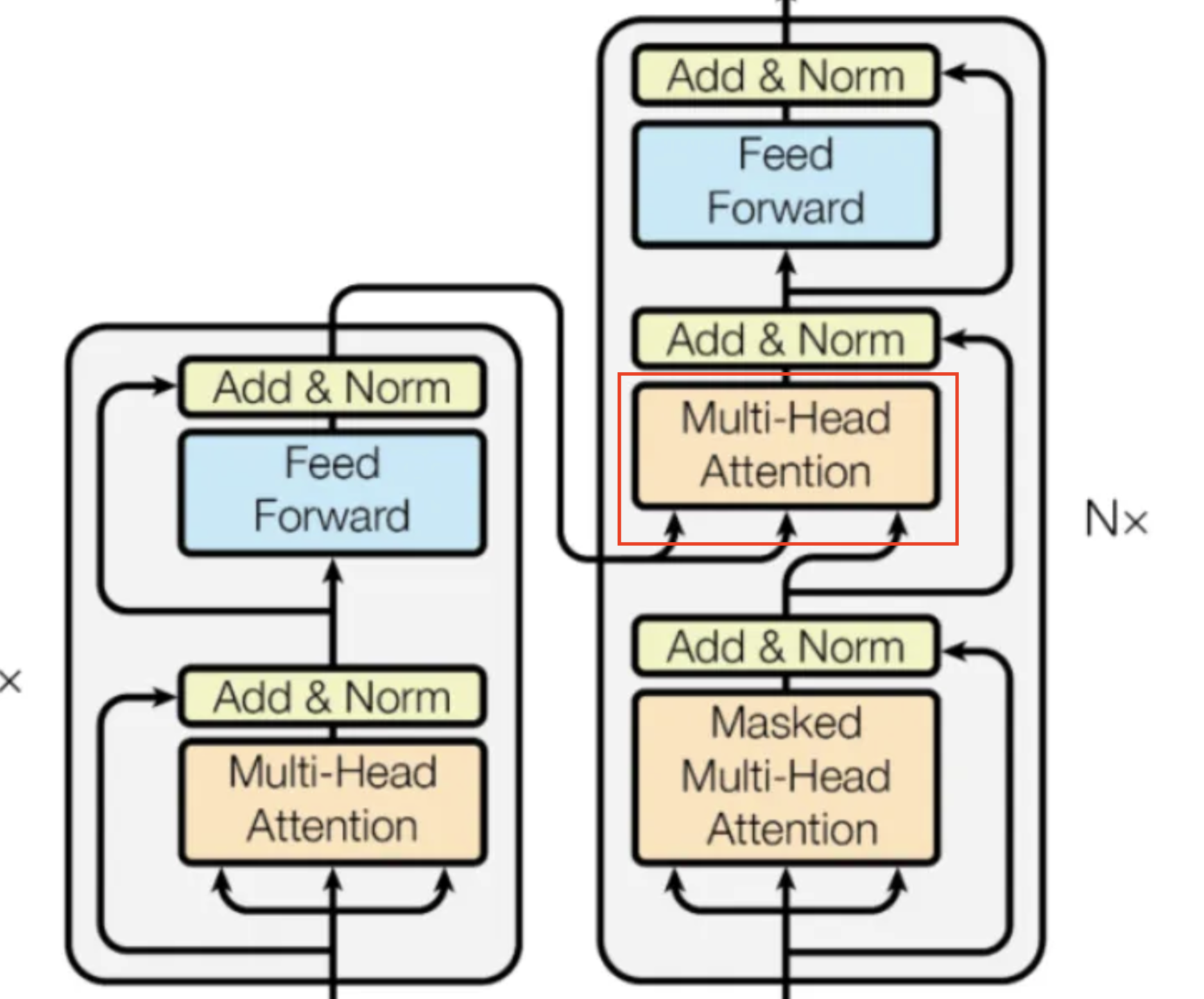
Self Attention的流程如下图所示(注意不包括最上面最后的两个Concat和Linear层,它们是Multi-Headed Attention用的)。其核心是将上一步的结果即 Positional Embedding Vector 分成三个分支 Q, K, V 再分开处理。
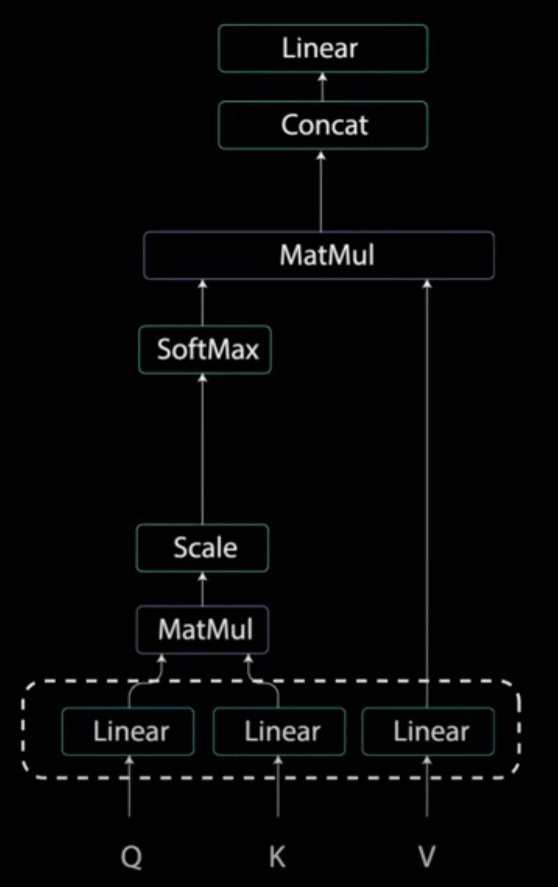
详细流程如下图。接下来分成多个小节分开解释。
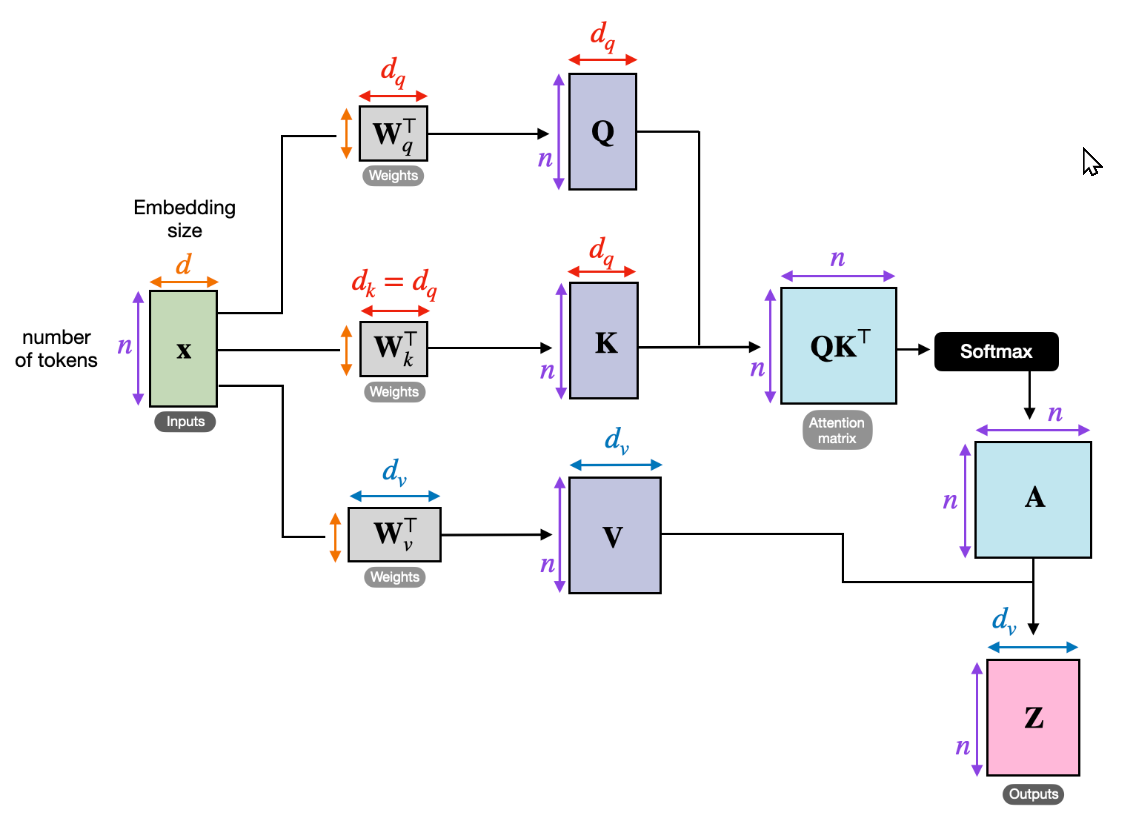
Self attention模块的输入 x 是 embeded vector array,图中记为 $n \times d$ 维度, $n$ 是 number of tokens(代码实现中经常记为 seq_len,定义为当前batch的所有句子的最长的单词个数max length of tokens/words of all sentences in the batch), $d$ 就是 embedding vector dimension,比如常见例子是512。
1) 通过 Linear Layers 计算 Q, K, V
首先 Encoder Layer 会将输入的 Positional Embedding Vectors 传入三个 Linear Layers,分别是 Query, Key, Value层,得到三个数组 Q,K,V。从图中不难看出,Q,K 的 embedding 维度是相同的,即 $d_q=d_k$ ,而 V 的 embedding 维度是 $d_v$ 可以不同。在 Self Attention 中,这三个量全都相同,例如一个常见的例子 $d_q=d_k=d_v=64$ 。而在 Cross Attention 中则两者会不同(后面讲)。
2) Q and K 点乘得到 Scores 数组
直接两个数组相乘:
\[Scores=QK^T\]Scores数组代表了每个输入向量(即单词)和其他单词之间的关系程度(比如数值越大代表关系越紧密),也代表了模型会尽量 focus 到那些单词上。它是 $n\times d$ 的方阵。其中每一行 ith row 就代表了 ith word 和其他所有 words 之间的 attention scores,即关系的紧密程度等。
这里是一个 $d_q=d_k=d_v=3$ 的例子(注意下图左边Q和K的维度颠倒了,应该是Q是4x3,K是3x4才对)。右图是一个scores的例子,可以表明单词之间的相关性。
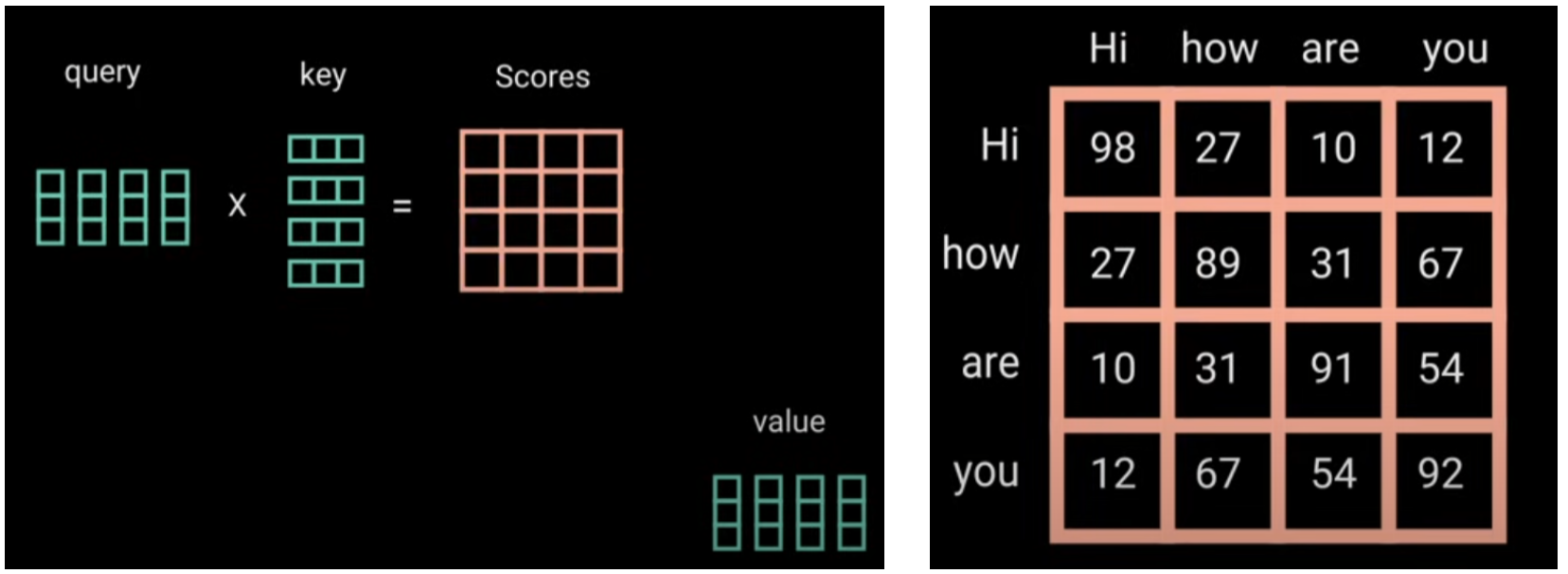
3) 修改尺度 Scaling Down Attention Scores
这里就是简单将 Score matrix 除以 $\sqrt{d_k}$ ,目的是将 scores 结果尽量分布到scale相差不太大,方便更加稳定的计算导数,避免数值过大导致gradient exploding(因为矩阵相乘容易使得数值过大)。
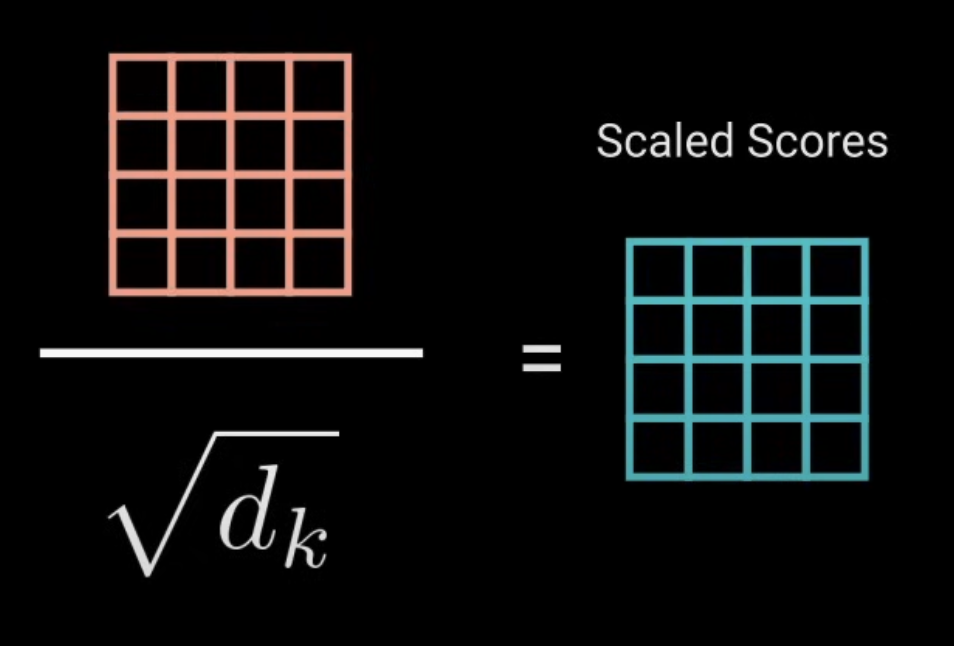
Attention Scores 数组的含义其实就是每个 token 和其他 tokens 的关联度打分。
4) 使用 Mask 屏蔽 Invalid Tokens (Optional but common)
前面得到的 Attention Scores 数组的含义其实就是每个 token 和其他 tokens 的关联度打分。不过,数据中经常会存在 invalid tokens,例如那些不在 vocabulary 中的 words,又或者是句子末尾补上的 pad 0。后者的原因是,我们的训练数据比如句子的 words 个数即每个句子长度显然很可能不同,而训练中的Batch则必须是一个固定大小的数组,例如 (batch_size, seq_len),其中 seq_len 是一个对于当前batch的固定值,通常设定成当前batch中全部句子的最大长度(有时也会设置成一个全局的整个数据集的全部句子的最大长度)。因此,不难看出,batch中会有很多句子会提前结束。那么句子结束到 seq_len 这一段如何处理?通常我们的做法是给这一段pad一个默认的invalid index,例如 pad 0,并把 id=0 认为是一个 invalid token(而如果一个word不在dictionary中,也被认为是invalid token而赋予id=0)。这样的话,在计算 scores 数组时,我们要排除掉这些 invalid token 和其他 tokens之间的关联,即将scores中的这些 invalid tokens 所对应的都设成0,即将这些位置mask掉。
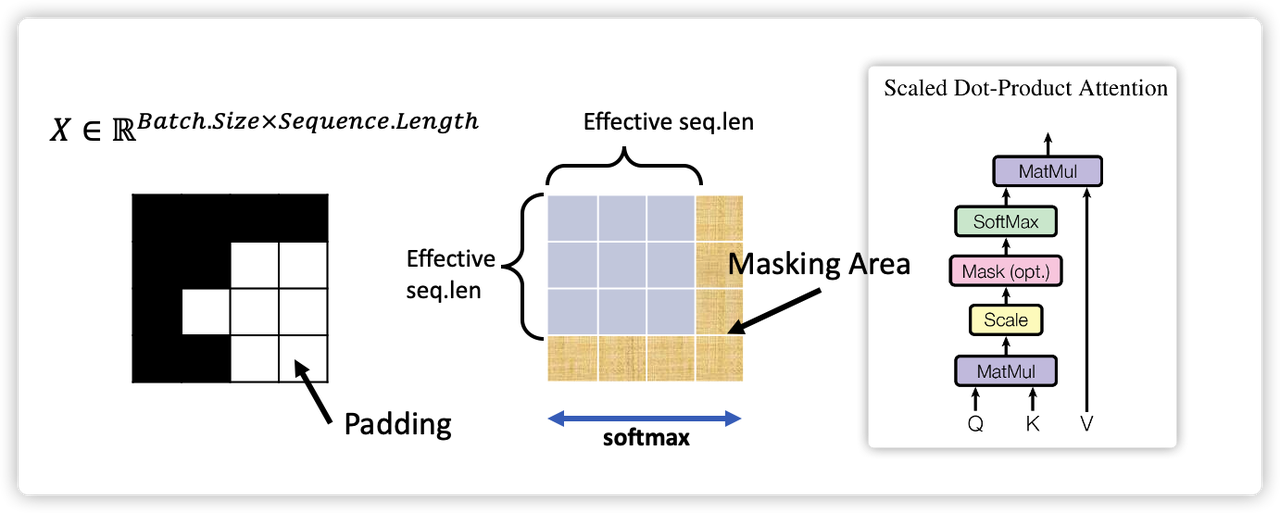
这个实现就比较直观了,我们只需要设计一个针对 words ID 的一个binary mask,将那些 ID=0 的位置标记出来为0,剩下的是1即可。例如,如果 word ID 数组是 src is (batch, seq_len),保存的是batch每个句子每个单词对应的 word integer ID,创建它的时候已经做了 pad 0 操作在每个句子末尾。因此,它对应的 mask 就是 src_mask = (src != pad) ,where pad=0,很简单。而为了后续使用,还要接着用 unsqueeze(2) 操作变成 (batch_size, 1, seq_len),这样就可以作用到 scores 数组上。
scores数组是 (batch, seq_len, seq_len)。方法可以使用 scores **=** scores.masked_fill(src_mask **==** 0, **-**1e9)。这里 masked_fill() 支持 broadcasting,它会将 mask (batch_size, 1, seq_len) 先变成 (batch_size, seq_len, seq_len) 然后再将scores中对应的masks是0的位置设置为一个极小值 -inf。之所以不是0,是因为,接下来我们要用 Softmax(Scores)来将 scores 转成 [0,1] 之间的类似概率的值。而 Softmax 计算公式是 e^x/sum(e^x),只有e^(-inf)=0才成立。因此要设成极小值才行。
不过,在 Encoder 和 Decoder 中使用的 mask 不同,这是因为 Encoder 的输入通常是整个数据集,即我们能见到过去和未来全部信息,因此这时的 mask 就是如上面所示。而 Decoder 则不同,它通常是每次只能预测未来一个单词,因此对于当前的单词,它没法知道未来信息。因此这时的 mask 的设计需要屏蔽掉未来单词的影响。具体参见后面 Decoder 中的介绍。
5) 使用 Softmax 平衡 Softmax of Scaled Scores
接着是对全部的 scores 数值做 softmax,目的显然就是将数值转变为概率值,同时数值较大的score就会显得更大并且比较接近1.0,较小的score会进一步压缩为更小的。这使得后面更加容易focus 到较高的 scores 上面。
这一步后得到的结果就是最终的 attention score matrix。
\[A=\textbf{Softmax}(Scores)\]注意 Softmax 的计算是在最后一个维度即dim=-1上。如果是上面的图例的话就是右图中的横向的维度,它会将每一行的scores数值变到0-1之间,同时保留相对大小(而同一行的scores总和是1.0)。

6) 将 Softmax Scores 和 Values 相乘
很直接
\[\textbf{Output}=AV\]不过注意这次数组相乘的顺序是刚刚得到的 attention score matrix A 在前面,V在后面。从前面流程图看出,A is $n \times n$ ,而 V is $n \times d_v$ ,这样相乘后才会得到 $n \times d_v$ 的最终结果.
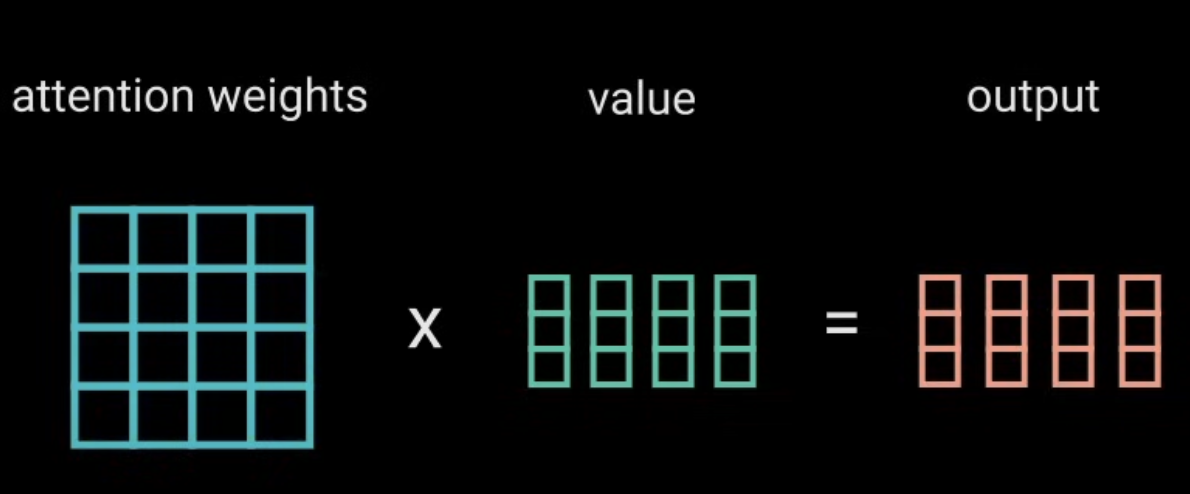
总结流程
用简单的计算公式总结一下整个 Attention 的流程如下:
\[\begin{align*}Q,K,V &= Linear_Q(X),Linear_K(X),Linear_V(X)\\Scores &= QK^T / \sqrt{d_k}\\Scores &= Mask(Scores) \\A &= Softmax(Scores) \\Output &= AV\end{align*}\]官方实现
具体在 Ref [6] 的 Encoder Decoder 介绍中: https://nlp.seas.harvard.edu/annotated-transformer/#encoder-and-decoder-stacks
另一个 pytorch 中的官方实现:https://docs.pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html
这里我只给出Attention实现。注意它其实输入就是Q,K,V,它们在调用前就得到了,当然只需要经过三个Linear layers,也很直观。
# Attention定义
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
# Q,K,V的维度个数不确定,self attention时候是(b,n,d),而multi-head attention
# 则会是 (b,h,n,d)。不过无论哪一种,我们只针对最后两个维度做矩阵相乘,因此只需要转置
# K的最后两维。而 torch.matmul(A,B) 计算中,如果A,B前1个或2个维度相同,那么它只做
# batch multiplication,即只针对每个batch的最后两个维度做乘法,保留前面的维度.
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# mask在后面 Decoder中的attention才会用到,目的是消除和未来单词之间的关联,因为在
# Decoder中,单词是逐个预测的,而不是像Encoder这样把整个句子全部单词全扔进去训练。
# 由于scores含义就是每个单词和其他单词之间的关联程度,因此显然单词不能和未来单词相关联,
# 于是要用mask(通常是一个下三角数组)将上三角部分给清掉。这里用了-1e9一个很大的负数,是为了
# 使得计算 softmwax 后这个值变成0.
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# softmax针对最后一个维度
p_attn = scores.softmax(dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
# (n,n) x (n,d_v) = (n,d_v)
return torch.matmul(p_attn, value), p_attn
3.5 Multi-Headed Attention 多头注意力机制
Multi-Headed Attention 其实就是上面的 Single Head 的扩展,它就相当于是 Single Head attention 的多个 copy 而已,相互的 head 之间甚至没啥联系,即每个 head 有自己单独的query, key, value矩阵(这和RNN那种稍微复杂一点的多层还不一样,后者是层之间有联系的)。出发点是,每个 Head 会学到不同类别的关联信息。流程是下左图。
多头注意力机制其实就完全是使用了 $h$ 个 Self Attention 并行而已, $h$ is number of heads,没有其他特别之处。如下左图的 two-headed attention。当然,因为维度升高了一维,即多了一个 h,因此实现上稍有区别。另外,当Attention计算完成后,需要将全部 heads 的结果给再次合并 concatenate 起来,最后再经过一层 Linear,如下面右图。
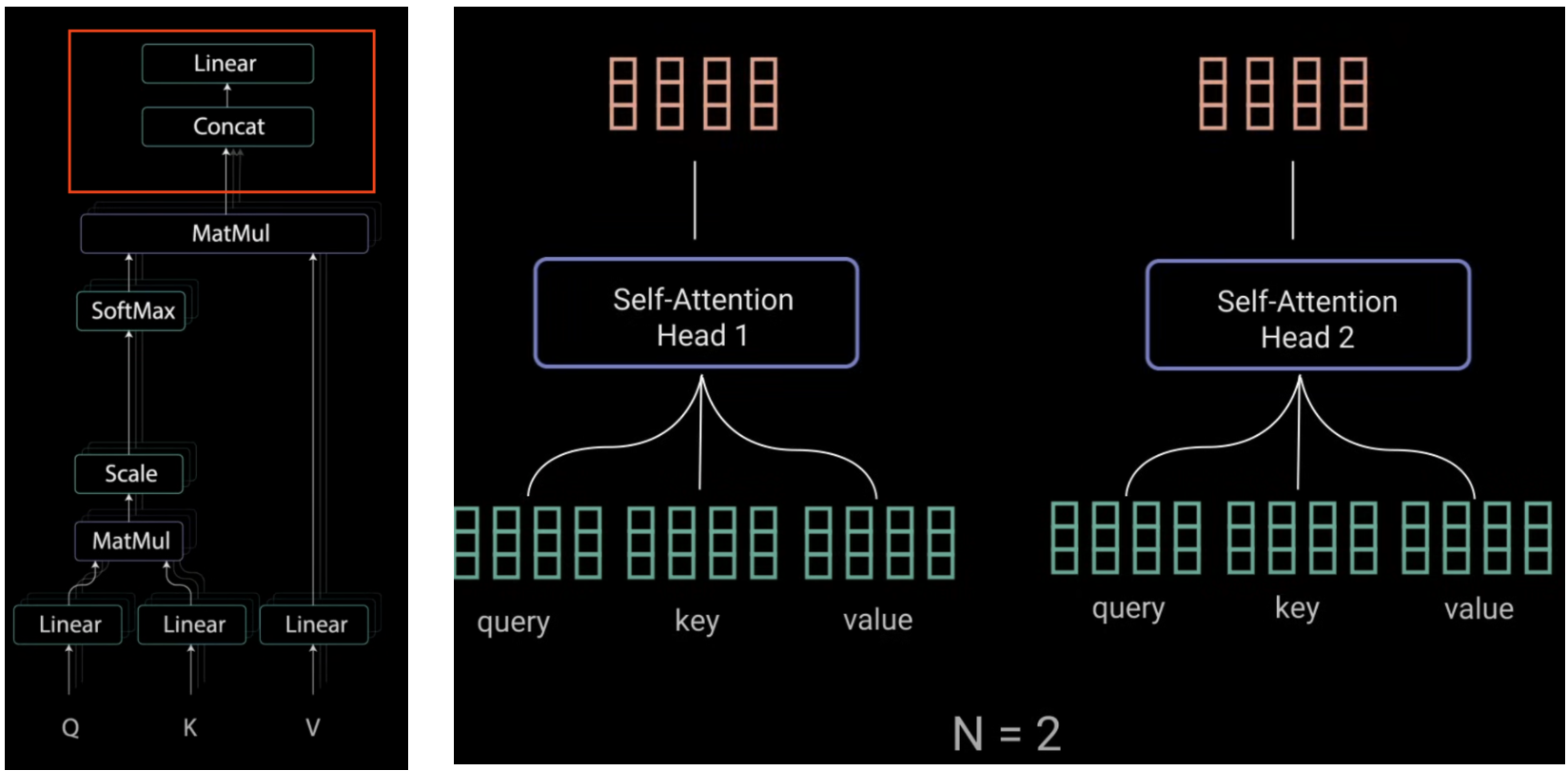
流程上可以看出,多头注意力机制首先还是用 attention 机制,只是用在多头上。不过注意,最后 attention 结束后,还要把所有heads的结果给合并 concatenate 到一起,最后再过一层 Linear Layer(流程图中的上面红框)。而 self attention 则不需要这一步。
官方实现
官方代码在这一节:https://nlp.seas.harvard.edu/annotated-transformer/#encoder-and-decoder-stacks
多头机制还是会调用self attention,如前面的代码。
官方实现中,attention() 方法的输入直接就是Q,K,V,而它们的计算是在外面实现的。这是为了方便 self attention 和 cross attention 可以用同一个attention接口,只是Q,K,V的实现不同而已。多头机制中会再引入一个新的参数 h 代表 number of heads(一个常见的值是 h=8),而此时 Attention 的输入即 embedding vector array 会因此多了一个维度,从前面讲的 $(b, n, d_{model})$ 变成了 $(b,h,n,d_k)$ ,其中 h is number of heads,而 $d_k = d_{model} // h$(取整数)。即,其实它就相当于将最后一个维度 $d_{model}$ 给分解成两个维度 h 和 $d_k$ 了,变化流程是: $(b, n, d_{model}) \rightarrow (b, n, h, d_k) \rightarrow (b, h, n, d_k)$ ,其中最后一步是转置了第1和2这两个维度。这种维度增加和变化并不会影响 Attention 的计算,因为我们只针对这里的 Q,K,V 的最后两个维度做计算。
例如,经常用 d_model=512, h=8,那么此时 $d_k=512/8=64$(其实这里的 $d_k$ 就是前面Attention机制中的那个 $d_k$ )。
# Multi-Head Attention中生成Q,K,V并调用Attention
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
...
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
...
def forward(self, query, key, value, mask=None):
# 通常输入的Q,K,V还是三个维度 (batch_size, seq_len, d_model)
if maskisnotNone:
# mask: (batch_size, 1, seq_len, seq_len), for h heads
mask= mask.unsqueeze(1)
batch_size= query.size(0)
# 对Q,K,V都经过对应的Linear层。下面是一个简洁写法。
# (batch_size, seq_len, d_model) -> (batch_size, seq_len, h, d_k)
#NOTE: 1) these two lines are equivalent to the following commented lines for each of query, key, value:
# 2) the zip(A,B) operation can align the length of A and B by taking the minimum length of the two, and
# here A,B could be either list or tuples.
query, key, value= [
lin(x).view(batch_size,-1,self.h,self.d_k).transpose(1, 2) for lin, xin zip(self.linears, (query, key, value))
]
"""
# 上面的简单写法展开后如下所示,下面是以Query为例,K,V类似。
## Split the above lines into the following commented lines for each of query, key, value:
# (batch_size, seq_len, d_model)
query = self.linears[0](query)
# (batch_size, seq_len, h, d_k), since d_k = d_model // h
query = query.view(batch_size, -1, self.h, self.d_k)
# (batch_size, h, seq_len, d_k), since we want to compute attention on the last two dimensions, for each head
query = query.transpose(1, 2)
"""
# 直接调用attention()方法,里面已经设计好,可以处理多头机制
# x: (batch_size, h, seq_len, d_k), attn: (batch_size, h, seq_len, seq_len)
x,self.attn= attention(query, key, value, mask=mask, dropout=self.dropout)
# 合并全部heads的结果,然后恢复 (batch_size, seq_len, d_model) 的形式
# concat results of all heads together and merge the two dimensions.
# (batch_size, h, seq_len, d_k) -> (batch_size, seq_len, d_model), since d_model = h * d_k
# What this line does is:
# 1) transpose(1, 2): Swaps dimensions 1 and 2, changing tensor from shape [batch_size, h, seq_len, d_k] to [batch_size, seq_len, h, d_k]
# 2) contiguous(): Makes the tensor contiguous in memory after transposing, which is a MUST and required for view() to work correctly, otherwise
# it will raise an error during runtime (since transpose() only changes the "viewing" shape of the tensor but not the memory layout, while the
# view() function MUST take a continuous tensor to reshape).
# 3) view(batch_size, -1, self.h * self.d_k): Reshapes the tensor to [batch_size, seq_len, d_model] where d_model = h * d_k
# The -1 automatically calculates the seq_len dimension based on the total number of elements
x= x.transpose(1, 2).contiguous().view(batch_size,-1,self.h*self.d_k)
# It might be not that necessary to release memory here, but just to be safe that they won't be used anywhere else after this.
del query, key, value
# 最后经过Linear层
# Remember to run the last linear layer. (batch_size, seq_len, d_model) -> (batch_size, seq_len, d_model)
return self.linear[-1](x)
3.6 Encoder中 Attention 后的其他操作
流程上看,多头注意力操作后,还有几个相关的操作。如下右边图。可以看出它要经过两个 Add & Norm,并且中间夹一个 Feed Forward层,下面说明。
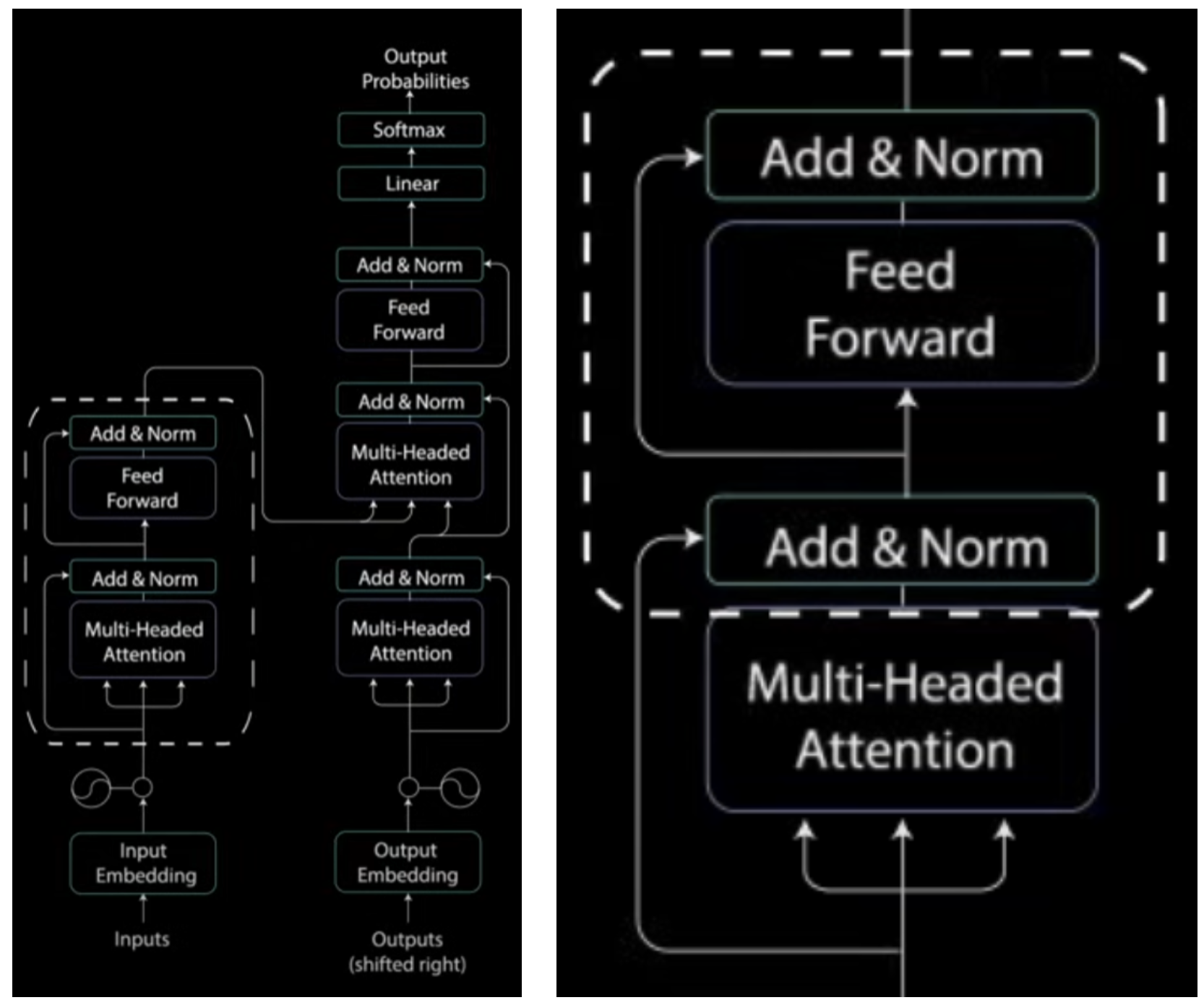
1) Residual Connection
这个就是直接将 Muti-Headed Attention 的输入 X 和输出加起来即可。多头注意力机制中最后有一层 Linear,可以确保输出的 dims 和输入 X 尺度相同。
\[X = X + Multi\_Headed\_Attention\]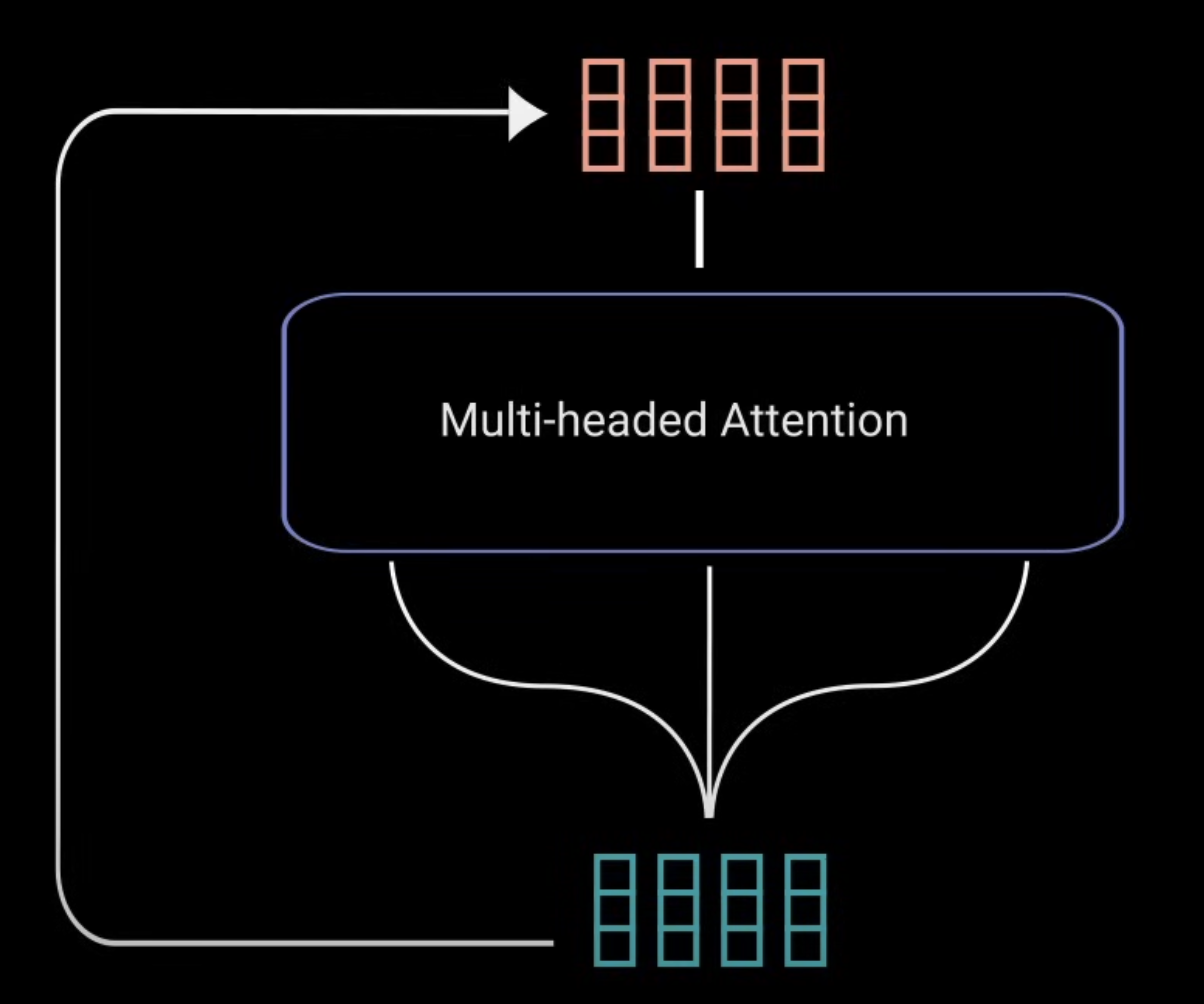
2) Layer Normalization
针对上一步的 Residual Connection 结果,做一个 LayerNorm(.)。 官方代码中,LayerNorm只作用在最后一个维度即 d_model 维度上。
LayerNorm Ref: https://docs.pytorch.org/docs/stable/generated/torch.nn.LayerNorm.html#torch.nn.LayerNorm
3) Position-wise Feed-Forward Networks
针对上一步的 Layer Norm 的结果,引入这个 Position-wise Feed-Forward Module(有时也被称为 Point-wise)。它只包含两个Linear Layers以及中间的一个 ReLU 层。并且注意,这个结束后,在最后还会再次引入一个 residule connection。
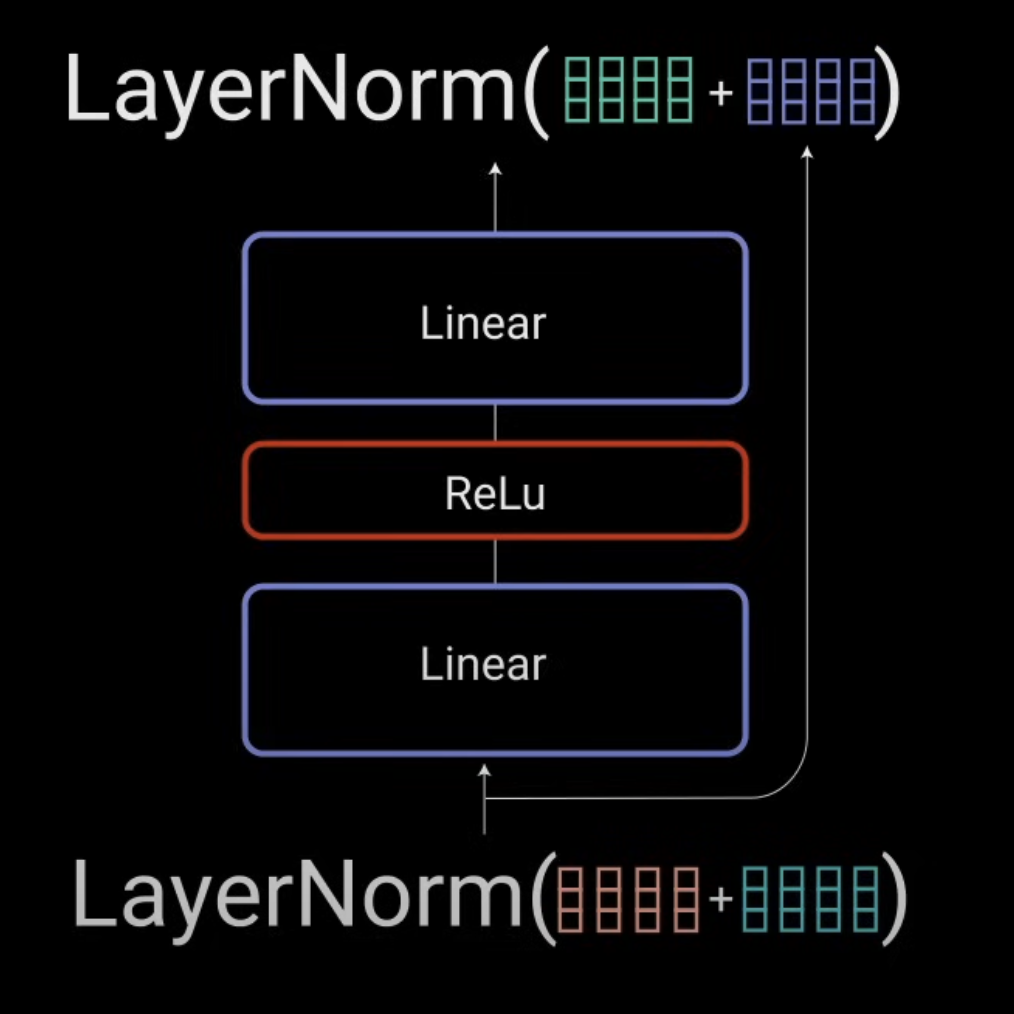
不过注意一点,代码实现时,这两个Linear Layer中间的hidden layer dimension 可以升维,例如代码中第一个 Linear Layer 的输入和输出维度使用了 (d_model, 2048),第二个Linear则是(2048, d_model),而d_model通常是512。这样可以一定程度放大信号,提升效果。
总结流程
整个Attention之后的全部后续环节操作如下:
\[\begin{align*} X &= X + Multi\_headed\_result \\ X &= LayerNorm(X) \\ X &= X + Linear(ReLU(Linear(X)))\\ X &= LayerNorm(X) \end{align*}\]不难看出,这里 Residual Connection 和 LayerNorm 都用了两次。
官方实现
官方代码:https://nlp.seas.harvard.edu/annotated-transformer/#position-wise-feed-forward-networks
我们再看一下多头注意力机制和后续操作这整个模块:
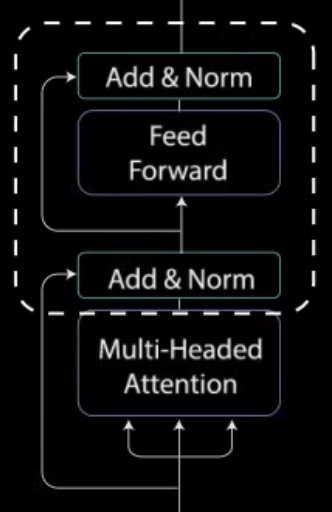
其实不难看出,开始的 Multi-Headed Attention + Add&Norm,以及后面的 Feed Forward + Add&Norm,这俩模块是一个套路,都是一个开头的 Module + 后面的 Add&Norm。因此,代码实现上可以定义一个类做这个操作,可以让代码更简洁。
官方实现上定义了一个SublayerConnection类,将 LayerNorm 和 Add Residual 操作都放在其中,然后用一个输入参数 sublayer 来切换第一个模块是 Multi-Headed Attention 或 Feed Forward.
# SublayerConnection用于封装几个相关操作:dropout, LayerNorm以及Residual Connection
class SublayerConnection(nn.Module):
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
# 注意LayerNorm只作用在最后一个维度即 d_model 维度上(实现中size=d_model)
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
# 这里定义了LayerNorm以及Add Residual的重复操作,并且输入sublayer,它可以
# 是Multi-Headed Attention,也可以是 Feed Forward,这样就避免重复实现,使代码简洁
return x + self.dropout(sublayer(self.norm(x)))
# FeedForward实现
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
# 通常中间会升维,例如d_model=512, d_ff=2048
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(self.w_1(x).relu()))
# 调用就很方便了
...
self.sublayers = Clones(SublayerConnection(size, dropout), 2)
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask)) # Multi-Headed attention
x = self.sublayer[1](x, self.feed_forward) # Feed Forward
3.7 整个 Encoder 流程的官方实现
参考:
- 具体在 Ref [6] 的 Encoder Decoder 介绍中: https://nlp.seas.harvard.edu/annotated-transformer/#encoder-and-decoder-stacks 这里就是把前面几个章节的全部代码放一起了
- 第三方实现的一个简单的 Transformer 代码,基本上就是基于官方代码 Ref [6] ,并且增加了更多的图例: https://github.com/cuicaihao/Annotated-Transformer-English-to-Chinese-Translator/blob/master/Annotated_Transformer_English_to_Chinese_Translator.ipynb
前面已经讲述了 Encoder 的全部基础模块了。从流程图可以看出,整个 Encoder 包括 N 个 EncoderLayer,每个 EncoderLayer 包括前面讲述的那些基础模块。
3.7.1 Attention 和 MultiHeaded Attention
直接照搬前面讲述过的代码即可。
def clones(module, N):
"""
Produce N identical layers.
复制N个module模块返回list of modules. 用处很多所以为了简洁定义了这个函数
"""
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
def attention(query, key, value, mask=None, dropout=None):
"""
Args:
query: size [b, n, d_model] for single head, or [b, h, n, d_q] for multi-headed
key: size [b, m, d_model] for single head, or [b, h, m, d_k] for multi-headed. d_q = d_k
value: size [b, m, d_model] for single head or [b, h, m, d_v] for multi-headed.
mask: size [b, 1, m] for src_mask, or [b, n, n] for tgt_mask
dropout: nn.Dropout, dropout layer
NOTE: Transformer 流程中有 2 Self Attentions 和 1 Cross Attention:
self-attention: Q,K,V 来源相同(都是src 或都是 tgt), 此时m=n, 且 mask 会对应 src_mask or tgt_mask
cross attention: 那么通常 Q 来自 tgt 而 K,V 来自 src, 此时 n=tgt_seq_len, m=src_seq_len, 两者通常不同,
而对应的 mask 是 src_mask
实现中的 d_q, d_k, d_v 通常是完全相等的, 且 d_q = d_k = d_v = d_model // h, h is the number of heads
例如 d_model = 512, h = 8, d_q = d_k = d_v = 64
Returns:
output: torch.Tensor, attention output, [b, n, d_model] or [b, h, n, d_v]
p_attn: torch.Tensor, attention weights (scores), size [b, n, m] or [b, h, n, m]
"""
d_k = query.size(-1)
# Q: (b,h,n,d_q), K: (b,h,m,d_k), d_q = d_k, 而 n,m 在 cross attention 时不等
# NOTE: matmul(A,B)中, 如果A,B前面1-2维度完全相同并且后两维可以支持数组相乘, 那么它的结果就是 multiplication per batch,
# 即它会认为前面两维 b,h 是 batch 然后对后两维相乘. 结果就是 (b,h,n,m)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
# NOTE: 两种情况
# 1) self attention: mask=src_mask or tgt_mask: [b, 1, n] or [b, n, n], 此时 scores都是[b, h, n, n] (n=m)
# 2) cross attention: mask=src_mask: [b,1,m], 此时 scores=[b, h, n, m]
# "masked_fill()" supports broadcasting, 所以无论哪种情况都可以运行
#
# 注意这里将等于0的位置设置为-inf即负最小值,而不是0。这是因为,此后scores要用来做softmax,其计算公式是 e^x/sum(e^x),而
# 我们期待是经过softmax后将这些invalid的位置设为0,而e^(-inf)=0,故这里设置为-inf
scores = scores.masked_fill(mask == 0, -1e9)
# 只针对最后一个维度计算 softmax
p_attn = scores.softmax(dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
# 最后和V相乘, [b,h,n,m] * [b,h,m,d_v] -> [b,h,n,d_v]
return torch.matmul(p_attn, value), p_attn
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
# h: number of heads (e.g. 8), d_model: embedding size (e.g. 512), dropout: dropout ratio (e.g. 0.1)
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h # e.g. 512 // 8 = 64
self.h = h # e.g. 8
# Clone a list of 4 Linear layers. First 3 for Q,K,V, last for the final linear output layer
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"""
Args:
query: torch.Tensor, query tensor, size [batch_size, seq_len, d_model]
key: torch.Tensor, key tensor, size [batch_size, seq_len, d_model]
value: torch.Tensor, value tensor, size [batch_size, seq_len, d_model]
mask: torch.Tensor, mask tensor to mask out certain positions, size [batch_size, seq_len, seq_len]
Returns:
output: torch.Tensor, attention output, size [batch_size, seq_len, d_model]
"""
if mask is not None:
# mask: (batch_size, 1, seq_len, seq_len), for h heads
mask = mask.unsqueeze(1)
batch_size = query.size(0)
# (batch_size, seq_len, d_model) -> (batch_size, seq_len, h, d_k)
# NOTE: 1) these two lines are equivalent to the following commented lines for each of query, key, value:
# 2) the zip(A,B) operation can align the length of A and B by taking the minimum length of the two, and
# here A,B could be either list or tuples.
query, key, value = [
lin(x).view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
for lin, x in zip(self.linears, (query, key, value))
]
"""
## Split the above lines into the following commented lines for each of query, key, value:
# (batch_size, seq_len, d_model)
query = self.linears[0](query)
# (batch_size, seq_len, h, d_k), since d_k = d_model // h
query = query.view(batch_size, -1, self.h, self.d_k)
# (batch_size, h, seq_len, d_k), since we want to compute attention on the last two dimensions, for each head
query = query.transpose(1, 2)
"""
# x: (batch_size, h, seq_len, d_k), attn: (batch_size, h, seq_len, seq_len)
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# concat results of all heads together and merge the two dimensions.
# (batch_size, h, seq_len, d_k) -> (batch_size, seq_len, d_model), since d_model = h * d_k
# What this line does is:
# 1) transpose(1, 2): Swaps dimensions 1 and 2, changing tensor from shape [batch_size, h, seq_len, d_k] to [batch_size, seq_len, h, d_k]
# 2) contiguous(): Makes the tensor contiguous in memory after transposing, which is a MUST and required for view() to work correctly,
# otherwise it will raise an error during runtime (since transpose() only changes the "viewing" shape of the tensor but not the memory
# layout, while the view() function MUST take a continuous tensor to reshape).
# 3) view(batch_size, -1, self.h * self.d_k): Reshapes the tensor to [batch_size, seq_len, d_model] where d_model = h * d_k
# The -1 automatically calculates the seq_len dimension based on the total number of elements
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.h * self.d_k)
# It might be not that necessary to release memory here, but just to be safe that they won't be used anywhere else after this.
del query, key, value
# Remember to run the last linear layer. (batch_size, seq_len, d_model) -> (batch_size, seq_len, d_model)
return self.linears[-1](x)
3.7.2 使用 SublayerConnection 实现 FirstModule + Add & Norm
此后定义 SublayerConnection instance 并在调用 forward() 时,再传入不同的 sublayer。
# SublayerConnection封装几个操作:dropout, LayerNorm以及Residual Connection
class SublayerConnection(nn.Module):
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))
# FeedForward实现
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
# 通常中间会升维,例如d_model=512, d_ff=2048
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(self.w_1(x).relu()))
3.7.2 EncoderLayer 模块以及最终的 Encoder Class
每个 Encoder Instance 中包含 N 个相同的 EncoderLayer.
class EncoderLayer(nn.Module):
"""
包括两个步骤:
1) MultiHeadedAttention -> SublayerConnection (包含 LayerNorm -> Add Residual)
2) FeedForward -> SublayerConnection (包含 LayerNorm -> Add Residual)
Dropout 层已经在 SublayerConnection 添加了, 这里只是传入 dropout ratio
"""
def __init__(self, size, self_attn, feed_forward, dropout):
# size: embedding size, 通常等于 d_model, self_attn 和 feed_forward 要提前定义好, dropout: dropout ratio
# 这里的 size 只用来传入 Encoder 中用于其 LayerNorm 的定义, 而 EncoderLayer 中则不用
super(EncoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
def forward(self, x, mask):
# x: (batch_size, seq_len, d_model)
# mask: (batch_size, 1, seq_len) or (batch_size, seq_len, seq_len)
# return: (batch_size, seq_len, d_model)
#! NOTE: 注意 SublayerConnection() 的第二个参数是关于 attention 的函数而不是数值。
#! 这是因为,从SublayerConnection.forward()函数不难看出,它的第二个参数sublayer在里面用法是
#! sublayer(.),即它应该是一个 Layer module, 因此设计成函数作为输入便可以用做 Layer module
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
# 第2步就是 FeedForward -> SublayerConnection
return self.sublayer[1](x, self.feed_forward)
class Encoder(nn.Module):
"""
这就是 Encoder 最顶层的类了, 它包含 N 个相同的 EncoderLayer, 例如 Transformer 中一个例子 N=6
"""
def __init__(self, layer, N):
# 调用时, layer 通常是提前定义好的 EncoderLayer, N的一个例子 N=6
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
# x: (batch_size, seq_len, d_model)
# mask: (batch_size, 1, seq_len) or (batch_size, seq_len, seq_len), depends on self.layers API
# return: (batch_size, seq_len, d_model)
# 输入的x,mask这个接口完全取决于EncoderLayer.forward()的定义
for layer in self.layers:
x = layer(x, mask)
# 注意整个 Encoder 结束后, 官方代码又加上了一层 Layer Norm, 不过流程图上并没有。或许是考虑到
# 接下来 Encoder 的输出会被传入到 Decoder Attention 作为输入, 因此加上 LayerNorm 使输出更稳定
return self.norm(x)
3.7.4 建立 Encoder Instance
这里是如何使用 Encoder Class 建立 Instance。注意这代码还包含了 Transformer 的其他模块,例如 Decoder, Generator 等。
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
"""
Args:
src_vocab: source vocabulary size,
tgt_vocab: target vocabulary size
N: number of repeated EncoderLayer and DecoderLayer modules,
d_model: embedding size
d_ff: feed forward layer size,
h: number of heads
dropout: dropout ratio
"""
c = copy.deepcopy
**attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
pos_embed = PositionalEncoding(d_model, dropout)**
**encoder = Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N)**
decoder = Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N)
src_embed = nn.Sequential(Embeddings(src_vocab, d_model), pos_embed)
tgt_embed = nn.Sequential(Embeddings(tgt_vocab, d_model), pos_embed)
generator = Generator(d_model, tgt_vocab)
model = Transformer(encoder, decoder, src_embed, tgt_embed, generator)
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
# Paper title: Understanding the difficulty of training deep feedforward neural networks Xavier
# 官方代码中的一个初始化方法, 还留在这不动
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
3.8 Decoder 全流程
整个 Decorder 流程如下图。
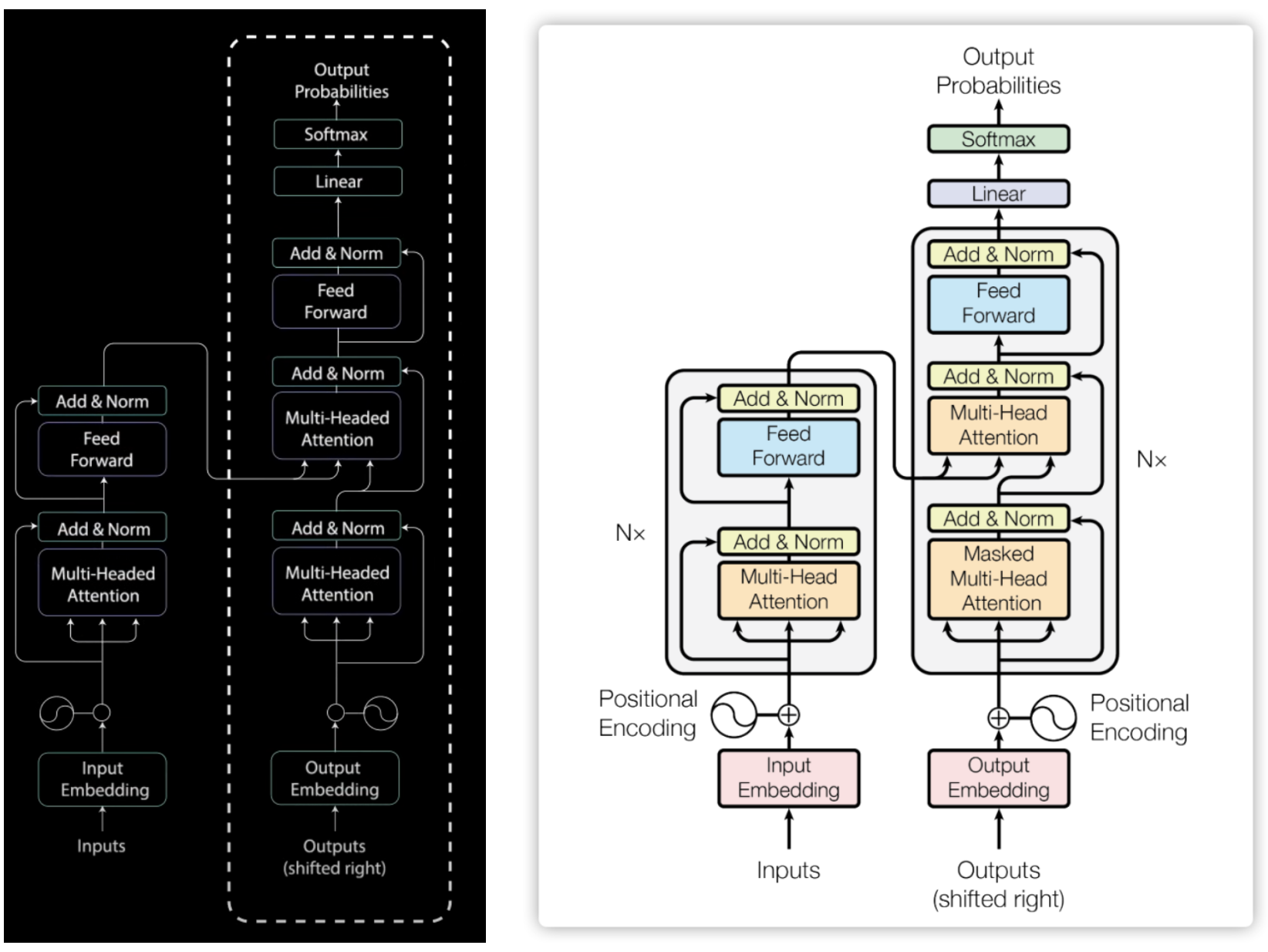
Decoder流程的特点是:
- 和Encoder类似的,Decoder的核心模块也是 Multi-Headed Attention,只是它会用多个 Attention Modules来增大网络;
- 和Encoder不同的,Decoder中间的Multi-Headed Attention模块同时引入Encoder的输出结果和Decoder前面的Output的Decode结果,用于建立 Input 和 Output 之间的关联。
- 另一点和 Encoder 不同的是,Decoder 需要 word-by-word prediction来预测下一个 token,因此它不能有 Output 这块的未来信息。它每一步会接受当前一步 Input token的 Encoder 的输出以及上一步的 Decoder 的输出,生成当前 Decoder output,即针对当前输入的预测结果。这点和 Encoder 不同,Encoder 是一次性把全部输入所有单词扔进去得到映射结果。
3.8.1 Data Preprocessing 数据预处理
这点其实和整个Transformer的 Encoder开始前的数据预处理完全相同。参见 Section 3.2。
3.8.2 First Multi-Headed Attention 第一个多头注意力模块
Decoder中的第一个多头注意力模块依然还是 Self Attention,其输入的 Q, K, V 全都来自 Decoder 最开始的输入 tgt。其结构和 Encoder 中的多头注意力模块是完全相同的,但一些细节稍有不同。因为 Decoder 是 word-by-word prediction,每次通过历史的所有单词来预测未来的一个单词,因此它不能像 Encoder 那样一次性输入整个句子,而是只能 word-by-word 输入。因此,我们在计算 Attention 中的那个 Attention Matrix(Score Matrix,即那个 $A=QK^T$ 的结果)之后 ,必须要屏蔽掉和未来信息相关的那些 scores 值。
如下面右图所示的是 Self Attention 中的 Softmax 的结果,显然划掉的那些数值是不存在的,因为它们都用到了未来信息。
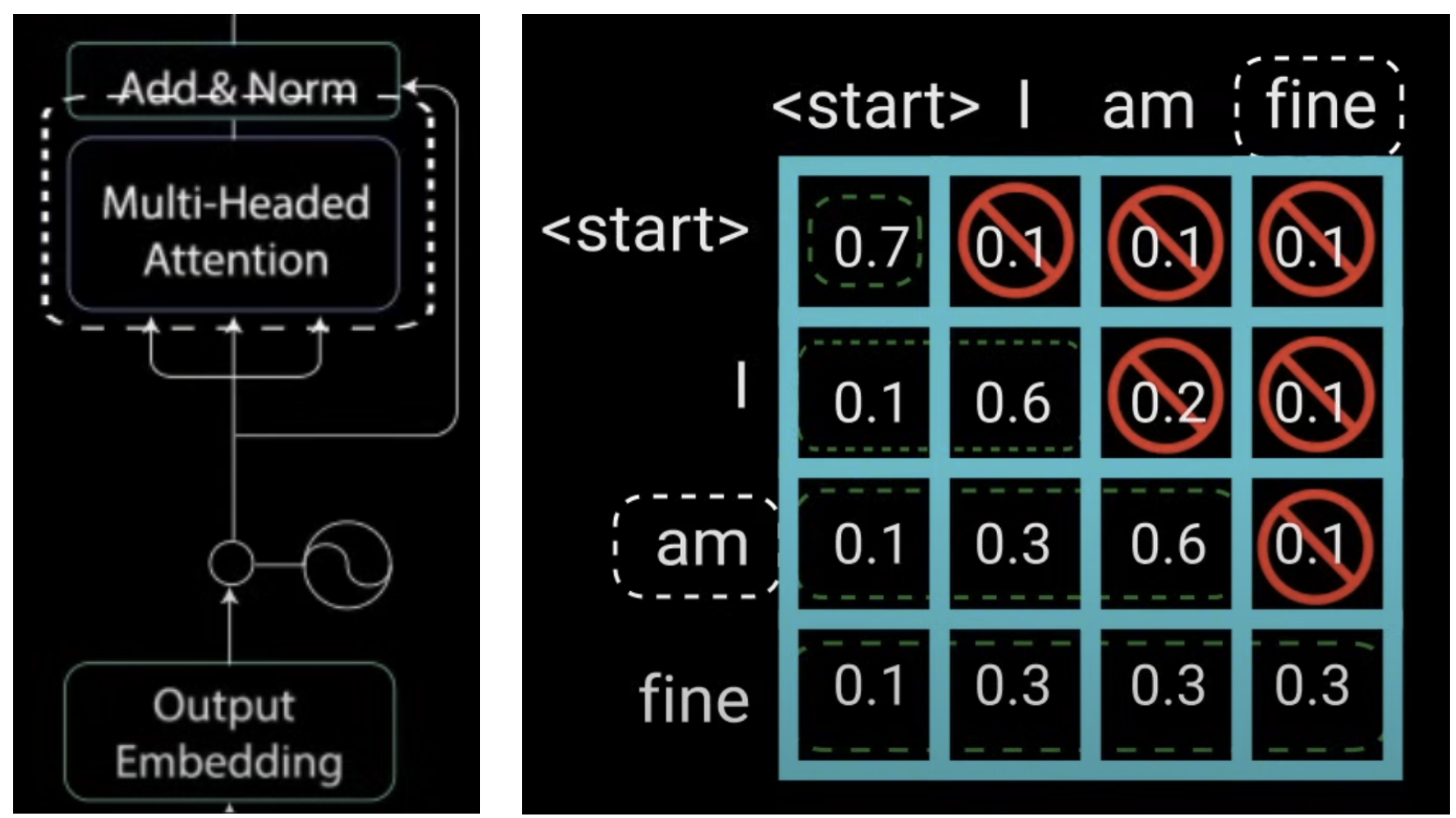
为了实现这点,作者引入了一个新的 Look-Ahead Mask,作用是将Softmax数组的右上三角部分都变成一个极小值。
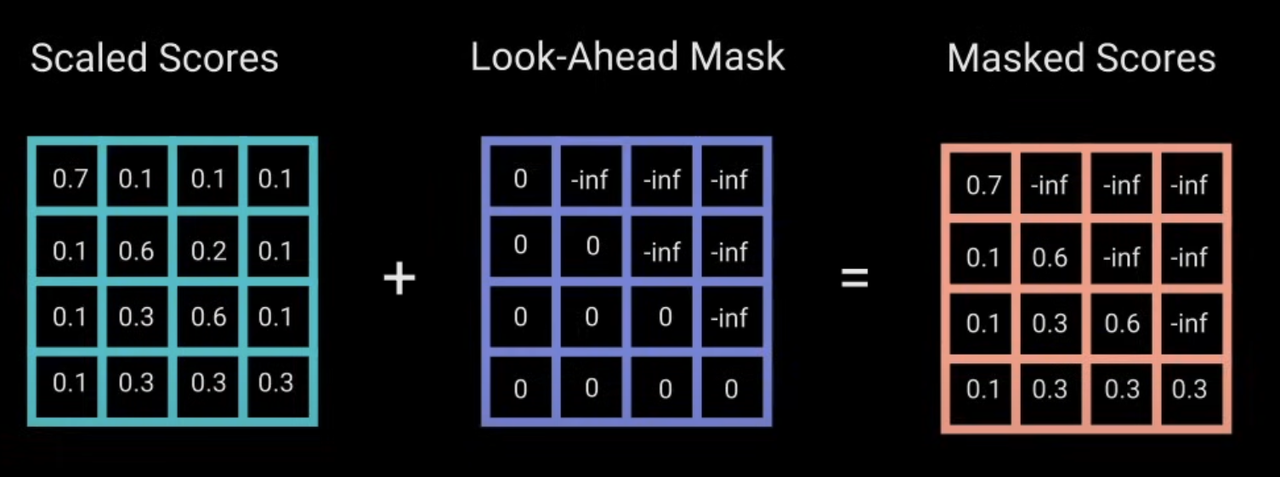
注意这里之所以是 -inf 值而不是 0。原因在前面 Encoder Attention 中讲过了,是因为接下来马上就要计算 Softmax,而 Softmax 计算公式是 $e^x/sum(e^x)$ ,而我们最终目标是 Softmax 后将这些不需要的元素变成 0,而只有 $e^{-\inf}=0$ 才成立。因此要设成极小值 -inf 才行。
再次回顾一下 Encoder 的 Attention 中的这个 mask 矩阵的设计。它的作用是屏蔽掉 scores 中的某些元素。为何需要?这是因为,我们的训练数据通常是句子 sentences,而每个句子的长度显然是不同的,而训练中的Batch则通常是一个固定大小的数组,例如 (batch_size, seq_len),其中 seq_len 是一个对于当前batch的固定值,通常设定成当前batch中全部句子的最大长度(有时也会设置成一个全局的整个数据集的最大长度)。因此,不难看出,batch中会有很多句子结束后是空的。那么如何处理?通常我们的做法是,给句子后面pad一个默认的invalid index,例如 pad 0,并把例如 id=0 认为是一个 invalid token。另外,如果一个训练集中的 word 不在 vocabulary 中,它也被认为是 invalid token 而赋予 id=0。这样的话,在计算 scores 数组时,我们想要排除掉这些 invalid token 和其他 tokens之间的关联,即将scores中的这些 invalid tokens 所对应的位置都设成0,即将这些位置mask掉。
但是,Encoder中的Attention使用的 src_mask 和 Decoder 中使用的 tgt_mask 的作用是不同的。前者只用在 Encoder’s self attention 中,而后者则是用在 Decoder’s self attention和cross attention。因为 Encoder 中我们可以看到整个数据集,因此 src_mask 只需要屏蔽掉那些 invalid token,即 id=0 的位置,包括 padding token 和不在 dictionary 中的 word id。因此它的实现非常简单:src_mask = (src != 0) 即可,其中 src 就是 (b, seq_len),它在创建时 dataset 时建立,包含的是每个单词对应的 word idx。
而 tgt_mask 则不然,因为 Decoder 中当前单词是不能看到未来信息的,因此 tgt_mask 不但要屏蔽 invalid token,还要屏蔽未来token,后者就是上面讲的 look-ahead mask 来实现的。因此 tgt_mask 最终就是相当于 src_mask 这种形式的 mask 和 look-ahead mask 的“且&”操作的结果。
代码实现时,使用 torch.triu() 函数以及相关操作来创建 tgt_mask 这个下三角阵。
#Encoder 中的src_mask的设计:很简单,只需要屏蔽invalid token即id=0的地方即可,这里通常pad=0
src_mask= (src!= pad).unsqueeze(-2)
# Decoder tgt_mask 设计
def make_std_mask(tgt: torch.Tensor, pad: int) -> torch.Tensor:
# [batch_size, 1, seq_len], all original non-zero elements are 1, and the rest 0 (by default pad=0)
# NOTE 本方法其实只是为了建立 Decoder 中使用的 tgt_mask,而它既要屏蔽invalid tokens(包括 invalid word 以及 pad,
# 而这两者对应的 id 都是 0),还要屏蔽未来的words。下面这行就是为了前者。
tgt_mask = (tgt != pad).unsqueeze(-2) # (b, 1, seq_len)
# NOTE: here the subsequent_mask() returns the look-ahead mask [1, seq_len, seq_len], with
# all lower left triangle is 1 (include diagonal) the rest 0. So how and why this "&" operation works
# on two tensors with size [batch_size, 1, seq_len] and [1, seq_len, seq_len]? The answer is that,
# pytorch will broadcast the two tensors to fit each other's size. That is, it first broadcasts the left
# tensor [batch_size, 1, seq_len] to [batch_size, seq_len, seq_len], and also broadcast the right tensor
# [1, seq_len, seq_len] to [batch_size, seq_len, seq_len], and then do the "&" operation. So the final result
# is a [batch_size, seq_len, seq_len].
# 这里 & 后面的mask就是为了屏蔽未来words,因此设置成了一个binary下三角阵,下三角部分和对角线上都是1,其余是0。两个 masks做了
# 且运算后得到最终的mask,兼顾了两种功能。
tgt_mask = tgt_mask & subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data)
return tgt_mask # (b, seq_len, seq_len)
def subsequent_mask(size):
# 计算binary下三角阵,下三角和对角线是1,其余是0
attn_shape = (1, size, size)
# triu() 生成上三角矩阵,diagnoal=1表明去掉对角线,其结果是只有右上三角是1(不包括对角线),其余是0。
# 接下来返回的是 subsequent_mask == 0,因此取反后,只有左下角和对角线是1,其余是0。
subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1).type(
torch.uint8
)
return subsequent_mask == 0
3.8.3 Cross-Attention 交叉注意力机制
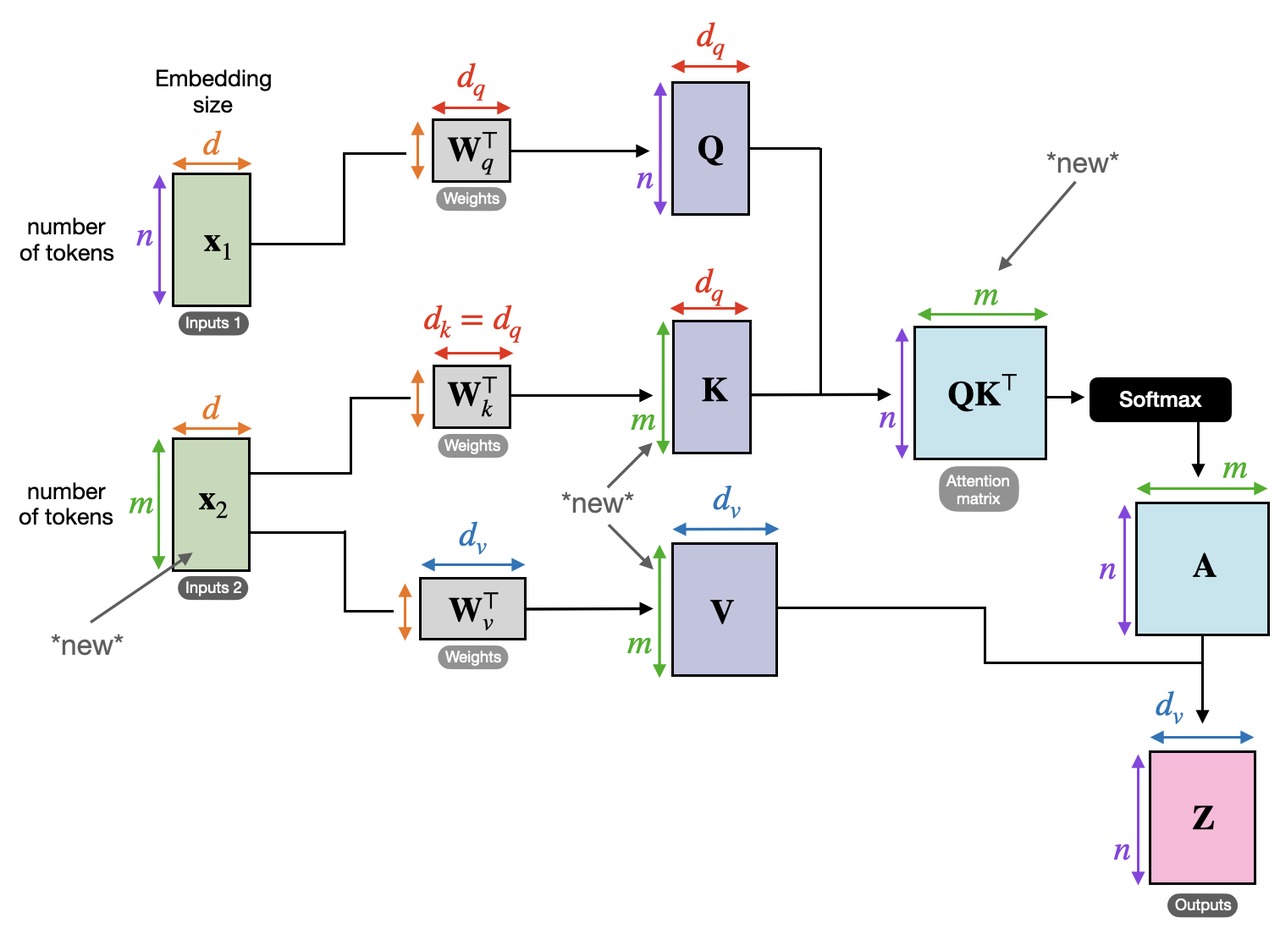
Decoder 中接下来(第二个) Attention 模块是 Cross Attention。顾名思义,它和 Self Attention 区别是,前者的输入的 QKV 会来自两个不同的来源,因此称为 Cross 交叉注意力。如下图。
流程如下图,其实它和 Self-Attention 几乎一样,区别是:
- Q, K, V 的来源有所不同。通常,Q 的来源是 target data 即 Decoder 中的输入,而 K, V 来源则是 Encoder 的输出结果(且 K, V 的来源相同,例如图中的 $x_2$)。因此两者的 number of tokens 显然可能不等。不过这其实完全不影响计算流程,所有的计算还是 Self Attention 中的计算不变,只是中间变量的 sizes 可能有所区别,例如中间的 $QK^T$和 $A$ 等数组。
- mask 的设计有所区别。上一小节已经讲了。
3.8.5 整个 Decoder 流程实现
Decoder 中的剩下的模块,即本章 Section 3.8 中剩下没讲的,其原理都和 Encoder 中的完全相同,例如 Add & Norm, Feed Forward 等。这里就不再重复了。
代码实现中,和 Encoder 类似的, Decoder 中也会设计 DecoderLayer ,然后用 Decoder Instance 包括 N 个相同的 DecoderLayer。对比 EncoderLayer 和 DecoderLayer,后者多增加了一个 Cross Attention + 后续的 Add & Norm 模块。
class DecoderLayer(nn.Module):
"""
和 EncoderLayer 类似但是会多一个步骤, 包括3个步骤:
1) MultiHeadedAttention (self attention with target data only) -> SublayerConnection (包含 LayerNorm -> Add Residual)
2) MultiHeadedAttention (cross attention, takes input both Encoder output and the last self attention output) -> SublayerConnection
3) FeedForward -> SublayerConnection
Dropout 层已经在 SublayerConnection 添加了, 这里只是传入 dropout ratio
"""
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
# size: embedding size, 通常等于 d_model
# self_attn, src_attn, feed_forward 要提前定义好, 其中 src_attn 是使用了 Encoder source data 的 attention 机制
# dropout: dropout ratio
# 类似的, 这里的 size 只用来传入 Decoder 中用于其 LayerNorm 的定义, 而 DecoderLayer 中则不用
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
# x: (batch_size, seq_len, d_model)
# memory: (batch_size, seq_len, d_model)
# src_mask: (batch_size, 1, seq_len, seq_len), tgt_mask: (batch_size, seq_len, seq_len)
# return: (batch_size, seq_len, d_model)
#! NOTE: 同样类似 Encoder 中的定义, 这里的某些 SublayerConnection() 的第二个参数是关于attention的函数而不是数值。
#! 这是为了将其作为类似一个 Layer 的形式传入
# 1) MultiHeadedAttention (self attention) -> SublayerConnection (包含 LayerNorm -> Add Residual)
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
# 2) MultiHeadedAttention (cross attention) -> SublayerConnection
x = self.sublayer[1](x, lambda x: self.src_attn(x, memory, memory, src_mask))
# 3) FeedForward -> SublayerConnection
return self.sublayer[2](x, self.feed_forward)
class Decoder(nn.Module):
"""
这就是 Decoder 最顶层的类了, 和 Encoder 很类似, 它包含 N 个相同的 DecoderLayer, 例如 N=6
"""
def __init__(self, layer, N):
# layer 通常是提前定义好的 DecoderLayer, N的一个例子 N=6
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
# x: (batch_size, seq_len, d_model), memory: (batch_size, seq_len, d_model)
# src_mask: (batch_size, seq_len, seq_len), tgt_mask: (batch_size, seq_len, seq_len)
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
# 类似 Encoder, 这里当 Decoder 结束后, 官方代码也给加上了一层 Layer Norm
return self.norm(x)
3.9 整个 Transformer 架构实现
除了前面讲述的 Encoder 和 Decoder 外,注意 Decoder 后面最后来接着一个 Linear + 一个 Softmax,这一部分合并称为 Generator。它作用很简单,将 Decoder 输出的 (b, seq_len, d_model) 数组转成最终的输出 out = (b, seq_len, vocab) 的数组。这里 vocab 就是 Target Dataset 的 vocabulary size。我们目标是预测单词,而代码实现中,预测单词是通过预测其概率值来实现的。即,对于每个单词,我们都预测整个 vocab 中的全部单词的概率,然后期待我们希望的单词对应的概率值最大,其余的值都非常小。
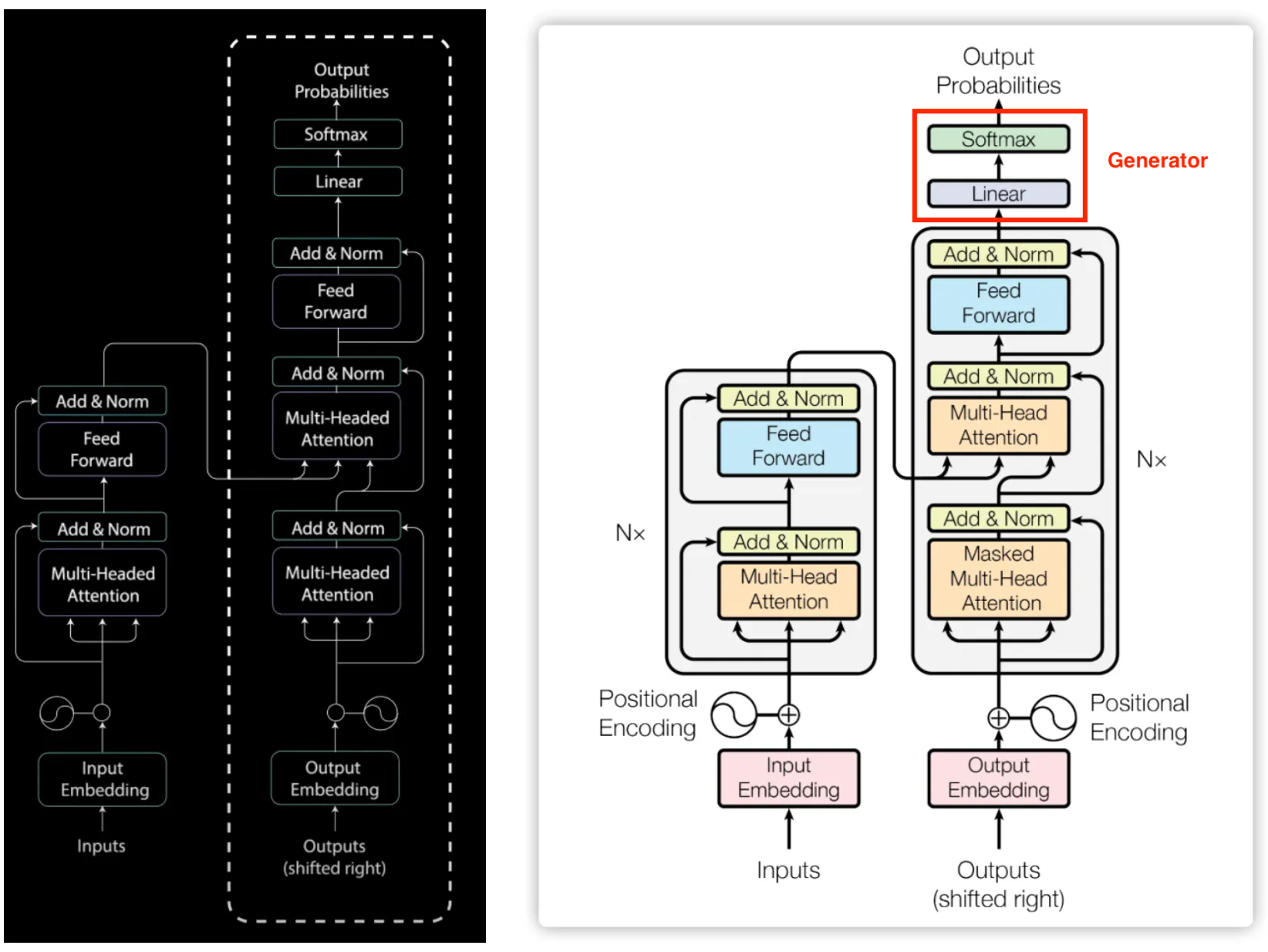
整个 Transformer 就包括了 Encoder, Decoder, Generator 这几个模块了。Generator 以及整个 Transformer Class 的代码实现:
class Generator(nn.Module):
"""
Generator 就是 Decoder 之后到最终输出的这几层, 很简单只包含 Linear -> Softmax. 其中 Linear 作用是将
最后一维的 Embedding size (d_model) 重新变为 vocab_size, 而 Softmax 则是将数值重新变成概率值
"""
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
# x: (batch_size, seq_len, d_model)
# return: (batch_size, seq_len, vocab)
# 注意最后使用了 log(softmax) 而不是 softmax
return F.log_softmax(self.proj(x), dim=-1)
class Transformer(nn.Module):
"""
Transformer 就是 Encoder + Decoder + Generator. 官方代码把这个类定义为 EncoderDecoder, 不过感觉还是直接 Transformer 更好些
另外参考的 English-Chinese Translator 代码也是如此定义的
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
# encoder, decoder, src_embed, tgt_embed, generator 都是提前定义好的. 注意:
# 1) src_embed, tgt_embed 都包括了 Word Embedding -> Positional Embedding 这两个步骤,
# 通常可以用 src_embed = nn.Sequential(Embedding, PositionalEmbedding) 这样提前定义好然后传入
# 2) generator只是传入进来但没有包含到流程中, 它会在外面显式调用, 方便操作
super(Transformer, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def encode(self, src, src_mask):
# src: (batch_size, seq_len)
# src_mask: (batch_size, 1, seq_len) or (batch_size, seq_len, seq_len)
# return: (batch_size, seq_len, d_model)
# NOTE 注意 src 是 raw word ID 数组, 因此预先要做 Embedding
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
# memory: (batch_size, seq_len, d_model), basically the Encoder result on src
# src_mask: (batch_size, 1, seq_len) or (batch_size, seq_len, seq_len)
# tgt: (batch_size, seq_len)
# tgt_mask: (batch_size, seq_len, seq_len)
# return: (batch_size, seq_len, d_model)
# NOTE 注意 tgt 也是 raw word ID 数组, 因此预先要做 Embedding
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
def forward(self, src, tgt, src_mask, tgt_mask):
# src: (batch_size, seq_len), tgt: (batch_size, seq_len)
# src_mask: (batch_size, seq_len, seq_len), tgt_mask: (batch_size, seq_len, seq_len)
# return: (batch_size, seq_len, d_model)
# 注意它只有 Encode -> Decoder 流程, 不包括 Generator, 后者会在外面显式调用
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
以及建立整个 Transformer Model Instance 的代码
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
"""
Args:
src_vocab: source vocabulary size,
tgt_vocab: target vocabulary size
N: number of repeated EncoderLayer and DecoderLayer modules,
d_model: embedding size
d_ff: feed forward layer size,
h: number of heads
dropout: dropout ratio
"""
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
pos_embed = PositionalEncoding(d_model, dropout)
encoder = Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N)
decoder = Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N)
src_embed = nn.Sequential(Embeddings(src_vocab, d_model), pos_embed)
tgt_embed = nn.Sequential(Embeddings(tgt_vocab, d_model), pos_embed)
generator = Generator(d_model, tgt_vocab)
model = Transformer(encoder, decoder, src_embed, tgt_embed, generator)
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
# Paper title: Understanding the difficulty of training deep feedforward neural networks Xavier
# 官方代码中的一个初始化方法, 还留在这不动
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
3.10 Loss 设计
3.10.1 Label Smoothing Loss
Label Smoothing 参考论文: https://arxiv.org/pdf/1512.00567
这个方法具体实现了什么呢?
我们使用 Transformer 来预测未来的每个单词,那么如何计算 Loss?常规的想法是:我们预测的是整个 vocab 单词库中所有单词的概率值,其中那个我们需要的正确的单词的概率是最大的,其余尽量最小。即,我们预测一个长度是 $y=[v]$ 的向量,假设正确的单词即 Groundtruth Word ID 的位置是 $j$ 的话,我们期待是 $v_j$ 最大,例如 1.0,其他全部位置的 $v_i$ 都尽量小,例如 0.0。这样的 y 就可以认为是一个 Groudtruth Distribution 即真实分布了。然后,用我们的网络预测值 $\hat{y}$ 和这个真实值 $y$ 对比计算 Loss 即可,例如可以用 KL Divergence 来计算两个分布之间的距离: https://docs.pytorch.org/docs/stable/generated/torch.nn.KLDivLoss.html#kldivloss
举例:例如 $v=8$ , 对应的 Groundtruth word ID index $j=3$ ,那么理想的 $y = [0,0,0,1,0,0,0,0]$
但问题是,这种理想的 y 的分布有些过于理想了,实际训练用它作为 GT 效果似乎不是很稳定,即似乎很难让预测值 $\hat{y}$ 接近它。因此,Label Smoothing 方法的作用是:生成一种经过平滑的分布 $y’$ :它的 Groundtruth word ID 这个位置的值是一个 confidence 值,通常不是1.0,而是通常稍微低于1.0,例如 0.9。而其他位置的值中,对应 PAD 单词所在的位置依然是 0, 剩下的值则是一个很小的值而不是0,通常这样计算: $s/(v-2)$ ,其中 $s$ 是 smoothing factor,它通常就等于 1 - confidence。例如这里就是 1-0.9=0.1。而分母的 $v-2$ 的目的是减去PAD和正确的位置这两个位置,确保整个分布的总和还是1.0。
例如,前面同样的例子中, 假设 PAD 所在位置是 0, $v=8$ , 那么平滑后的分布就变成了: $y’=[0.0,\ 0.0166,\ 0.0166,\ 0.9,\ 0.0166,\ 0.0166,\ 0.0166,\ 0.0166]$
经过实践验证, 这种平滑过后的 Smoothed Groundtruth distribution 更容易降低训练 loss, 提升可靠度。
class LabelSmoothing(nn.Module):
"""
Implement label smoothing regularization technique.
实现一个 smoothing distribution 来替代传统的 distribution 的比较方式. 具体见 forward() 中的记录
"""
def __init__(self, size, padding_idx, smoothing=0.0):
# size: vocabulary size 注意这个不是 d_model 了
# padding_idx: index of padding token in vocabulary, usually 0
# smoothing: smoothing parameter (epsilon), default is 0.0 (no smoothing) 通常用较小的值例如 0.1
super(LabelSmoothing,self).__init__()
# KLDivLoss expects log probabilities as input and probabilities as target
# reduction="sum" means the loss will be summed over all elements
self.criterion= nn.KLDivLoss(reduction="sum")
self.padding_idx= padding_idx
self.confidence= 1.0- smoothing # Probability assigned to correct class
self.smoothing= smoothing # Smoothing parameter (epsilon)
self.size= size # Vocabulary size
self.true_dist=None # Store distribution for visualization/debugging
def forward(self, x, target):
# x: model output logits after log_softmax, shape [b, v], where v is vocabulary size
# target: groundtruth true labels, shape [b]
# return: loss value
#NOTE: 通常 x 传入时就已经被reshape成了只有2个维度, 即类似 [b,n,v] -> [b*n,v], 故 x=[b,v] 中
# 的 b 其实指的是 batch size * seq_len. target同理, 被reshape成了只有1个维度, 类似 [b,n] -> [b*n]
# Ensure input has correct vocabulary size dimension
assert x.size(1)==self.size
# Create a copy of input tensor to build our smoothed target distribution
# [b, v]
true_dist= x.data.clone()
# Fill with small probability for all classes
# We divide by (size-2) to account for correct class and padding token
# 默认全部赋予一个非常小的值, 例如 smoothing=0.1, size=10000, 那么这个值接近 1e-5
# [b, v]
true_dist.fill_(self.smoothing/ (self.size- 2))
# Put the confidence (1-smoothing) probability on the correct class
# unsqueeze(1) converts target from [batch_size] to [batch_size, 1]
#!NOTE: self.scatter_(dim, index, src) is a very useful function, it will copy
#! the value of src to the index position of the dim dimension.
#! 它的作用是将 src 中的每个数值 src[i,j] 赋给 self 数组中的第 dim 维度下的第 index[i,j]
#! 这个位置. 即: 它只修改第 dim 维度. 例如这里, true_dist is (b, v), dim=1, index is (b,1)
#! 而 src=self.confidence 是一个 scalar 固定值. 因此, dim=1 说明修改的是 true_dist 的 v 这个
#! 维度即 vocab. 具体的话就是 true_dist[0,index[0][0]] = src, true_dist[1,index[1][0]] = src, ...
#! 而 index=target.data.unsqueeze(1) 其实就是 target word ID index.
#! 总结的话就是, 把 true_dist 的维度 dim=1 这里维度上的, index = groundtruth word ID from target 的这些
#! 位置上都赋值为 confidence 值, 例如 0.9 (剩下全部位置还是上面计算得到的一个极小值)
true_dist.scatter_(1, target.data.unsqueeze(1),self.confidence)
# Set probability for padding token to 0 将pad所在的位置全部设为0
true_dist[:,self.padding_idx]= 0
# Find positions where target is padding token
# 找到 target 中的 pad 所在的全部位置的 indices
mask= torch.nonzero(target.data==self.padding_idx)
# If padding tokens exist in target
if mask.dim()> 0:
# index_fill_(dim, index, value) 是将第dim维度中的index数组记录的位置都设置为value
# 这里就是将 true_dist 中的这些 (对应target中的) pad indices 都设为 0
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist= true_dist # 这就是新的 Smoothed Groundtruth distribution
# 计算 x 和新的 smoothed groundtruth distribution 的 KL Divergence Loss
#!NOTE: 本函数的输入x通常是Transformer整个流程的输出结果, 其最后一层是 Generator. 从它的 forward 函数定义
#! 看, 它的最后一层是 log_softmax, 即计算了 softmax 后再取了log. 即, x 的值是已经计算了log的. 不过,显然这里的
#! true_dist并没有计算log, 那么下面这个方法为何正确呢?这是因为, criterion 即 nn.KLDivLoss(input, target) 比较特别
#! 它的输入 input 已经被要求要在 log-space 了, 而 target 则默认没有被要求(有个参数可以切换 target 是否已经
#! 在这里面了)
return self.criterion(x, true_dist)
3.10.2 最终的 Loss 实现
官方实现中,将最终的 Loss 计算封装到了一个类 SimpleLossCompute 中,然后其中实现了 __call__() 函数,这样调用它的 instance 时就和普通的 Loss function 一样了。之所以封装到类中,一个原因是它的初始化时还传入了 Generator instance,即在 call() 函数中它同时运行了 generator 的推理(这个我感觉非常牵强,即其实可以将 Generator 推理放入 Transformer decode() 的推理中)。调用时,首先定义 LabelSmoothing instance,然后传入到 SimpleLossCompute Instance 中,之后调用即可。不过,因为 generator 推理也放在这边了,因此 loss call() 的传入的 x 其实是 Decoder 的输出结果(即 Generator 的输入),即 [b, seq_len, d_model] 的数组。
class SimpleLossCompute:
"""
A simple loss compute and train function based on the output of the model.
NOTE 把计算 loss 的 Criterion 给封装到一个 wrapper 中, 好处是:
1) 区分 training loss 和 evaluation loss 时的不同: 前者有 optimizer, 后者不需要.
而其他流程都相同. 故封装成 wrapper 后定义两个 instances 来使用, 使得代码简洁
2) 计算 loss 时候初始化的 generator, criterion, optimizer 都是固定值, 然后每次计算
新的输入 x,y 之间的 loss, 因此用一个wrapper类先初始化这些固定参数, 然后调用它来计算新的
(x,y) 的 loss 比较简单
"""
def __init__(self, generator, criterion, opt=None):
# generator: Generator module that projects to vocabulary size
# criterion: Loss function (typically LabelSmoothing)
# opt: Optimizer (optional, can be None for evaluation)
self.generator = generator
self.criterion = criterion
self.opt = opt
def __call__(self, x, y, norm_factor):
# x: Transformer model output tensor (batch_size, seq_len, d_model)
# y: target tensor with ground truth indices (batch_size, seq_len)
# norm_factor: normalization factor, typically the number of tokens in the batch
# return: loss value, one scalar
#! NOTE: 注意这个函数被设计为 __call__() 作用是可以将这个类的 instance 用作类似一个函数,
#! 其实就是类似 nn.Module 中的 forward() 函数, 只是这个类不是 nn.Module, 所以只能设计成
#! __call__()函数来代替. 用法也一样, 例如: 定义 sc = SimpleLossCompute(...), 然后调用
#! loss = sc(x,y,norm_factor) 就行了
# Apply final projection to vocabulary size
#! NOTE: 注意 Transformer 中的最后的 Generator 是在这里被调用的, 说实话感觉有些过于隐蔽
#! 并且结构有些奇怪, 我还是感觉放在 Transformer 类里面的 forward() 更合适.
x = self.generator(x) # (batch_size, seq_len, vocab_size)
# Reshape tensors for loss computation:
# - Flatten batch and sequence dimensions to compute loss over all tokens
# - contiguous() ensures memory layout is optimized for the view operation
# NOTE: 计算 backward loss 时候通常要除以一个 norm_factor, 通常它是 #tokens in batch
# 即计算的是 loss per token, 这是为了 stable gradient descent, 避免某些 batch 中的
# tokens 过多导致 gradients 过大, 使得其他 tokens 的 gradients 被稀释.
loss = (
# Normalize loss by token count for stable gradients during training
self.criterion(x.contiguous().view(-1, x.size(-1)), y.contiguous().view(-1))
/ norm_factor
)
# Update weights if optimizer is provided (training mode)
# NOTE: training mode 才有 opt 传入, 而 validation 的话就不用
if self.opt is not None:
# Compute gradients through backpropagation only if optimizer is provided (training mode)
loss.backward()
self.opt.step() # Apply gradients to update weights
self.opt.optimizer.zero_grad() # Reset gradients for next batch
# Return the un-normalized loss value (multiplied back by norm_factor)
# This gives the actual total loss for reporting/monitoring purposes
# while keeping gradients normalized during the backward pass
# NOTE: 最终返回的 loss 还会乘以 norm_factor, 使得最终的 loss 变回和 batch size 相关,
# 这是因为这个最终的 loss 通常会被用来统计全部 batches 的 loss 总和, 因此要用原始的 loss
return loss.item() * norm_factor
Loss Instance 的调用比较直观,参见下面代码。指的注意的是,这个 loss(x,y) 输入的 x,y 是什么?显然 x 是 Transformer 网络输出结果,而 y 则是 groundtruth。具体呢?
训练中,对于一个 Batch,我们已知:
- Training Source Dataset 全部信息。例如,如果是 English-to-Chinese translation,那么 src 就是全部 English 数据集。类似
batch.src - Target dataset 当前 t 时刻之前(从0开始)的全部历史单词信息,类似
batch.tgt[:, 0:t],即这个batch_size * t个单词。
我们最终想要预测得到的是:Target Dataset 中的当前 t 时刻的单词信息。类似 batch.tgt[:,t] 即这个 batch 个单词。
而实现中,我们通常会把要预测的值 y 设计成从时刻1开始到 t 的所有单词,即 batch.tgt[:, 1:t+1] 这样。即,它同已知的 batch.tgt[:, 0:t] 正好每个位置错开1位到将来的单词。它就是 loss(x,y) 计算时候的 y 了。这样好处是不用写一个 for loop 了。
而在随后的推理 Inference 中,我们就从这样的预测值 y 中只提取时刻 t 即最后一列单词信息即可,即 y[:, -1] 这样。
# 提前定义 Loss Instance
loss_compute = SimpleLossCompute(self.model.generator, criterion, opt=self.optimizer)
def run_epoch(self, data, loss_compute):
# data: data iterator, yield batches of data
# loss_compute: loss function and optimizer wrapper
# epoch: current epoch number
# return: loss per token
start = time.time()
total_loss = 0
tokens = 0
total_tokens = 0
batch_interval = 50
for i, batch in enumerate(data):
batch = batch.to(self.device)
out = self.model(batch.src, batch.tgt, batch.src_mask, batch.tgt_mask)
# 调用时,follow __call__() API in SimpleLossCompute(),而 tgt_y 就是提到的每个位置错开一位的 tgt[:, 1:t] 这样
loss = loss_compute(out, batch.tgt_y, batch.ntokens)
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
if i % batch_interval == 1:
elapsed = time.time() - start
print(
f" Epoch {self.current_epoch}, Batch {i}, tokens {batch.ntokens}, tokens/sec {tokens / elapsed:.3f}, loss {loss / batch.ntokens:.3f}"
)
start = time.time()
tokens = 0
# 最终返回 loss per token
return total_loss / total_tokens
3.11 推理 Inference
推理流程就是大致的常规推理流程,值得注意的几个点:
- 如上一章所讲,Generator 并未放在 Transformer 类中,而 Transformer decode() 返回的只是 Decoder 的输出(即 Generator 的输入),因此,在得到 decode() 输出后,要再显式调用 Generator 推理来输出最终的 y_pred,它是
[b, seq_len, vocab]的。而在推理中我们只需要它的最后一个单词即当前时刻 t 的单词的信息,因此就是y_pred[b, -1]这样,它是[b, vocab]大小,然后从中找到概率最大的那个位置 max_idx 对应的单词就是我们所需的最终输出了。 - 我们的推理流程是类似一个循环,每次用此前预测的全部结果 [0:t] 来预测将来时刻 t 的结果。因此,当按照上面方法预测得到时刻 t 的单词后,我们要将其加入到历史信息中,然后在这个循环中接着预测下一个单词。那么什么时候结束?实际上我们通常是设定一个 max_pred_len,其实就是 max_tokens,例如 100。这个预测循环会预测全部 100 个单词,其中肯定有 EOS 这种 label 值(我们在创建 training dataset 中加入过,用于表示每个句子的结尾)。因此,推理结束后,从这 100 个单词从左往右找,遇到 EOS 就结尾,这之前的全部的预测单词就是我们所需的整个句子的最终结果。
一个推理实现的例子。
def evaluate(self, src, pad=0, bos_id=2, max_len=50):
# src: input sentence word ID tensor, (b, src_len)
# max_len: maximum output length
# return: output sentence IDs, (b, tgt_len)
self.model.eval()
with torch.no_grad():
src = torch.from_numpy(src).to(self.device)
src_mask = (src != pad).unsqueeze(-2).to(src.device) # (b, 1, src_len)
memory = self.model.encode(src, src_mask) # (b, src_len, d_model)
# (b, 1), tgt data starts with bos_id ("BOS")
tgt = (
torch.ones(src.shape[0], 1)
.fill_(bos_id)
.type_as(src.data)
.to(src.device)
)
for t in range(max_len - 1):
tgt_mask = (
subsequent_mask(tgt.size(-1)).type_as(src.data).to(src.device)
)
# (b, tgt_len, d_model)
out = self.model.decode(memory, src_mask, tgt, tgt_mask)
# NOTE 根据我们的 decoder 设计, 输入 tgt 中的 dim=1 即 tgt_len 这个维度
# 的范围是 [0:t-1], 预测的 out 中的 tgt_len 这个维度的范围是 [1:t] (参见 Batch 中的 tgt 和 tgt_y)
# 即我们用从 0 开始到当前的 t-1 时刻的所有单词来预测未来时刻 t 的单词. 因此, 每次预测后
# 只需要位置 t 的这个新的预测值, 它正是 dim=1 这个维度的最后一个位置, 即 out[:, -1]
# (b, d_model) -> (b, vocab_size)
prob = self.model.generator(out[:, -1])
# (b), positions of max elements along dim=1
_, next_word = torch.max(prob, dim=1)
# 将新的预测值合并历史记录, 构成新的 concat (b, tgt_len) with (b, 1) to get (b, tgt_len+1)
tgt = torch.cat([tgt, next_word.unsqueeze(-1)], dim=1)
return tgt