Generative Models 2: GAN
一些 GAN 的相关材料:
- 一个 Github 链接收集了非常全的 GAN 相关的论文: https://github.com/hindupuravinash/the-gan-zooo
- 收集了很多很有意思的 GAN 应用:Awesome Applications of GAN: https://github.com/nashory/gans-awesome-applications
- 一个浏览器上在线使用 GAN 的网站:https://reiinakano.github.io/gan-playground。它还支持自定义修改 layers 等奇特操作,调用的是你本地机器的 CPU 或者 GPU。支持 MNIST 和 CIFAR10 数据集。
1. 背景和初衷 Intuitive
参考:
- 博客教程:https://towardsdatascience.com/gans-n-roses-c6652d513260。解释比较表面,给出了大致的框架和一些例子,不过没有最重要的数学原理部分。
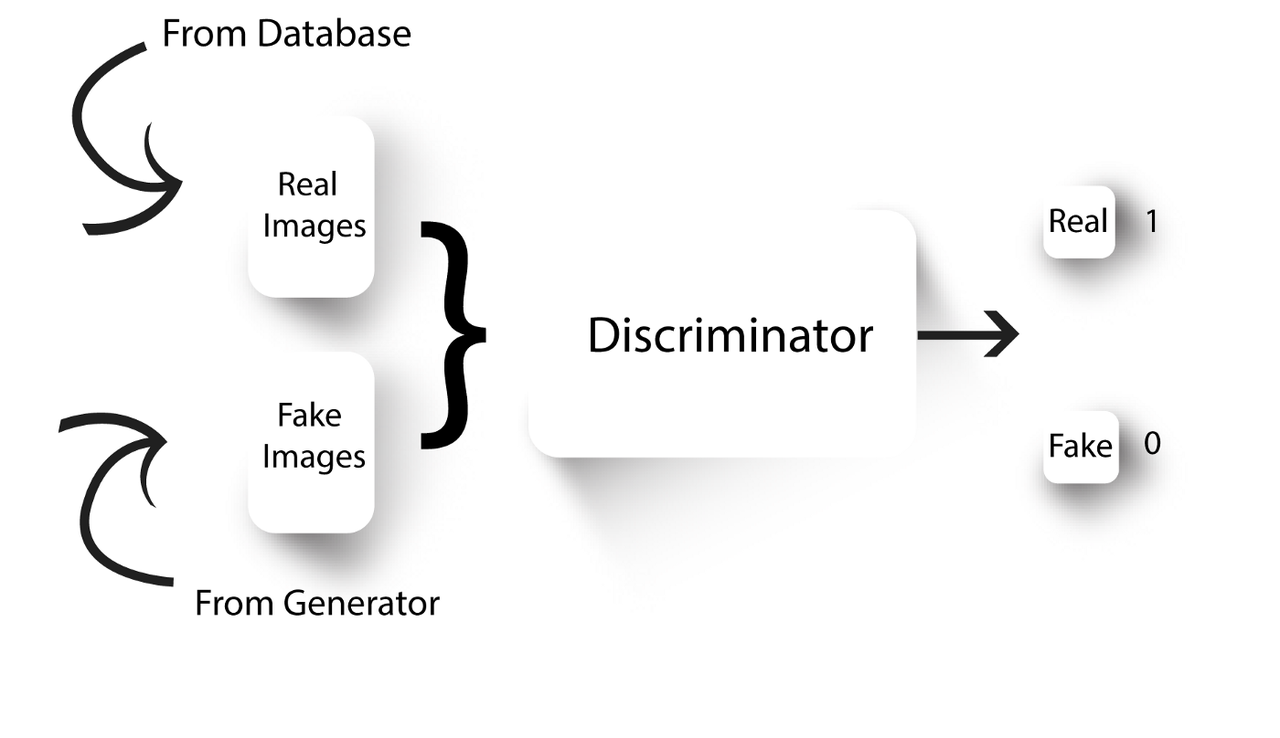
GAN 的核心原理是设计了一个类似 two-players game 的流程,它包含了一个 Generator 生成器以及一个 Discriminator 判别器:
- Generator 的作用是尽可能的生成和原始数据一样真实的数据,用来尽可能“欺骗” Discriminator;
- Discriminator 的作用是尽可能正确的区分原始数据和 generator 生成的数据,即它会把原始数据尽可能判定为真实的,同时把生成器的数据尽可能判定为虚假的。

在 GAN 的流程中,Generator 和 Discriminator 是被交替训练的,这样就会不断提升两者的性能。最终结果就是期待 Generator 能够生成以假乱真的结果,即连 Discriminator 都很难区分的结果。
Generator 的设计和 AutoEncoders 中的 Decoder 几乎是一致的。

2. GAN 原理和推导
参考:
- GAN 原论文:https://arxiv.org/pdf/1406.2661.pdf
- 中文博客:GAN 原理及公式推导: https://www.cnblogs.com/jins-note/p/10848248.html。类似 From GAN to WGAN 的中文版。
- Stanford CS231n 视频教程:https://www.youtube.com/watch?v=5WoItGTWV54&t=1592s
从数学上看,前面第 3 章已经介绍了,FVBN 和 VAE 都在尝试优化 explicit density function。而 GAN 的出发点并不相同,它并不去定义任何 density function,而是通过一个类似于 2-player game 的形式来尝试直接从 random noise 作为输入来重建出 training data。

回顾前面的 GAN 思想:从 some latent code or Random Noise z 出发,首先训练 Generator 生成 fake data。然后训练一个 Discriminator 分类器来判断 fake data 分类是 Fake,另外 Groundtruth data $x$ 分类是 True。
因此,GAN 想要最小化一个目标函数如下图:

目标函数包含了针对分类器和生成器的两个不同需求:
- 对于分类器 Discriminator,它应当最大化真实值的分类结果即 D(x) 接近 1(即True),并且最小化从生成器得到的虚假结果的分类即 D(G(z)) 接近 0,即将真实数据判断为真实,虚假数据判断为虚假。这样才是好的分类器;
- 对于生成器 Generator,正好反过来,应当最大化虚假数据的分类结果即 D(G(z)) 接近于 1。即努力将虚假数据被分类器判断为真实,因为GAN生成器的最终目标就是生成非常真实的、无法被分类器判断出来的结果(误导分类器)。
因此,标准的GAN流程是交替训练jointly train 生成器和分类器的:
- 首先训练分类器,最大化两个 E(log(.)) 项相加,如下图;
- 接着交换目标函数,最大化只有生成器的那一项,如下图。

但是这样训练有个很大问题是:交替训练的话非常难收敛!图中右下角的曲线图是生成器那个函数 $\min \log(1-D(G(z)))$ 的曲线图,这里将 $D(G(z))$ 看做横坐标的变量。可以看出,当 D(G(z)) 较小的时候,它的梯度非常小,而当它数值较大时才会梯度变大。因此,当 z 是那种完全 Fake 的数据例如纯 noise 时,训练生成器显然非常慢,仅当 z 比较接近真实值的时候才会速度变快。而 z 通常直接就是 noise,不可能是接近真实值的。
于是,一个改进方法是,将此前的目标函数 $\min \log(1-D(G(z)))$ 变为最大化 $\max \log(D(G(z)))$ 。这看似没变化,但其实梯度变化很明显。如下图右下角。当 z 接近纯噪声即 D(G(z)) 较小时,它对应的目标函数的梯度很大。这样就使得收敛速度明显变快了。

总结一下,GAN的训练流程和目标函数分别是:

其中,k的选择不一定,有些是直接就1步,有些可以很多。当整个流程训练结束后,只需要用Generator来生成最终数据即可。
3. 代码实现
参考:
- https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/gan/gan.py:一个非常简单的 GAN 代码实现。该网站还有各种各样的 GAN 模型的实现,每个方法都非常简单,基本都是单一文件实现了整个方法,非常适合初学者。
- 官方教程:DCGAN Tutorial - PyTorch Tutorials 1.10.1+cu102 documentation。强烈推荐。每一部分也有非常好的贴合代码的解释。它使用了 Celeb 图片数据库。虽然它是 DCGAN,不过 DCGAN 和 GAN 的流程和 loss 都是完全一致的。
- 大神总结的GAN 相关的非常多的代码的合集:https://github.com/eriklindernoren/PyTorch-GAN。包括几乎所有常见的 GAN 类型。每个代码写的都很简单直观,很适合初学者。例如 GAN 这个代码: PyTorch-GAN/gan.py at master · eriklindernoren/PyTorch-GAN
- Welcome to the UvA Deep Learning Tutorials! ‒ UvA DL Notebooks v1.1 documentation。这个其实是 University of Amsterdam 的 Deep Learning Course 的教材。内容详细充实,也被收录到了 pytorch lighting 的教程网站中:PyTorch Lightning ‒ PyTorch Lightning 1.6.0dev documentation。pytorch lighting 是一个 Pytorch research framework,它封装整合了多个训练相关的模块,使得用户可以更快捷的开发深度学习代码。官网:https://www.pytorchlightning.ai/
3.1 技巧
根据GAN的流程其实不难看出:
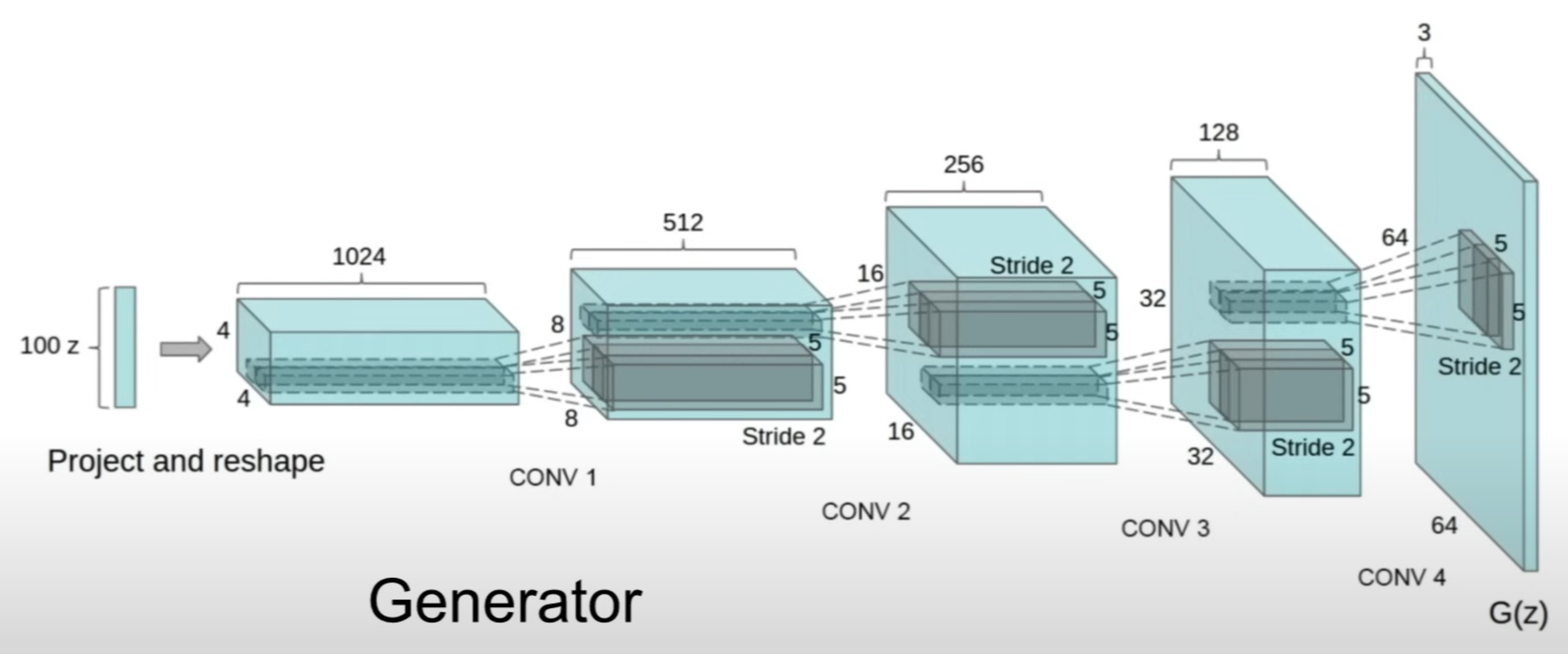
- 通常 Generator 就是一些 upsampling modules 例如使用 fractionally-strided convolutions(就是Transposed Convolutions即Deconvolutions),即通过设计好stride等参数的卷积层来增维。
- 而 Discriminator 通常就是一些标准的 Convolutions 足够。

这里是一个生成器样例:
3.2 代码流程
这里就以这个简单代码为例:https://github.com/eriklindernoren/PyTorch-GAN/blob/master/implementations/gan/gan.py。该网站有各种 GAN 相关的方法代码实现。该网站实现了各种各样的 GAN 方法,且每个方法都非常简单,基本都是单一文件实现了整个方法,非常适合初学者。
(1)Generator 生成器
- 代码中就使用了 z = (image.size(0), latent_dim) 这种[0,1]之间的噪声作为初始噪声。latent_dim默认是100
- 整个Generator就是 4 个 Linear + BatchNorm1d + LeakyReLU 的模块,最后接一个 Linear,最终将输出维度设为 image_shape 中三个维度 CxHxW 的乘积(这之后再 reshape 成 image shape)
img_shape = (opt.channels, opt.img_size, opt.img_size)
...
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
....
# 这是老代码了,新代码可以直接用 real_imgs = torch.from_numpy(imgs) 即可,并且默认就是requires_grad=True。
# 或者 real_imgs = torch.tensor(imgs, requires_grad=True) 这样可以设置是否需要计算梯度。
real_imgs = Variable(imgs.type(Tensor))
...
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
(2)Discriminator 分类器
- 分类器的输入就是也是很简单的几层 Linear + LeakyReLU 的形式,最终输出只有一个单值 scalar。当然最后面肯定要接上 Sigmoid,将最终输出定在 [0,1] 之间。
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
#先拉平输入image,然后进入Linear
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
(3)训练最终 Loss
因为是交替训练,因此Loss 包括两类:
- 生成器:就一个 loss,即分类器使用针对生成器的结果作为输入,其输出要非常真实,即和 1 比较的 loss 最小;
- 分类器:包括两个部分:
- 使用生成器的结果作为输入,其输出是假的,即和 0 之间的loss最小;
- 使用真实数据作为输入,其输出是真的,即和 1 之间的loss最小。
最终 loss是两个部分相加。
...
# Adversarial ground truths
# imgs维度是(bz,C,H,W), 因此valid,fake都是(bz,1)
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
...
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
...
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(real_imgs), valid)
# 注意这里要用 detach(),目的是在训练分类器时,要阻止梯度向后传递到生成器(stop gradients from flowing back through the generator when training the discriminator)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
代码注意:
- 使用 BCELoss 来计算分类器的输出和对应的 valid(噪声输入就是0,真实图片输入则是1)之间的 Loss。
- 注意:计算分类器使用生成器的结果作为输入的 loss 即 fake_loss 时,使用了
gen_imgs.detach()。这是因为 gen_imgs 是来自生成器生成的。它显然会有梯度可以回溯到生成器。而训练分类器时显然我们要锁住生成器不训练,因此这里要阻止梯度从 gen_imgs 向后传递到生成器。而上面 real_imgs 则不需要用 detach(),因为显然它和生成器不相连。注意这个细节很关键,如果不用则会同时训练生成器和分类器,显然错误。 - 最后的生成器最终 d_loss 是两个 real_loss + fake_loss 的一半。